
最近在研究视频动作识别,看了不少的相关算法,主要有基于MMDetection框架下的一些列的研究,有直接对视频进行识别,获取人为动作,比如slowfast等等,但是往往也有一定的局限性,而我一直做的是围绕骨骼点的相关开发,当初也使用骨骼的方法,但是效果不佳,最近看到一篇新出来的基于骨骼信息的视频动作识别,PoseC3D算法,因此比较感兴趣,这里给出了论文地址和开源的代码地址。
论文地址:https://arxiv.org/abs/2104.13586
代码地址:https://github.com/kennymckormick/pyskl
这里,我没有写自己对该文章的理解,后面我有时间会继续补充,我就先记录一下使用该算法如何训练自己的数据集。
一、环境配置
要配置该算法的环境,最好先配置好MMDetection的环境,根据官网给的安装教程,还是比较简单的。这里要注意安装mmcv、mmcv-full、mmdet和mmpose,版本不能太高,如果安装了最新的版本会报无法编译,这里我就给出直接的安装版本,
mmcv=1.3.18,mmcv-full=1.3.18, mmdet=2.23.0, mmpose=0.24.0
这里还提醒一下,安装MMDetection的时候,最好也把Detectron2也装一下,使用官网的命令行安装就可以了,这里贴一下安装命令。
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
这样在使用下面的命令安装和编译就没有问题了。
git clone https://github.com/kennymckormick/pyskl.git
cd pyskl
# Please first install pytorch according to instructions on the official website: https://pytorch.org/get-started/locally/. Please use pytorch with version smaller than 1.11.0 and larger (or equal) than 1.5.0
pip install -r requirements.txt
pip install -e .
环境配置完,最好跑一下提供的demo。
python demo/demo_skeleton.py demo/ntu_sample.avi demo/demo.mp4
输出了视频结果,那么就Ok了。
二、数据准备
官网给了一份训练自己数据的格式文档和数据制作代码,根据代码可以知道,首先需要准备各个动作的视频和标签,我准备的格式如下:
pyskl_data:
train_lable_list.txt
val_lable_list.txt
----train
A1.mp4
B1.mp4
......
----val
A2.mp4
B2.mp4
......
我先将每个视频的命名方式修改为“名称+标签”,这样后面在生成list.txt的时候,只要读取最后一位就可以知道其类别。分别生成了train_label_list.txt和val_label_list.txt,这样就可以运行制作数据代码。在运行之前,我修改了源代码,我将各个需要的模型和配置文档下载下来,同时我把分布式运行给注释了,要不然会报错,报错我后面会贴出来,当然如果使用分布式运行,那最好好好确认一下自己服务器的环境是否配置好,否则会浪费很多时间。我修改的代码如下:
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import os.path as osp
import pdb
import decord
import mmcv
import numpy as np
import torch.distributed as dist
from mmcv.runner import get_dist_info, init_dist
from tqdm import tqdm
from pyskl.smp import mrlines
try:
import mmdet
from mmdet.apis import inference_detector, init_detector
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_detector` and '
'`init_detector` form `mmdet.apis`. These apis are '
'required in this script! ')
try:
import mmpose
from mmpose.apis import inference_top_down_pose_model, init_pose_model
except (ImportError, ModuleNotFoundError):
raise ImportError('Failed to import `inference_top_down_pose_model` and '
'`init_pose_model` form `mmpose.apis`. These apis are '
'required in this script! ')
default_mmdet_root = osp.dirname(mmdet.__path__[0])
default_mmpose_root = osp.dirname(mmpose.__path__[0])
def extract_frame(video_path):
vid = decord.VideoReader(video_path)
return [x.asnumpy() for x in vid]
def detection_inference(model, frames):
results = []
for frame in frames:
result = inference_detector(model, frame)
results.append(result)
return results
def pose_inference(model, frames, det_results):
assert len(frames) == len(det_results)
total_frames = len(frames)
num_person = max([len(x) for x in det_results])
kp = np.zeros((num_person, total_frames, 17, 3), dtype=np.float32)
for i, (f, d) in enumerate(zip(frames, det_results)):
# Align input format
d = [dict(bbox=x) for x in list(d)]
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
for j, item in enumerate(pose):
kp[j, i] = item['keypoints']
return kp
def parse_args():
parser = argparse.ArgumentParser(
description='Generate 2D pose annotations for a custom video dataset')
# * Both mmdet and mmpose should be installed from source
parser.add_argument('--mmdet-root', type=str, default=default_mmdet_root)
parser.add_argument('--mmpose-root', type=str, default=default_mmpose_root)
parser.add_argument('--det-config', type=str, default='demo/faster_rcnn_r50_fpn_2x_coco.py')
parser.add_argument('--det-ckpt', type=str, default='weights/faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth')
parser.add_argument('--pose-config', type=str, default='demo/hrnet_w32_coco_256x192.py')
parser.add_argument('--pose-ckpt', type=str, default='weights/hrnet_w32_coco_256x192-c78dce93_20200708.pth')
# * Only det boxes with score larger than det_score_thr will be kept
parser.add_argument('--det-score-thr', type=float, default=0.7)
# * Only det boxes with large enough sizes will be kept,
parser.add_argument('--det-area-thr', type=float, default=1600)
# * Accepted formats for each line in video_list are:
# * 1. "xxx.mp4" ('label' is missing, the dataset can be used for inference, but not training)
# * 2. "xxx.mp4 label" ('label' is an integer (category index),
# * the result can be used for both training & testing)
# * All lines should take the same format.
parser.add_argument('--video-list', type=str, help='the list of source videos')
# * out should ends with '.pkl'
parser.add_argument('--out', type=str, help='output pickle name')
parser.add_argument('--tmpdir', type=str, default='tmp')
parser.add_argument('--local_rank', type=int, default=1)
args = parser.parse_args()
# pdb.set_trace()
# if 'RANK' not in os.environ:
# os.environ['RANK'] = str(args.local_rank)
# os.environ['WORLD_SIZE'] = str(1)
# os.environ['MASTER_ADDR'] = 'localhost'
# os.environ['MASTER_PORT'] = '12345'
args = parser.parse_args()
return args
def main():
args = parse_args()
assert args.out.endswith('.pkl')
lines = mrlines(args.video_list)
lines = [x.split() for x in lines]
# * We set 'frame_dir' as the base name (w/o. suffix) of each video
assert len(lines[0]) in [1, 2]
if len(lines[0]) == 1:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0]) for x in lines]
else:
annos = [dict(frame_dir=osp.basename(x[0]).split('.')[0], filename=x[0], label=int(x[1])) for x in lines]
rank=0 #添加该
world_size=1#添加
# init_dist('pytorch', backend='nccl')
# rank, world_size = get_dist_info()
#
# if rank == 0:
# os.makedirs(args.tmpdir, exist_ok=True)
# dist.barrier()
my_part = annos
# my_part = annos[rank::world_size]
print("from det_model")
det_model = init_detector(args.det_config, args.det_ckpt, 'cuda')
assert det_model.CLASSES[0] == 'person', 'A detector trained on COCO is required'
print("from pose_model")
pose_model = init_pose_model(args.pose_config, args.pose_ckpt, 'cuda')
n=0
for anno in tqdm(my_part):
frames = extract_frame(anno['filename'])
print("anno['filename",anno['filename'])
det_results = detection_inference(det_model, frames)
# * Get detection results for human
det_results = [x[0] for x in det_results]
for i, res in enumerate(det_results):
# * filter boxes with small scores
res = res[res[:, 4] >= args.det_score_thr]
# * filter boxes with small areas
box_areas = (res[:, 3] - res[:, 1]) * (res[:, 2] - res[:, 0])
assert np.all(box_areas >= 0)
res = res[box_areas >= args.det_area_thr]
det_results[i] = res
pose_results = pose_inference(pose_model, frames, det_results)
shape = frames[0].shape[:2]
anno['img_shape'] = anno['original_shape'] = shape
anno['total_frames'] = len(frames)
anno['num_person_raw'] = pose_results.shape[0]
anno['keypoint'] = pose_results[..., :2].astype(np.float16)
anno['keypoint_score'] = pose_results[..., 2].astype(np.float16)
anno.pop('filename')
mmcv.dump(my_part, osp.join(args.tmpdir, f'part_{rank}.pkl'))
# dist.barrier()
if rank == 0:
parts = [mmcv.load(osp.join(args.tmpdir, f'part_{i}.pkl')) for i in range(world_size)]
rem = len(annos) % world_size
if rem:
for i in range(rem, world_size):
parts[i].append(None)
ordered_results = []
for res in zip(*parts):
ordered_results.extend(list(res))
ordered_results = ordered_results[:len(annos)]
mmcv.dump(ordered_results, args.out)
if __name__ == '__main__':
main()
我这里修改一些代码,首先是将下面的代码注释了
# if 'RANK' not in os.environ:
# os.environ['RANK'] = str(args.local_rank)
# os.environ['WORLD_SIZE'] = str(1)
# os.environ['MASTER_ADDR'] = 'localhost'
# os.environ['MASTER_PORT'] = '12345'
问题1:keyError:"RANK”

追踪问题发现,代码中后面用的是"RANK",而环境赋值的是"LOCAL_RANK",而我的系统环境中也没有"RANK",因此我就将"LOCAL_RANK"修改为"RANK".
问题2:environment variable WORD_SIZE
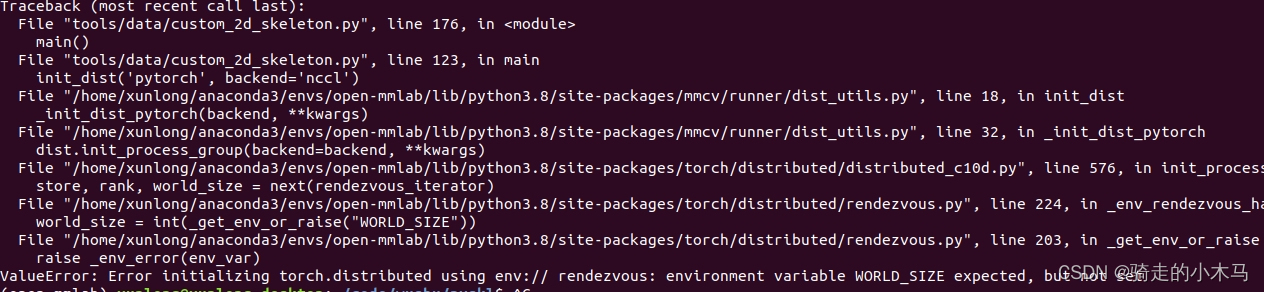
查看系统环境,同样没有"WORLD_SIZE",我也就给其赋值了,后来运行报错没有"MASTER_ADDR"和"MASTER_PORT",因此我都分别赋值,复制结果如上面注释,虽然运行不报错,但是在模型构建的时候卡住了,😔····
最后,发现其实是分布式运行的问题,所以我就想我不用分布式了,就把相关的部分都注释点
# init_dist('pytorch', backend='nccl')
# rank, world_size = get_dist_info()
# if rank == 0:
# os.makedirs(args.tmpdir, exist_ok=True)
# dist.barrier()
后面还有一个dist.barrier()也注释调
在项目下运行:
python tools/data/custom_2d_skeleton.py --video-list /pyskl/data/train_lable_list.txt --out train.pkl
OK了,终于运行成功了,下一步就是训练自己的数据集了。
其实官网的目标检测的结果不是很准确,效果也不能满足自己的需求,下一步想自己训练出一个符合自己的目标检测算法,好了,以上就是自己的训练的感受了,有不对的地方,希望给与指点。
刚开心一下,没想到又出问题,哎····
问题3:too many indices for array: array is 1-dimensional, but 2 were indexed
Traceback (most recent call last):
File "tools/data/custom_2d_skeleton.py", line 220, in <module>
main()
File "tools/data/custom_2d_skeleton.py", line 192, in main
pose_results = pose_inference(pose_model, frames, det_results)
File "tools/data/custom_2d_skeleton.py", line 70, in pose_inference
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
File "/home/xunlong/anaconda3/envs/open-mmlab/lib/python3.8/site-packages/mmpose/apis/inference.py", line 388, in inference_top_down_pose_model
bboxes_xywh = _xyxy2xywh(bboxes)
File "/home/xunlong/anaconda3/envs/open-mmlab/lib/python3.8/site-packages/mmpose/apis/inference.py", line 62, in _xyxy2xywh
bbox_xywh[:, 2] = bbox_xywh[:, 2] - bbox_xywh[:, 0] + 1
IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed
查了很久,然后输出每一个步骤,发现是pose_inference函数有问题,出现没有想到的问题,
在对bbox进行处理的时候,原先是15的二维数组,但是有时候是15的一维数组,因此一直报错,所以在函数下面添加了一行代码,如下,这样就OK了。
def pose_inference(model, frames, det_results):
assert len(frames) == len(det_results)
total_frames = len(frames)
num_person = max([len(x) for x in det_results])
kp = np.zeros((num_person, total_frames, 17, 3), dtype=np.float32)
for i, (f, d) in enumerate(zip(frames, det_results)):
# Align input format
d=d.shape(1,5)#添加该行代码,否则有可能出现1维的数组
d = [dict(bbox=x) for x in list(d)]
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
for j, item in enumerate(pose):
kp[j, i] = item['keypoints']
return kp
现在还不能拿来直接训练,还需要修改,因为根据config文件和官网给的例子,可以看到训练是一个.pkl文件,因此我把所有的数据集放在一起,先通过上面跑出来一个annotations文件video_annos.pkl,然后跟下例子的提示,如下。
split['train'] = [x['vid_name'] for x in train]
split['test'] = [x['vid_name'] for x in test]
dump(dict(split=split, annotations=annotations), 'diving48_hrnet.pkl')
可知数据集是通过字典split存储了训练集和验证集的名字,因此我也需要该啊,如果你是根据官网的例子走,那就不用我我下面的代码了。
from mmcv import load, dump
from pyskl.smp import *
split={"train":[],"test":[]}
train_path='/media/xunlong/data/raw3/train'
val_path='/media/xunlong/data/raw3/val'
train_list=os.listdir(train_path)
val_list=os.listdir(val_path)
annotations = load('/data/video_annos.pkl')
#split['train'] = [x for x in train_list]
#split['val'] = [x for x in val_list]
split['train'] = [x.split('.')[0] for x in train_list]
split['val'] = [x.split('.')[0] for x in val_list]
dump(dict(split=split, annotations=annotations), '/data/video_hrnet.pkl')
这里要注意了啊,split字典的名称不是随便定义的,根据PoseDataset的要求以及你选择的config文件去命名,我刚开始就遇到坑了啊。
split (str | None): The dataset split used. For UCF101 and HMDB51, allowed choices are 'train1', 'test1',
'train2', 'test2', 'train3', 'test3'. For NTURGB+D, allowed choices are 'xsub_train', 'xsub_val',
'xview_train', 'xview_val'. For NTURGB+D 120, allowed choices are 'xsub_train', 'xsub_val', 'xset_train',
'xset_val'. For FineGYM, allowed choices are 'train', 'val'. Default: None.
OK了,生成了最后的video_hrnet.pkl了,现在就可以去训练了
bash tools/dist_train.sh configs/posec3d/c3d_light_gym/joint.py 1
训练过程:
2022-05-27 16:05:24,715 - pyskl - INFO - Saving checkpoint at 1 epochs
2022-05-27 16:05:30,413 - pyskl - INFO - Saving checkpoint at 2 epochs
2022-05-27 16:05:36,042 - pyskl - INFO - Saving checkpoint at 3 epochs
2022-05-27 16:05:41,636 - pyskl - INFO - Saving checkpoint at 4 epochs
2022-05-27 16:05:47,263 - pyskl - INFO - Saving checkpoint at 5 epochs
2022-05-27 16:05:52,876 - pyskl - INFO - Saving checkpoint at 6 epochs
2022-05-27 16:05:58,545 - pyskl - INFO - Saving checkpoint at 7 epochs
2022-05-27 16:06:04,183 - pyskl - INFO - Saving checkpoint at 8 epochs
2022-05-27 16:06:09,898 - pyskl - INFO - Saving checkpoint at 9 epochs
2022-05-27 16:06:15,593 - pyskl - INFO - Saving checkpoint at 10 epochs
2022-05-27 16:06:21,242 - pyskl - INFO - Saving checkpoint at 11 epochs
2022-05-27 16:06:26,888 - pyskl - INFO - Saving checkpoint at 12 epochs
2022-05-27 16:06:32,510 - pyskl - INFO - Saving checkpoint at 13 epochs
2022-05-27 16:06:38,342 - pyskl - INFO - Saving checkpoint at 14 epochs
2022-05-27 16:06:44,053 - pyskl - INFO - Saving checkpoint at 15 epochs
不知道为什么看不到loss变化,我后面还要修改点代码,看到loss等参数。哎,后来发现是我数据有问题,在最后一步生成hrnet.pkl文件时,每个视频的“frame_dir”只是视频的名字,因此修改一下就可以了,最后的训练过程如下:
2022-05-29 22:02:04,167 - pyskl - INFO - workflow: [('train', 1)], max: 24 epochs
2022-05-29 22:02:04,167 - pyskl - INFO - Checkpoints will be saved to /home/xunlong/code/wushu/pyskl/work_dirs/posec3d/c3d_light_gym/limb by HardDiskBackend.
2022-05-29 22:02:21,473 - mmcv - INFO - Reducer buckets have been rebuilt in this iteration.
2022-05-29 22:02:30,032 - pyskl - INFO - Epoch [1][20/5028] lr: 4.000e-01, eta: 1 day, 19:20:27, time: 1.293, data_time: 1.073, memory: 3435, top1_acc: 0.0125, top5_acc: 0.1109, loss_cls: 4.5864, loss: 4.5864, grad_norm: 1.4527
2022-05-29 22:02:40,369 - pyskl - INFO - Epoch [1][40/5028] lr: 4.000e-01, eta: 1 day, 6:19:36, time: 0.517, data_time: 0.305, memory: 3435, top1_acc: 0.0375, top5_acc: 0.1516, loss_cls: 4.2086, loss: 4.2086, grad_norm: 0.6920
2022-05-29 22:02:50,544 - pyskl - INFO - Epoch [1][60/5028] lr: 4.000e-01, eta: 1 day, 1:53:44, time: 0.509, data_time: 0.295, memory: 3435, top1_acc: 0.0359, top5_acc: 0.1406, loss_cls: 3.9921, loss: 3.9921, grad_norm: 0.6598
2022-05-29 22:03:00,758 - pyskl - INFO - Epoch [1][80/5028] lr: 4.000e-01, eta: 23:41:43, time: 0.511, data_time: 0.305, memory: 3435, top1_acc: 0.0672, top5_acc: 0.2406, loss_cls: 3.8367, loss: 3.8367, grad_norm: 0.7593
2022-05-29 22:03:10,991 - pyskl - INFO - Epoch [1][100/5028] lr: 4.000e-01, eta: 22:22:50, time: 0.512, data_time: 0.299, memory: 3435, top1_acc: 0.0703, top5_acc: 0.2781, loss_cls: 3.7493, loss: 3.7493, grad_norm: 0.7084
2022-05-29 22:03:21,242 - pyskl - INFO - Epoch [1][120/5028] lr: 4.000e-01, eta: 21:30:28, time: 0.513, data_time: 0.304, memory: 3435, top1_acc: 0.0703, top5_acc: 0.2734, loss_cls: 3.7274, loss: 3.7274, grad_norm: 0.7322
2022-05-29 22:03:31,635 - pyskl - INFO - Epoch [1][140/5028] lr: 4.000e-01, eta: 20:55:03, time: 0.520, data_time: 0.307, memory: 3435, top1_acc: 0.0750, top5_acc: 0.3078, loss_cls: 3.5935, loss: 3.5935, grad_norm: 0.7785
2022-05-29 22:03:42,003 - pyskl - INFO - Epoch [1][160/5028] lr: 4.000e-01, eta: 20:28:09, time: 0.518, data_time: 0.305, memory: 3435, top1_acc: 0.0969, top5_acc: 0.3406, loss_cls: 3.5519, loss: 3.5519, grad_norm: 0.7937
2022-05-29 22:03:52,321 - pyskl - INFO - Epoch [1][180/5028] lr: 4.000e-01, eta: 20:06:37, time: 0.516, data_time: 0.308, memory: 3435, top1_acc: 0.0906, top5_acc: 0.3500, loss_cls: 3.4544, loss: 3.4544, grad_norm: 0.7841
2022-05-29 22:04:02,685 - pyskl - INFO - Epoch [1][200/5028] lr: 4.000e-01, eta: 19:49:49, time: 0.518, data_time: 0.307, memory: 3435, top1_acc: 0.1328, top5_acc: 0.3922, loss_cls: 3.4156, loss: 3.4156, grad_norm: 0.8423
2022-05-29 22:04:12,908 - pyskl - INFO - Epoch [1][220/5028] lr: 4.000e-01, eta: 19:34:45, time: 0.511, data_time: 0.298, memory: 3435, top1_acc: 0.1141, top5_acc: 0.4172, loss_cls: 3.3825, loss: 3.3825, grad_norm: 0.8420
2022-05-29 22:04:23,137 - pyskl - INFO - Epoch [1][240/5028] lr: 4.000e-01, eta: 19:22:14, time: 0.511, data_time: 0.300, memory: 3435, top1_acc: 0.1187, top5_acc: 0.3641, loss_cls: 3.4577, loss: 3.4577, grad_norm: 0.7502
因为我是一个GPU,训练24个epach大概需要8个小时,我看最后的训练top1_acc和top2_acc都很高,还没测试,后面测试一下。
版权归原作者 骑走的小木马 所有, 如有侵权,请联系我们删除。