朴素贝叶斯(Naive Bayes)
朴素贝叶斯
如何进行AI测试-入门篇
大家来做下这个猜数字游戏,1, 4, 16…()… 256… 括号里的是什么。为什么是 64,不是其他数字,又为什么是数字,不是一个汉字或者一个字母。我们找到了数字之间的规律,逻辑关系,并且抽象成了模型,我们才能知道括号里是什么。举个生活中的例子,小米硬件中手机外壳,在大批量生产前需要先设计手机外壳

这8个NumPy函数可以解决90%的常见问题
NumPy是一个用于科学计算和数据分析的Python库,也是机器学习的支柱。
机器学习特征重要性分析
特征选择
nn.Parameter()
可以方便地定义和管理模型的可训练参数,并且在模型训练过程中可以自动计算梯度并更新参数值,是构建神经网络模型时常用的工具。是 PyTorch 中的一个类,用于创建可训练的参数(权重和偏置),这些参数会在模型训练过程中自动更新。
win下YOLOv7训练自己的数据集(交通标志TT100K识别)
遗传算法是利用种群搜索技术将种群作为一组问题解,通过对当前种群施加类似生物遗传环境因素的选择、交叉、变异等一系列的遗传操作来产生新一代的种群,并逐步使种群优化到包含近似最优解的状态,遗传算法调优能够求出优化问题的全局最优解,优化结果与初始条件无关,算法独立于求解域,具有较强的鲁棒性,适合于求解复杂的
『赠书活动 | 第五期』《人工智能数学基础》
『赠书活动 | 第五期』《人工智能数学基础》
三十七、Fluent冰块融化模拟
单击Initialize后,点击Patch,对冰区域设置温度,选择Temperature,Value设置为-1℃,Zone to patch选择ice_surface。Solidus Temperature表示固相线温度,对于纯物质即凝固点,Liquidus Temperature表示熔点,对于纯物
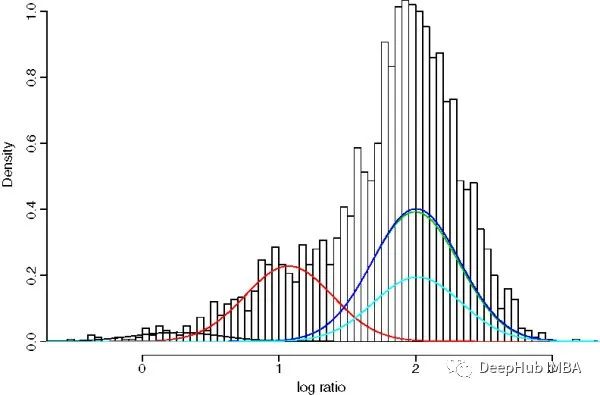
基于GMM的一维时序数据平滑算法
在本文中探讨GMM作为时间数据平滑算法的使用。GMM(Gaussian Mixture Model)是一种统计模型,常用于数据聚类和密度估计,但也可以在一定程度上用作时间数据平滑算法。
YOLO v5结合热力图并可视化以及网络各层的特征图
YOLO v5结合热力图并可视化以及网络各层的特征图
首个大规模图文多模态数据集LAION-400M介绍
openAI的图文多模态模型CLIP证明了图文多模态在多个领域都具有着巨大潜力,随之而来掀起了一股图文对比学习的风潮。就在前几天(2022年12月),连Kaiming都入手这一领域,将MAE的思路与CLIP的思路结合,推出了FLIP,有兴趣可戳(https://arxiv.org/abs/2212.
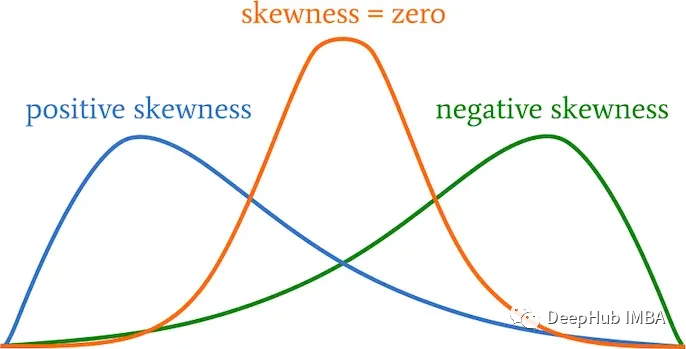
数据偏度介绍和处理方法
偏度(skewness)是用来衡量概率分布或数据集中不对称程度的统计量。
【机器学习】第四节:监督学习算法对比评估
监督学习(英语:Supervised learning)是机器学习中最为常见、应用最为广泛的分支之一。本次实验将带你了解监督学习中常见的分类方法,并学会使用 scikit-learn 来构建预测模型,用于解决实际问题。
文生图关键问题探索:个性化定制和效果评价
文生图模型是当前人工智能领域最具潜力和前景的研究方向之一。未来,随着计算能力的提高和技术的进一步发展,文生图模型的应用前景将会更加广泛和深远。然而,针对其应用过程中存在的一些问题,如模型评价缺乏一致性、控制生成过程效率低下、定制个性化模型困难以及高质量文图数据集缺乏等,需要我们进一步研究探索解决方案
2023 年第三届长三角高校数学建模竞赛赛题浅析
快递为背景的题目作为优化是这两年最为常见的一种命题背景,该题的问题方式有些类似于2021年妈杯的海底服务器散热问题,即建立优化模型合理的构建布局,耗材等等。B题的主要问题就是预测+数据,以汽车为背景,收集数据,构建预测模型,分析关联性。关于数据问题,我会帮大家进行收集,目前已有的数据为问题三碳排放相
YOLOv8:车辆检测技术及优化
随着自动驾驶汽车和智能交通系统的发展,车辆检测技术在近年来变得越来越重要。为了解决这一问题,YOLO (You Only Look Once) 是一种实时目标检测算法,自从2016年推出以来,它已经经历了多个版本的更新。本文将详细介绍YOLOv8,这是一个最新的、高效的车辆检测方法,并附有Pytho
ChatGPT的工作原理是什么?
ChatGPT是美国OpenAI研发的聊天机器人程序,2022年11月30日发布。ChatGPT是人工智能技术驱动的自然语言处理工具,它能够通过理解和学习人类的语言来进行对话。
机器学习 C4.5算法原理 + 决策树分裂详解(离散属性+连续属性) 附python代码
(5)C4.5采用二分法处理连续特征,将连续特征进行排列,将连续两个值的中间值作为分裂节点,将小于该值和大于该值的样本分为两个类别,找到信息增益最大的分裂点,本质上还是用的离散特征。如果一个属性的信息增益越大,就表示用这个属性进行样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快
AI技术:智慧交通时代的道路识别(文末送书四本)
Hello大家好,我是Dream。 自动驾驶是当前最热门的技术之一,而道路识别则是自动驾驶系统中的重要一环。它需要自动驾驶车辆能够识别和解读道路标志、路面标线、交通信号灯等道路条件,及时准确地做出驾驶决策。接下来Dream将带大家去了解如何实现道路识别。

Scikit-LLM:将大语言模型整合进Sklearn的工作流
我们以前介绍过Pandas和ChaGPT整合,这样可以不了解Pandas的情况下对DataFrame进行操作。现在又有人开源了Scikit-LLM,它结合了强大的语言模型,如ChatGPT和scikit-learn。



