
数据汇总是一个将原始数据简化为其主要成分或特征的过程,使其更容易理解、可视化和分析。本文介绍总结数据的七种重要方法,有助于理解数据实质的内容。
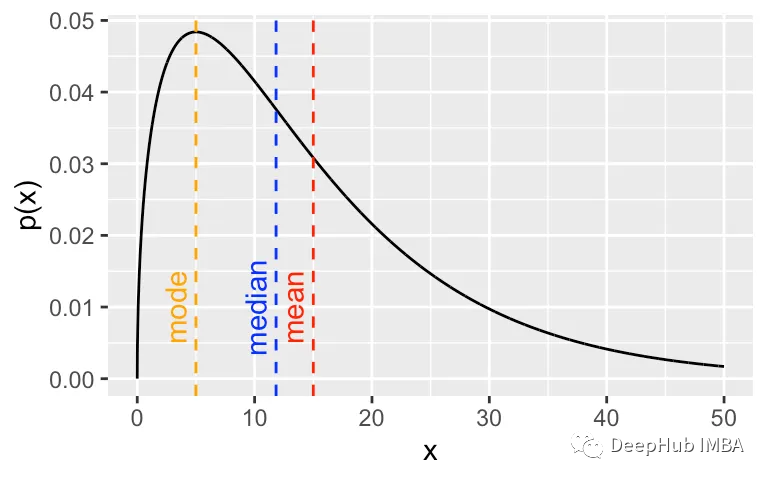
1、集中趋势:平均值,中位数,众数
集中趋势是一种统计测量,目的是确认最典型的个体,找到最能够代表整个组的单个数值。它可以提供对数据集中“典型”数据点的准确描述。集中趋势的三个主要度量是平均值、中位数和众数。
平均值:通过将数据集中的所有数据点相加,然后除以数据点的数量来计算平均值。
中位数:中位数是数据集的中间点。要找到中位数,必须首先按量级(升序或降序)对数据进行排序。如果数据集包含奇数个观测值,则中位数为中间值。如果有偶数个观测值,中位数是两个中间值的平均值。
众数:众数是数据集中出现频率最高的值。数据集可以有一个众数(单峰),两个众数(双峰),或多个众数(多峰)。
理解集中趋势有助于建立一个“典型”值,作为数据的有用总结。
2、离散度:范围,方差,标准差
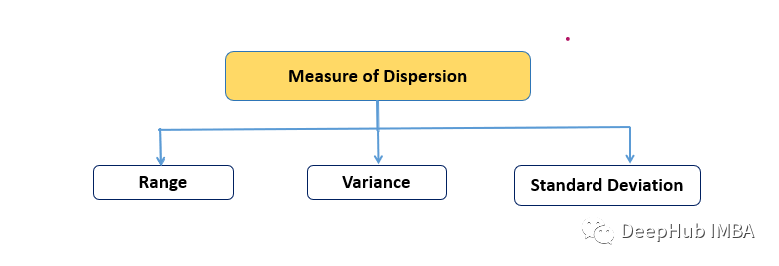
集中趋势的度量可以为数据提供一个摘要,而离散度的度量则描述了数据点的分布。它们提供了对数据集内可变性的洞察。衡量离散度的关键指标包括范围、方差和标准差。
范围:范围是最简单的离散度量。它是数据集中的最大值减去最小值来计算的。
方差:方差是衡量数据集中的数据点与均值相差多少的指标。它是通过取平均值的平方差的平均值来计算的。
标准差:标准差是方差的平方根。它衡量每个数据点与平均值之间的平均距离。它用与数据相同的单位表示,所以特别有用。
理解离散度对于衡量数据的可靠性至关重要。高离散度表明数据的高度可变性。
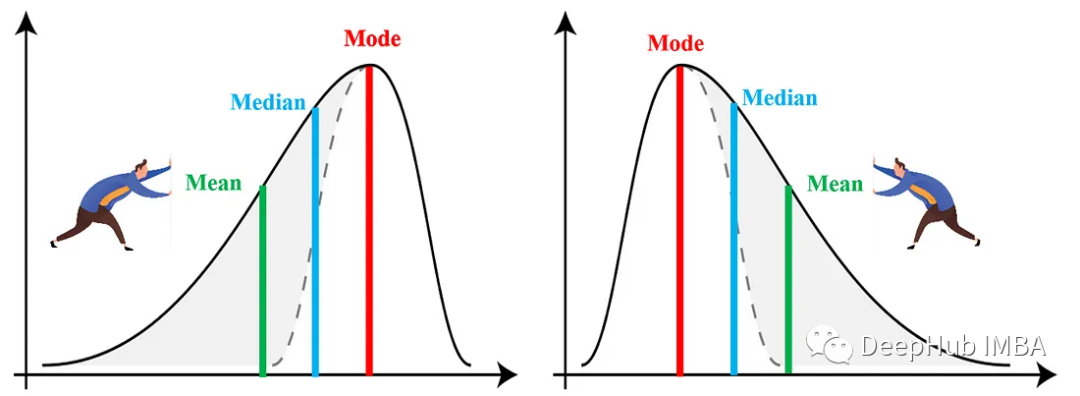
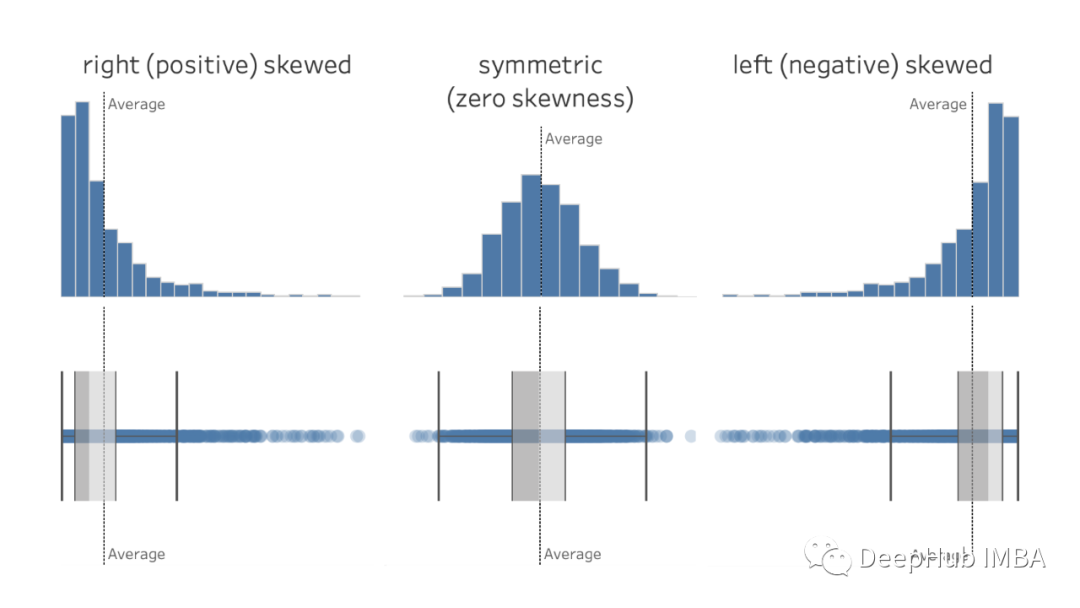
3、偏度和峰度
偏度和峰度是衡量数据分布形状的两个重要指标。
偏度:偏度衡量数据分布的不对称性。正偏斜表示右尾长的分布,而负偏斜表示左尾长的分布。零偏度表示完全对称的分布。
峰度:峰度衡量分布的“尾部”。高峰度表示具有重尾和尖峰(leptokurtic)的分布,而低峰度表示具有轻尾和平峰(platykurtic)的分布。正态分布的峰度为零(中峰态)。
了解数据分布的偏度和峰度可以为了解数据可变性的本质提供有价值的见解。偏度可以指示数据中的潜在异常值或异常,而峰度可以表明数据是重尾还是轻尾,这会影响某些统计分析。
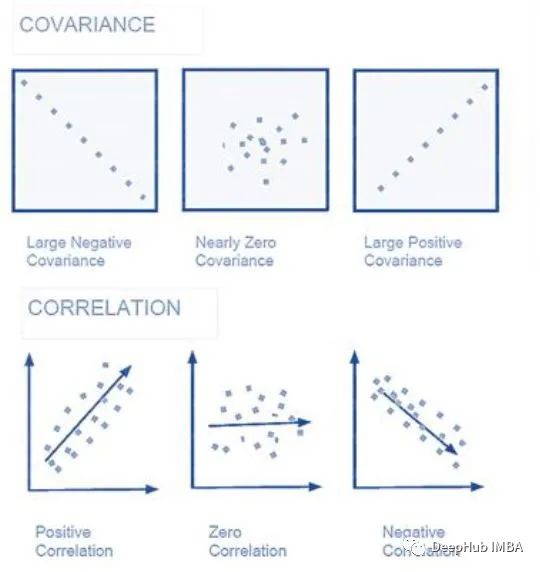
4、相关性和协方差
相关性和协方差是描述数据集中两个变量之间关系的两种度量。
相关性:相关性衡量两个变量之间线性关系的强度和方向。它的范围从-1到1,其中1表示完全正相关,-1表示完全负相关,0表示没有线性关系。
协方差:协方差是衡量两个变量一起变化的程度。与相关性不同,协方差不衡量关系的强度,其值不受约束,因此比相关性更难解释。
这两个度量对于理解数据中不同变量之间的关系至关重要,这有助于预测建模和其他统计分析。
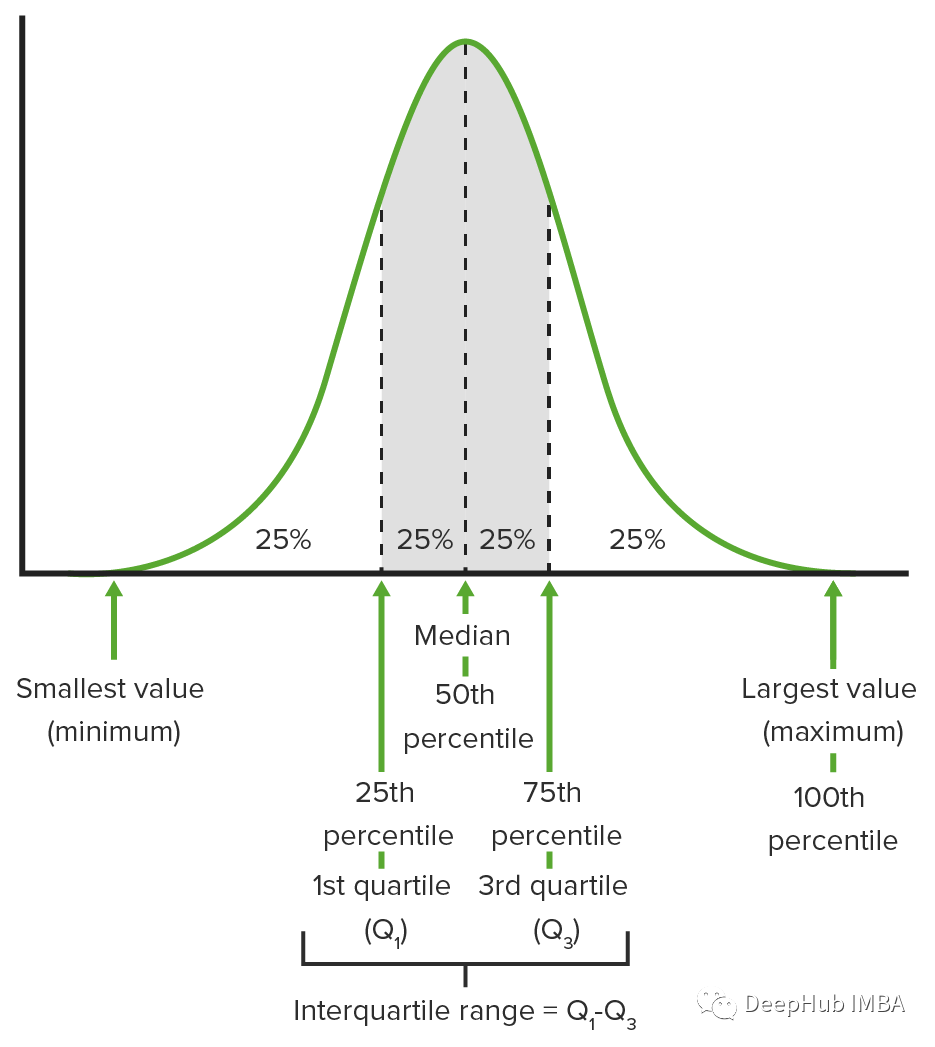
5、百分位数和四分位数
百分位数和四分位数是相对地位的衡量标准,可以更深入地了解数据集的分布。
百分位数:百分位数表示数据集中有多少观察值低于该值。例如,第 20 个百分位数是低于该值的 20% 的观测值。
四分位数:四分位数将排序数据集分成四个相等的部分。第一个四分位数 (Q1) 是第 25 个百分位数,第二个四分位数 (Q2) 是中位数或第 50 个百分位数,第三个四分位数 (Q3) 是第 75 个百分位数。
百分位数和四分位数对于了解数据的分布、识别异常值以及比较不同的数据点或数据集特别有用。
6、箱线图和直方图
箱线图和直方图是用于汇总数据的图形方法。
箱线图:箱线图(或箱型图)提供数据集中最小值、第一四分位数、中位数、第三四分位数和最大值的可视化摘要。它还可以指示数据中的异常值。所以箱线图非常适合比较不同组之间的分布。
直方图:直方图是数据集分布的图形表示。它是对连续变量概率分布的估计。直方图通过指示位于值范围内的数据点数量(称为箱)来提供数字数据的直观解释。
这些图形方法允许快速、直观地理解数据,使它们成为数据分析的宝贵工具。
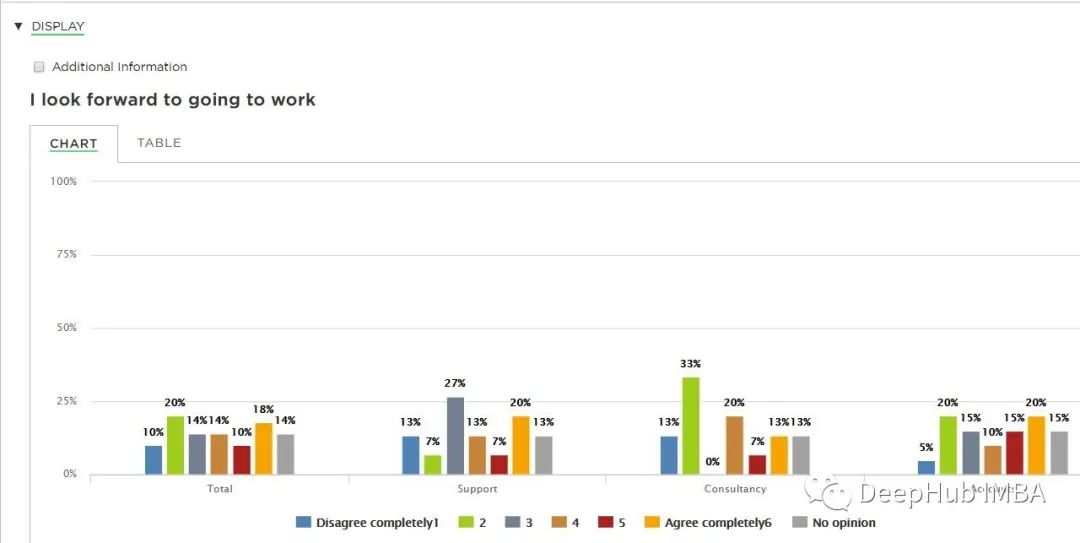
7、交叉制表
交叉表是一种常用的分类汇总数据的方法。它创建了一个显示变量频率分布的列联表。通过交叉表可以观察两个或多个分类变量之间关系的统计显着性。
交叉表在市场研究或任何其他使用调查或问卷的研究中特别有用。它们提供了两个或多个变量之间相互关系的基本图景,可以帮助找到它们之间的相互作用。
总结
对数据进行总结是数据分析过程中至关重要的一步。它提供了对数据集的全面理解,揭示了在原始的、未处理的数据中可能不明显的模式、关系和见解。本文描述的七种方法都提供了对数据的不同视角,提供了一个全面的总结,可以为决策提供信息。