
Disco-Diffusion5.2 本地搭建测试记录
Disco Diffusion基于CLIP-Guided Diffusion网络实现文本输入,美图输出,还可以选不同的画家风格。具体技术实现不在这里讲了可以参考官方文档后面的资源部分。或者看论文。
友情论文秃头链接:https://arxiv.org/abs/2105.05233https://arxiv.org/abs/2105.05233
好了下面开始Debug,先上一组自己生成的图,图下面是生成图像用的文字说明,制定画家和场景关键词描述就可以出图。

artstation,Greg Rutkowski,city,dream,universe,original,time,cloud,future,night

A cyberpunk city with a spaceship in the sky

artstation,Greg Rutkowski,sea,dikel,ship,industrialization,cloud,time,future,afternoon
通过更改笔记本中文字重新运行就可以生成不同风格的图片,我用的是RTX3090的卡,生成图像分辨率为1280*768,其它配置用的默认,大概25-30分钟一张图,比Colab普通版快3倍左右。想看其它小伙伴生成的图可以去Discord,有挺多好看的图片。
https://discord.gg/XGZrFFCRfNhttps://discord.gg/XGZrFFCRfN
一、项目官方文档
官方英文文档
简单机翻了一下的文档
Docshttps://u64b10hj3j.feishu.cn/docs/doccn8fbnQ6MnkCAFQpcjADO7Ae
项目Github地址
GitHub - alembics/disco-diffusionContribute to alembics/disco-diffusion development by creating an account on GitHub.https://github.com/alembics/disco-diffusion
官方演示Colab
二、本地安装测试
2.1 文件克隆
git clone https://github.com/openai/guided-diffusion.git
直接克隆之后文件夹和模型都不全,需要运行Disco_Diffusion.ipynb进行环境安装
完整一些的目录大概是这样的
2.2 环境搭建
项目要用pytorch,自己搭很多库,最好直接用Anaconda
Anaconda | The World's Most Popular Data Science Platform
运行项目笔记本,前几步问题不大,用conda环境,python版本选3.9就可以,3.10也行。
第二个单元会提示没检测到colab,模型会选用本地的models文件夹

第三个单元检测一些必须的依赖包,没装成的直接pip装就行
然后是这一步,会把缺的文件补上,下载可能会有点慢耐心等等,或者自己手动克隆也行,这一步必须要确保文件夹都下载了不然后面会很多问题
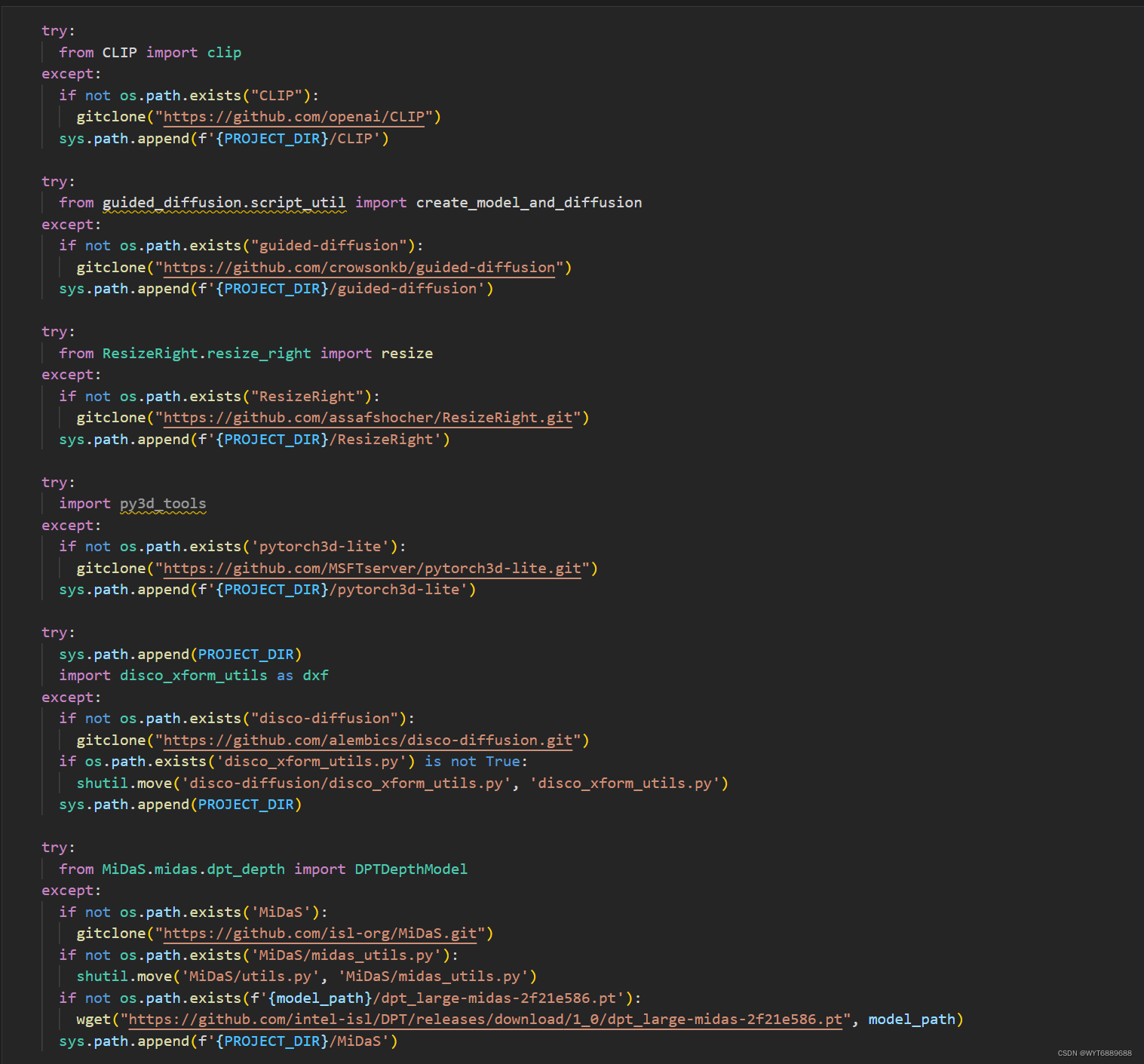
之后是torch和一些其他包引用,这里面有坑就是有些import会出错,因为文件夹嵌套的原因,需要手动改一下,比如MiDaS文件夹以及里面要用的midas_utils.py,文件夹和笔记本中名称大小写要一致不然找不到那个文件夹和里面脚本。
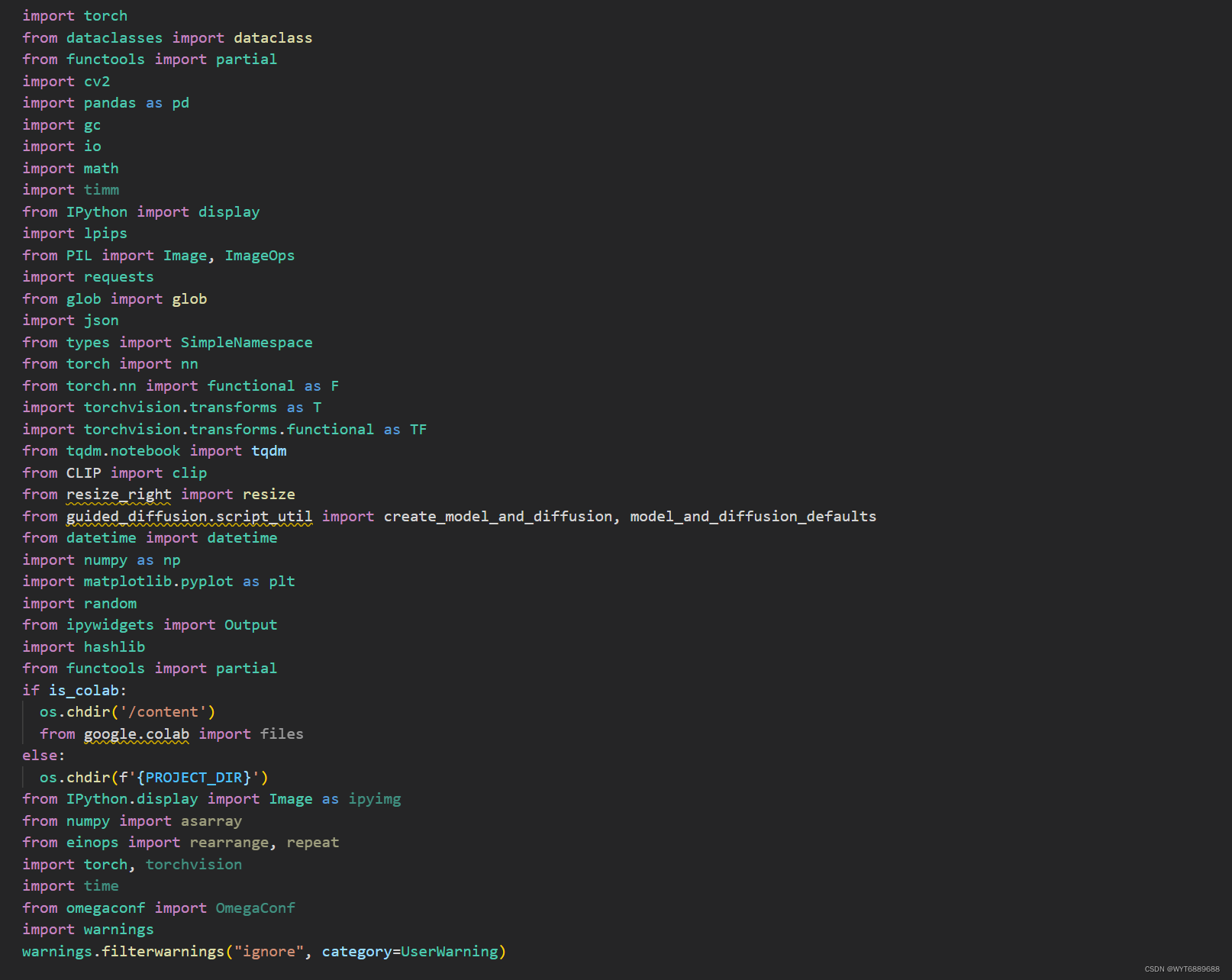
接下里两步也是下载文件夹和配环境

之后的几个单元格很长是一些函数定义,直接运行即可
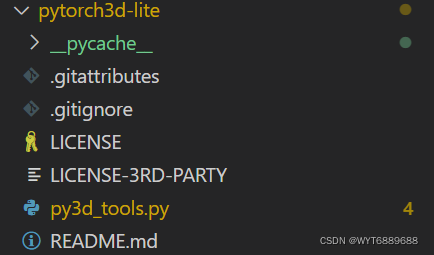
中间夹的这个py3d也有坑,也是文件目录名称的问题,改对大小写然后路径别写错就行。

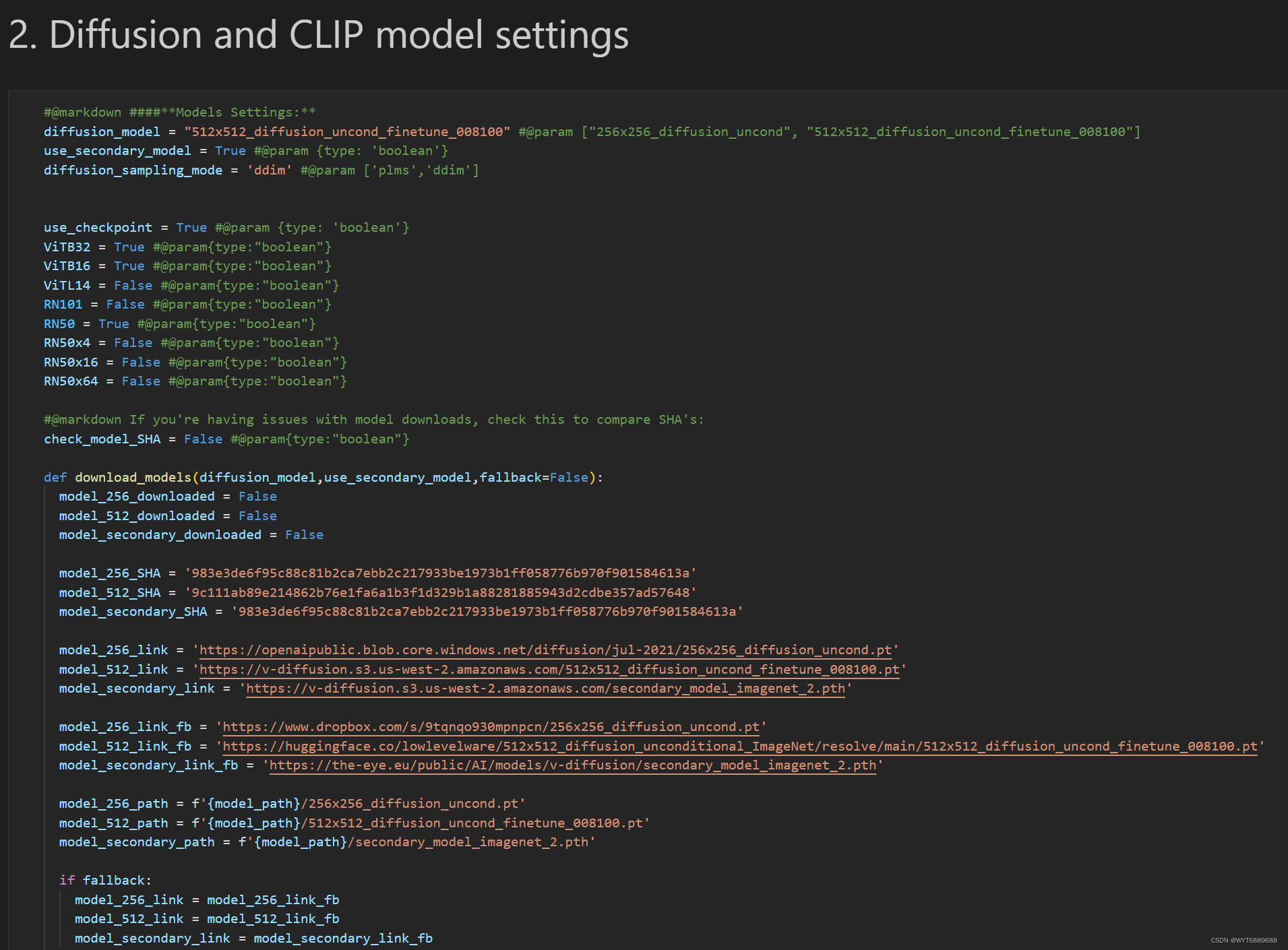
2.3 模型设置
然后到了第二部分,模型设置,这里要注意默认用的是512512的模型,会比较吃显卡,前面可以调成256256的。然后模型一定要先下载到本地models文件夹里,最好用下载器下,浏览器有点慢。
运行之后会提示选了512模型,并校验,稍等一会就好,然后下一个单元格clip_models可以暂时不下载,后面可以用这个改变风格,这个视频模式要用,单生成图片不用配置也没事,很占内存。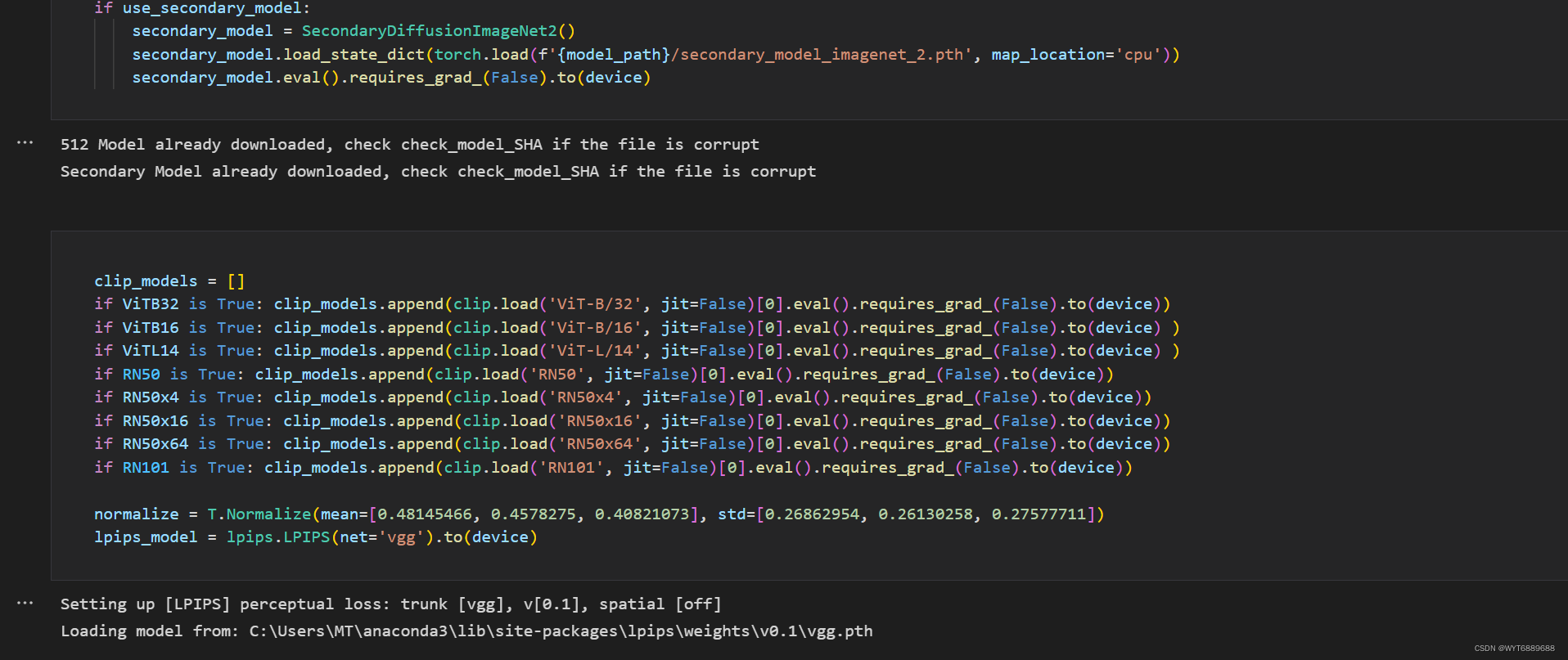
然后就是关键的模型设置
这里batch_name是文件夹名,里面图片也会根据这个命名
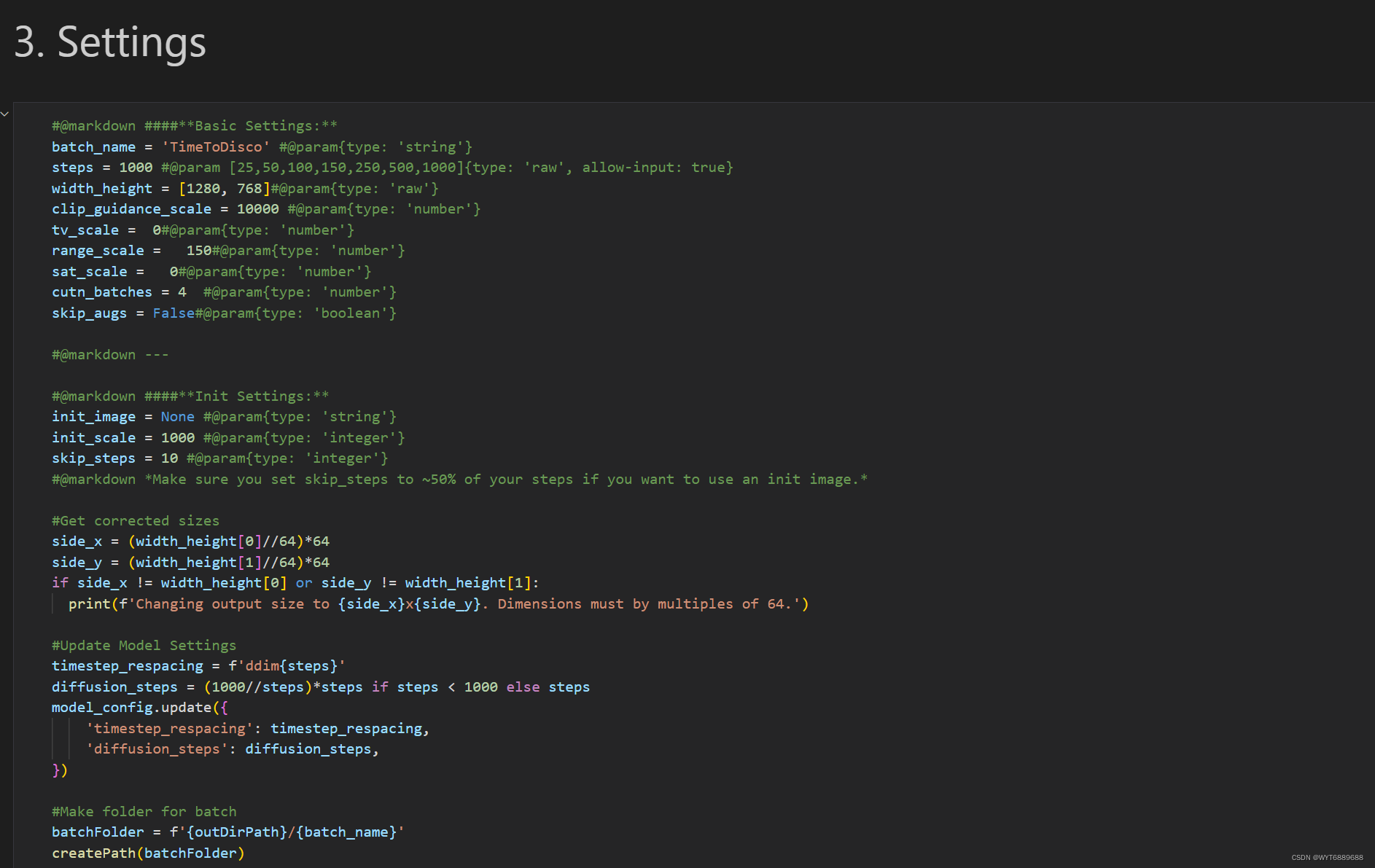
width_height是期望的最终图像大小,应该设置为64px的倍数,并且在默认的CLIP模型设置上至少设置为512px。如果忘记使用64px的倍数,DD会调整图像尺寸。
steps是迭代步数,越高细节越多。
下面的几个摘自文档解释,前面测试可以不改动。
clip_guidance_scale:(5000|1500-100000) CGS是希望CLIP在每个时间步向提示符移动的程度。一般越高越好,但如果CGS太强,就会超出目标而扭曲图像。
tv_scale:(0|0-1000)总方差去噪。可选,设置为零关闭。控制最终输出的“平滑”。如果使用,tv_scale将尝试平滑您的最终图像,以减少整体噪声。如果你的图像太“脆”,增加tv_scale。电视去噪在保持边缘的同时平滑平滑平坦区域的噪声。参见https://en.wikipedia.org/wiki/Total_variation_denoising
range_scale:(150|0-1000)可选,设置为0表示关闭。用于调整颜色对比度。更低的range_scale将增加对比度。非常低的数字会减少色彩,从而产生更有活力或像海报一样的图像。对于更弱的图像,更高的range_scale会降低对比度。
sat_scale:(0|0-20000)饱和刻度。可选,设置为零关闭。如果使用,sat_scale将有助于缓解过饱和。如果你的图片太饱和了,增加sat_scale来降低饱和度。
init_image:可选的。回想一下,在上面的图像序列中,第一个显示的图像只是噪声。如果提供了一个init_image,扩散将用init_image代替噪声作阿为它的启动状态。要使用init_image,请将图像上传到Colab实例或您的谷歌驱动器,并在这里输入完整的图像路径。
如果使用init_image,可能需要将skip_steps增加到总步骤的50%,以保留init字符。有关进一步的讨论,请参阅上面的skip_steps。
init_scale:(1000|10-20000)它控制CLIP尝试匹配所提供的init_image的强度。这与上面的clip_guidance_scale (CGS)进行了平衡。初始尺度太大,在扩散过程中图像不会有太大的变化。CGS太多,init镜像会丢失。
cut_batches:(4|1-8)每次迭代,AI将图像切割成更小的部分,称为cuts,并将每个切割与提示进行比较,以决定如何引导下一步扩散。更多的剪切通常可以产生更好的图像,因为DD在每个时间步中有更多的机会微调图像精度。
然后两个单元格是动画和其他设置可以先不动
2.4 生成文字设置
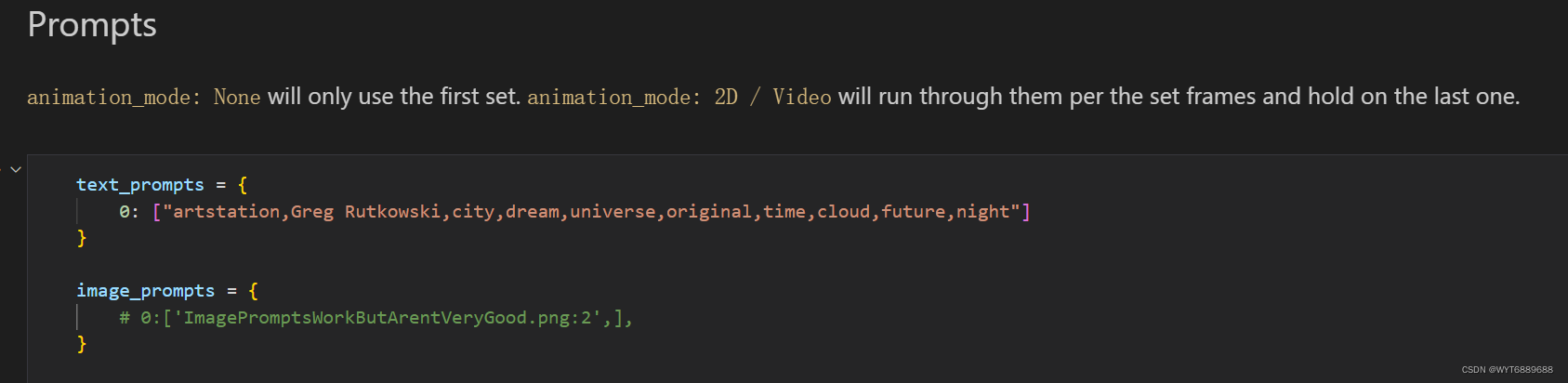
这款里就是最关键的短语设置部分,text_prompts就是短语,0:是第一帧,如果是动画可以设置从哪一帧开始变风格,单个图片就设置一句就行。image_prompts是基于哪张图片进行生成,这个也很有意思可以自己选图片实验。
怎么设置好的确是门艺术,不过大概有场景描述就可以生成,有喜欢的艺术家也可以加上,还有时间,地点也可以。
我这里用的描述是:**"artstation,Greg Rutkowski,city,dream,universe,original,time,cloud,future,night"**
官方的例子描述是:"A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation.”
就是说:“greg rutkowski和thomas kinkade在Trending on artstation上绘制的一幅美丽的灯塔画,它的光芒照耀着一片喧嚣的血海。”
测试生成的大概是这样:

这里引入了两位艺术家,想查看其他艺术家可以看这个表格,两千多位可以选:
2.5 生成图片
然后就是激动人心的生成了, batch_size是要生成的图片个数,默认是50会比较久,可以先设置1个测一下速度。
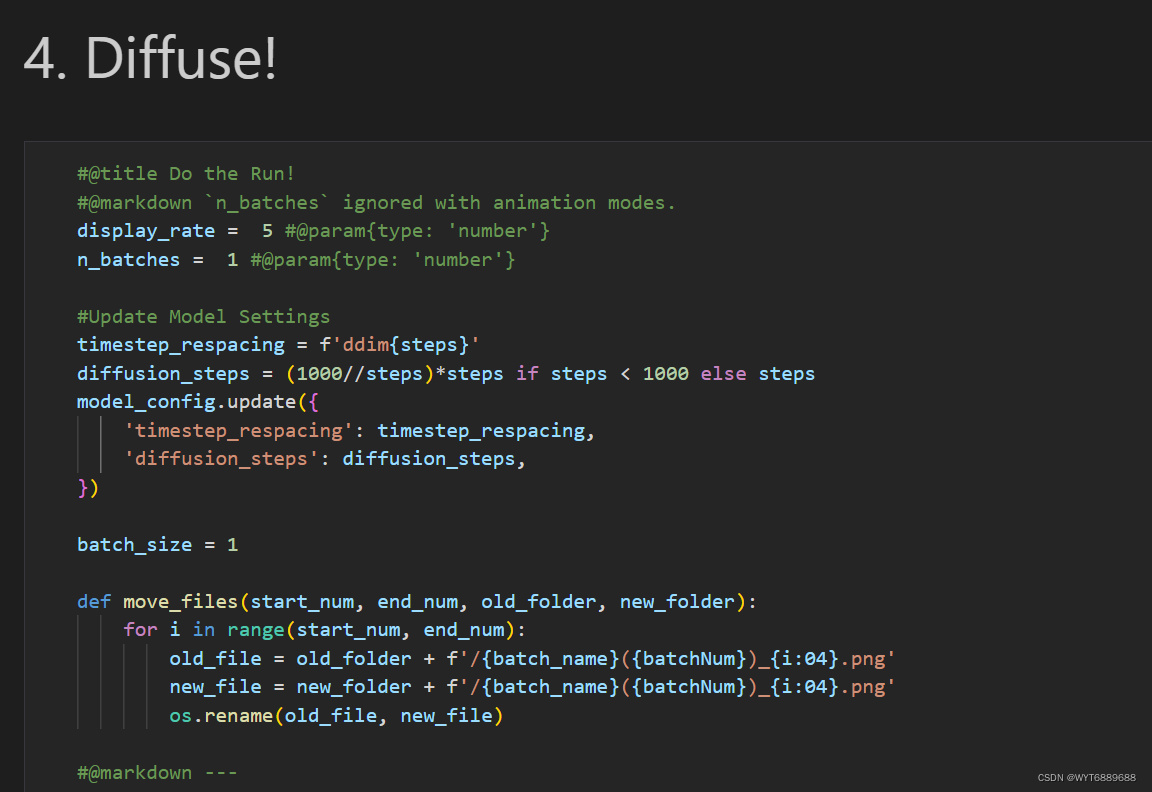
点击运行后,生成(准确说是降噪)开始。

图片会一点一点变清晰。





最后用时27分半。
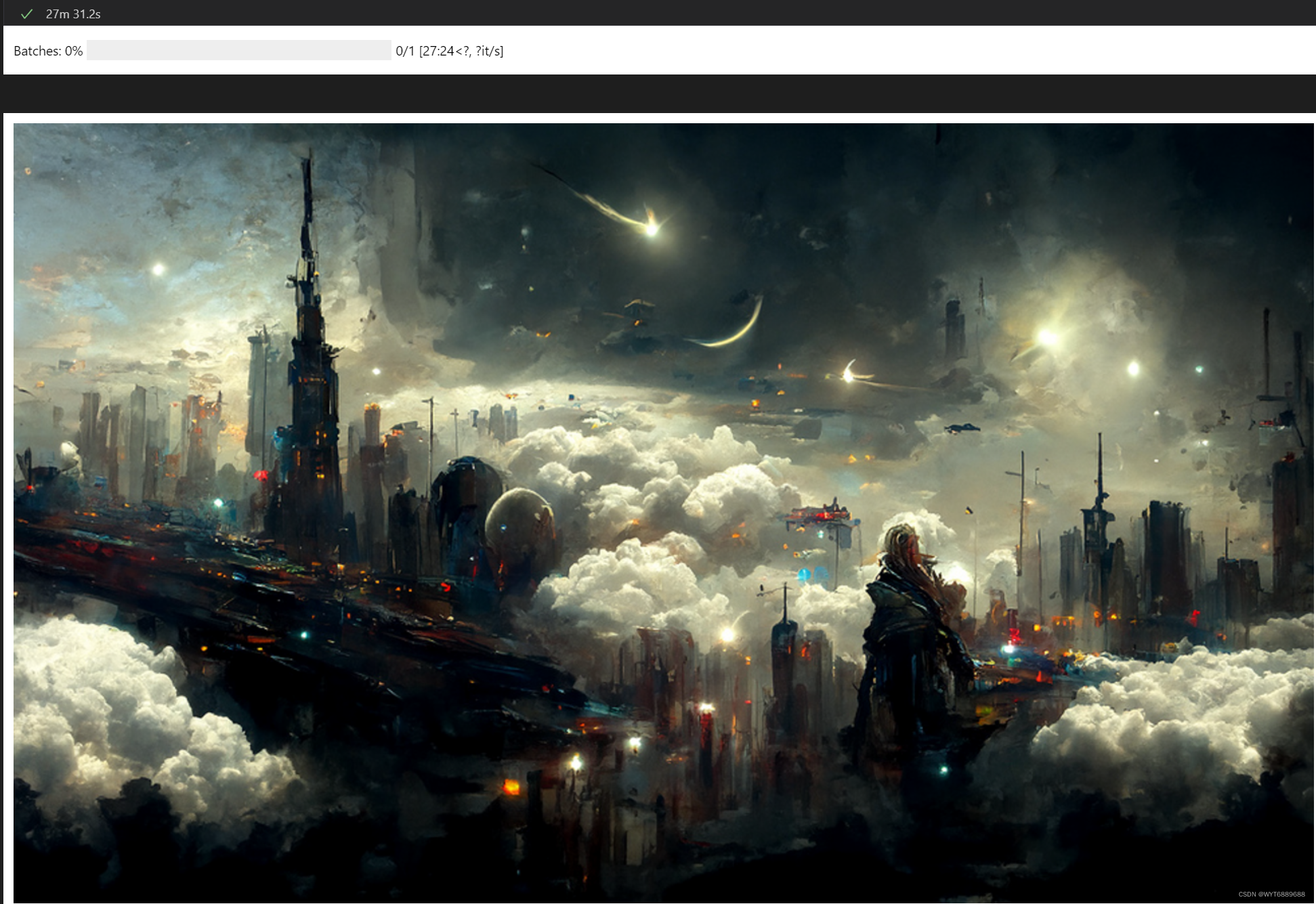
最终图片如下:

2.5 超分辨率
如果觉得当前分辨率低,可以设高一些,但是我测一下一下3090设置成1920*1080后显存会不够导致渲染变慢,要好几个小时才能输出一张图。
所以可以用超分辨率的方案来做。
这里推荐Google的Esrgan。
模型网站:
https://tfhub.dev/captain-pool/esrgan-tf2/1https://tfhub.dev/captain-pool/esrgan-tf2/1
下载链接:
下载后解压即可
运行笔记本代码:
import os
import time
from PIL import Image
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
IMAGE_PATH = "o1.png"
SAVED_MODEL_PATH = "model"
def preprocess_image(image_path):
""" Loads image from path and preprocesses to make it model ready
Args:
image_path: Path to the image file
"""
hr_image = tf.image.decode_image(tf.io.read_file(image_path))
# If PNG, remove the alpha channel. The model only supports
# images with 3 color channels.
if hr_image.shape[-1] == 4:
hr_image = hr_image[...,:-1]
hr_size = (tf.convert_to_tensor(hr_image.shape[:-1]) // 4) * 4
hr_image = tf.image.crop_to_bounding_box(hr_image, 0, 0, hr_size[0], hr_size[1])
hr_image = tf.cast(hr_image, tf.float32)
return tf.expand_dims(hr_image, 0)
def save_image(image, filename):
"""
Saves unscaled Tensor Images.
Args:
image: 3D image tensor. [height, width, channels]
filename: Name of the file to save.
"""
if not isinstance(image, Image.Image):
image = tf.clip_by_value(image, 0, 255)
image = Image.fromarray(tf.cast(image, tf.uint8).numpy())
image.save("%s.jpg" % filename)
print("Saved as %s.jpg" % filename)
%matplotlib inline
def plot_image(image, title=""):
"""
Plots images from image tensors.
Args:
image: 3D image tensor. [height, width, channels].
title: Title to display in the plot.
"""
image = np.asarray(image)
image = tf.clip_by_value(image, 0, 255)
image = Image.fromarray(tf.cast(image, tf.uint8).numpy())
plt.imshow(image)
plt.axis("off")
plt.title(title)
hr_image = preprocess_image(IMAGE_PATH)
# Plotting Original Resolution image
plot_image(tf.squeeze(hr_image), title="Original Image")
save_image(tf.squeeze(hr_image), filename="Original Image")
model = hub.load(SAVED_MODEL_PATH)
start = time.time()
fake_image = model(hr_image)
fake_image = tf.squeeze(fake_image)
print("Time Taken: %f" % (time.time() - start))
save_image(tf.squeeze(fake_image), filename="Super Resolution1")
# Plotting Super Resolution Image
plot_image(tf.squeeze(fake_image), title="Super Resolution")
运行后输出一张4倍分辨率的图片,不过细节还是有限。
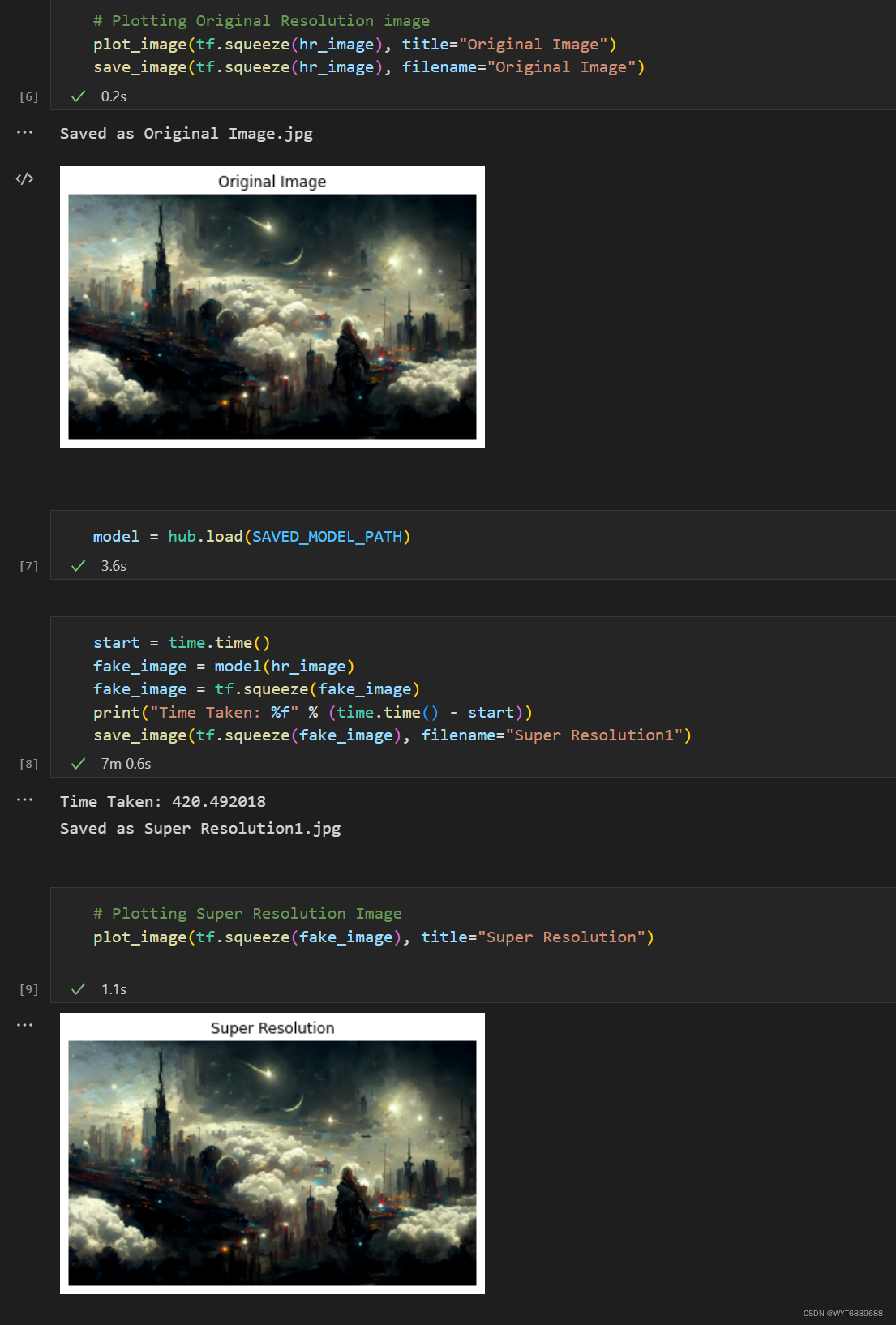
输出图片如下:

2.6 视频生成
笔记本例子最后一部分是视频生成,对显卡要求比较高。
版权归原作者 卷不动的神经网路 所有, 如有侵权,请联系我们删除。