
Attentional Feature Fusion 注意力特征融合
最近看到一篇比较不错的特征融合方法,基于注意力机制的
AAF,与此前的
SENet、
SKNet等很相似,但
AFF性能优于它们,并且适用于更广泛的场景,包括短和长跳连接以及在
Inception层内引起的特征融合。
AFF是由南航提出的注意力特征融合,即插即用!
本篇博客主要参考自知乎作者
OucQxw
,知乎原文地址:
https://zhuanlan.zhihu.com/p/424031096
论文下载地址:https://arxiv.org/pdf/2009.14082.pdf
Github代码地址:https://github.com/YimianDai/open-aff
一、Motivation
特征融合是指来自不同层次或分支的特征的组合,是现代神经网络体系结构中无所不在的一部分。它通常通过简单线性的操作(例如:求和或者串联来实现),但这可能不是最佳的选择。本文提出了一个统一的通用方案,即注意力特征融合(
AFF
),该方案适用于大多数常见场景,包括短和长跳连接以及在
Inception
层内引起的特征融合。
为了更好地融合语义和尺度不一致的特征,我们提出了
多尺度通道注意力模块
(
MS-CAM
),该模块解决了融合不同尺度特征时出现的问题。我们还证明了初始特征融合可能会成为瓶颈,并提出了迭代注意力特征融合模块(
iAFF
)来缓解此问题。
- 近年发展的
SKNet和ResNeSt注意力特征融合存在的问题:
- 场景限制:
SKNet和ResNeSt只关注同一层的特征选择,无法做到跨层特征融合。 - 简单的初始集成 :为了将得到的特征提供给注意力模块,
SKNet通过相加来进行特征融合,而这些特征在规模和语义上可能存在很大的不一致性,对融合权值的质量也有很大的影响,使得模型表现受限。 - 偏向上下文聚合尺度:
SKNet和ResNeSt中的融合权值是通过全局通道注意机制生成的,对于分布更全局的信息,该机制更受青睐,但是对于小目标效果就不太好。是否可以通过神经网络动态地融合不同尺度的特征?
- 本文的贡献,针对于上述三个问题,提出以下解决办法:
- 注意特征融合模块(
AFF),适用于大多数常见场景,包括由short and long skip connections以及在Inception层内引起的特征融合。 - 迭代注意特征融合模块(
IAFF),将初始特征融合与另一个注意力模块交替集成。 - 引入多尺度通道注意力模块(
MSCAM),通过尺度不同的两个分支来提取通道注意力。
二、Method
- Multi-scale Channel Attention Module (
MS-CAM)
MS-CAM 主要是延续
SENet
的想法,再于 CNN 上结合
Local / Global
的特征,并在空间上用 Attention 来 融合多尺度信息 。
MS-CAM
有 2 个较大的不同:
MS-CAM通过逐点卷积(1x1卷积)来关注通道的尺度问题,而不是大小不同的卷积核,使用点卷积,为了让MS-CAM尽可能的轻量化。MS-CAM不是在主干网中,而是在通道注意力模块中局部本地和全局的特征上下文特征。
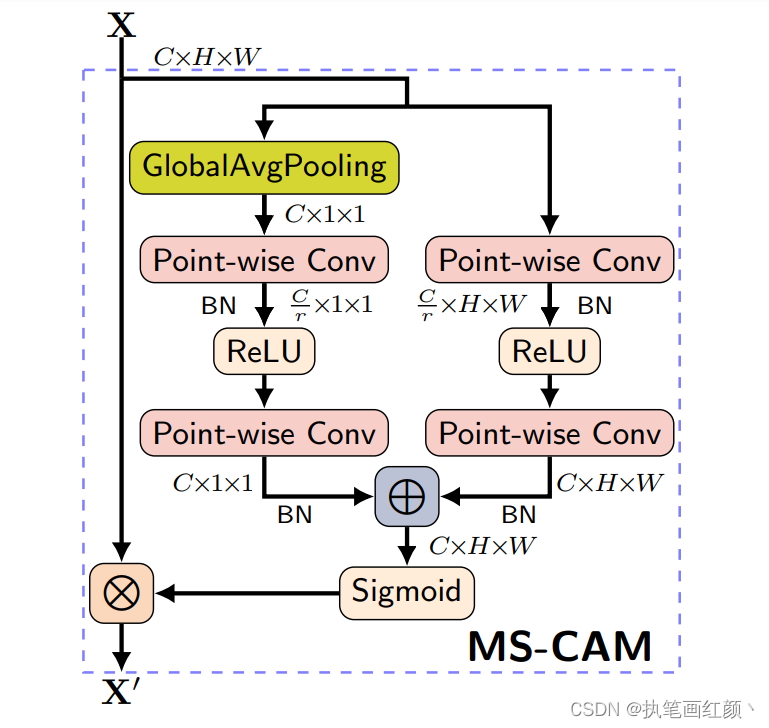
上图为
MS-CAM
的结构图,
X
为输入特征,
X'
为融合后的特征,右边两个分支分别表示全局特征的通道注意力和局部特征的通道注意力,局部特征的通道注意力的计算公式
L(X)
如下:



实现的代码如下:
classMS_CAM(nn.Module):'''
单特征进行通道注意力加权,作用类似SE模块
'''def__init__(self, channels=64, r=4):super(MS_CAM, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)return x * wei
- Attentional Feature Fusion(
AFF)
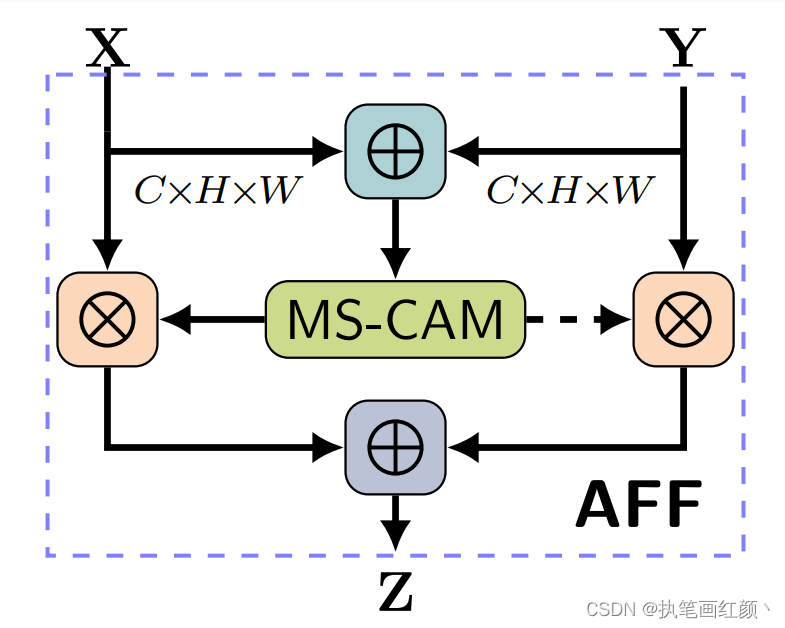
给定两个特征
X,
Y
进行特征融合(
Y
代表感受野更大的特征)。
AFF
的计算方法如下:

对输入的两个特征
X
,
Y
先做初始特征融合,再将得到的初始特征经过
MS-CAM
模块,经过
sigmod
激活函数,输出值为 0~1 之间,作者希望对
X
、
Y
做加权平均,就用 1 减去这组
Fusion weight
,可以作到
Soft selection
,通过训练,让网络确定各自的权重。
实现的代码如下:
classAFF(nn.Module):'''
多特征融合 AFF
'''def__init__(self, channels=64, r=4):super(AFF, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = x * wei + residual *(1- wei)return xo
- iterative Attentional Feature Fusion (
iAFF)

在注意力特征融合模块中,
X
,
Y
初始特征的融合仅是简单对应元素相加,然后作为注意力模块的输入会对最终融合权重产生影响。作者认为如果想要对输入的特征图有完整的感知,只有将初始特征融合也采用注意力融合的机制,一种直观的方法是使用另一个
attention
模块来融合输入的特征。
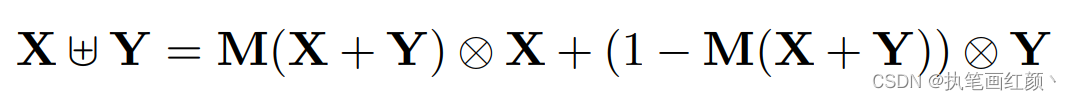
公式跟
AFF
的计算一样,仅仅是多加一层attention。
实现的代码如下:
classiAFF(nn.Module):'''
多特征融合 iAFF
'''def__init__(self, channels=64, r=4):super(iAFF, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 第二次局部注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual *(1- wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual *(1- wei2)return xo
三、Experiments
这里展示部分实验结果,详细的实验结果请参考原论文。
- 为了验证Multi-scale 的作法是否有效,作者设置了Global + Global 和Local + Local两种方法,与Global + Local对比,发现全局+局部的效果还是最优的。


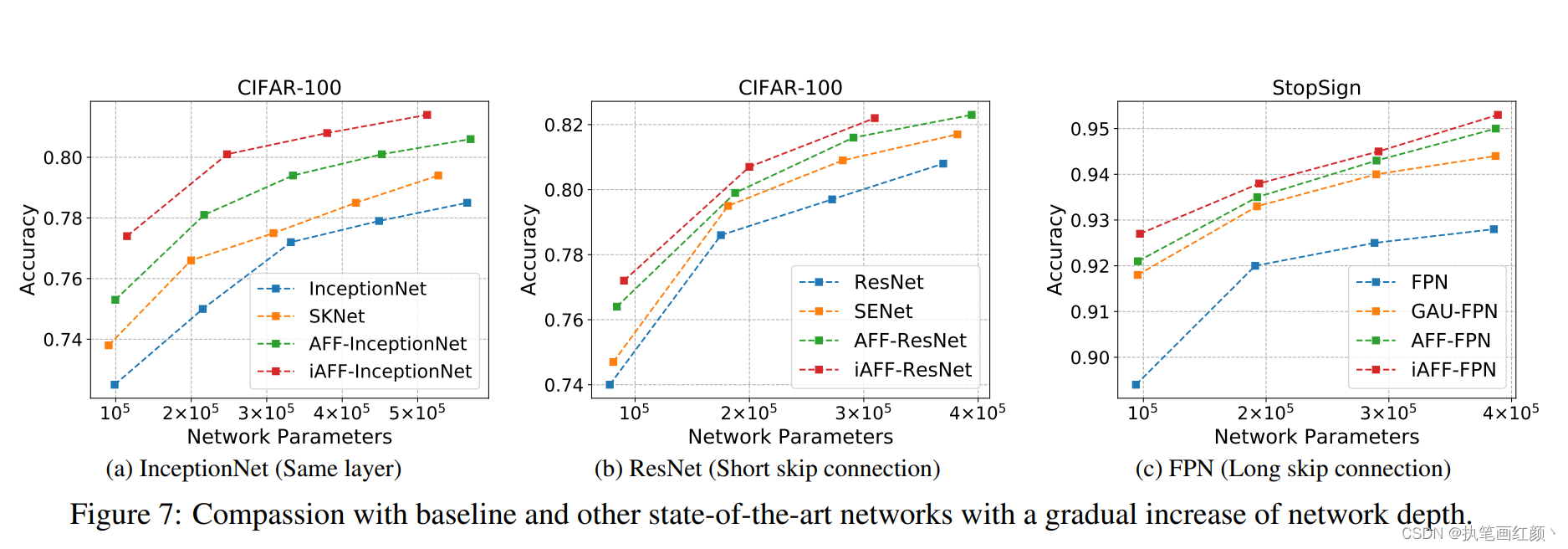
- 在各种主流网络中,使用本论文中提出的特征融合方法,用于短跳连接、长跳连接、同一层的特征融合中,效果均优于之前的模型。
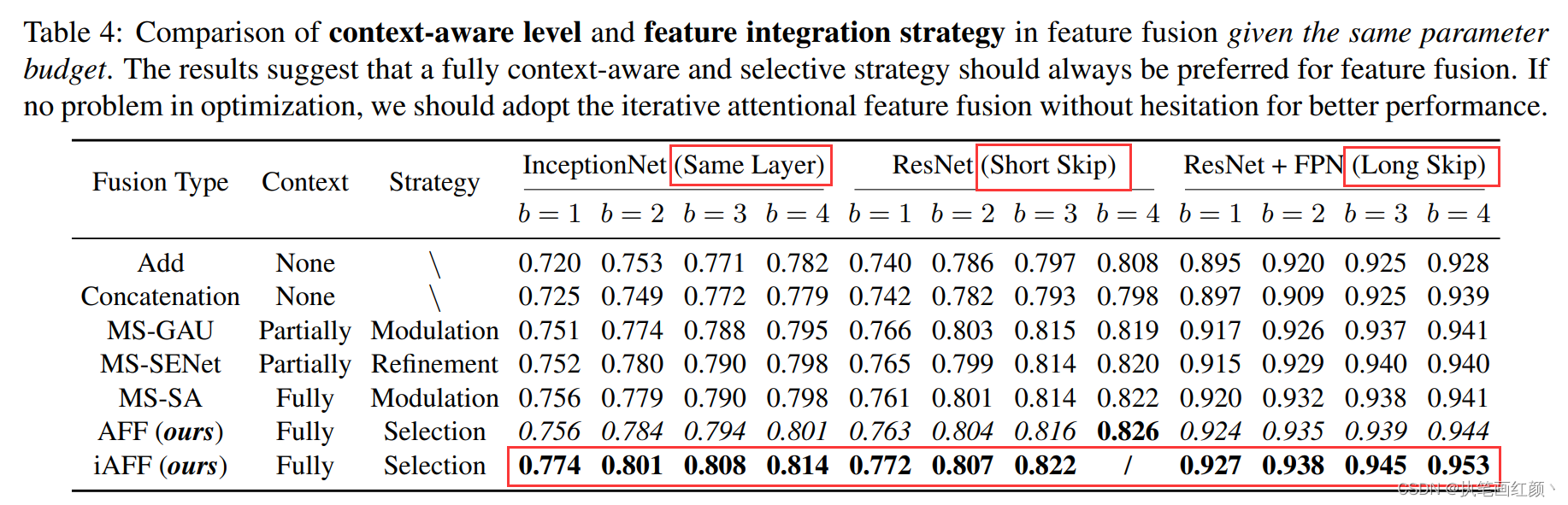
- 不同的图像分类数据集上,在原有的网络模型中加入本文提出的特征融合方法,并与其原模型进行比较,发现准确率和网络的参数大小都得到了不错的性能提升。
版权归原作者 执笔画红颜丶 所有, 如有侵权,请联系我们删除。