

本文通过文本的挖掘,对人们在冠状病毒锁定期间正在做什么以及他们的感觉进行的探索性和情感分析
随着越来越多的国家宣布在全国范围内关闭,大多数人被要求留在家里隔离。我们来看看国外的人们在此“关闭”期间如何度过时间以及感觉如何,所以我分析了本文中的一些推文,看看国外友人到底都干什么。
数据获取和预处理
对于数据集,我使用txxxR库从推提取了20,000条带有“ #quarantine”和“ #stayhome”主题标签的推文。
将数据导入R后,我们需要对推文进行预处理并将其标记化为单词(令牌)以进行分析。
tweet_words <- tweets %>%
select(id,
screenName,
text,
created) %>%
mutate(created_date = as.POSIXct(created, format="%m/%d/%Y %H")) %>%
mutate(text = replace_non_ascii(text, replacement = "", remove.nonconverted = TRUE)) %>%
mutate(text = str_replace_all(text, regex("@\\w+"),"" )) %>%
mutate(text = str_replace_all(text, regex("[[:punct:]]"),"" )) %>%
mutate(text = str_replace_all(text, regex("http\\w+"),"" )) %>%
unnest_tokens(word, text)
从数据集中删除常见词和停用词
在对数据集进行标记和预处理之后,我们需要删除对分析无用的停用词,例如“ for”,“ the”,“ an”等。
#Remove stop words
my_stop_words <- tibble(
word = c(
"https","t.co","rt","amp","rstats","gt",
"cent","aaya","ia","aayaa","aayaaaayaa","aaaya"
),
lexicon = "txxxxr"
)#Prepare stop words tibble
all_stop_words <- stop_words %>%
bind_rows(my_stop_words)#Remove numbers
suppressWarnings({
no_numbers <- tweet_words %>%
filter(is.na(as.numeric(word)))
})#Anti-join the stop words and tweets tibbles
no_stop_words <- no_numbers %>%
anti_join(all_stop_words, by = "word")
我们还可以使用以下代码进行快速检查,以查看从数据集中删除了多少个停用词:
tibble(total_words = nrow(tweet_words),
after_cleanup = nrow(no_stop_words)
)
结果所示如下:
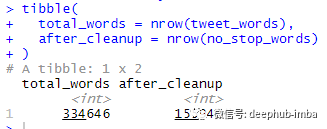
右边的数字(155,940)是删除停用词后剩余的令牌数。
现在我们的数据清洗已经完成了,可以进行处理了
词频分析
进行文本挖掘的常用方法是查看单词频率。首先,让我们看看推文中一些最常用的词。
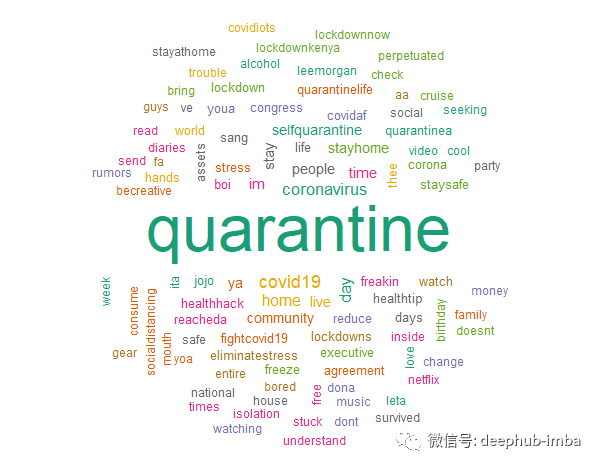
前五个词是:
隔离-出现13358次
Covid19 –出现1628次
冠状病毒-出现了1566次
天-出现1200次
家-出现了1122次
显然,隔离与冠状病毒/ COVID-19的状况有关,人们为了避免暴露于这种病毒而留在家里。
#Unigram word cloud
no_stop_words %>%
count(word) %>%
with(wordcloud(word, n, max.words = 100, random.order = FALSE,scale=c(4,0.7),
colors=brewer.pal(8, "Dark2"),random.color = TRUE))
最常见的正面和负面词
获得单词频率后,我们可以使用“ NRC”词典为每个单词分配一个标签(正或负)。然后,我们可以创建标记到标签的词云。
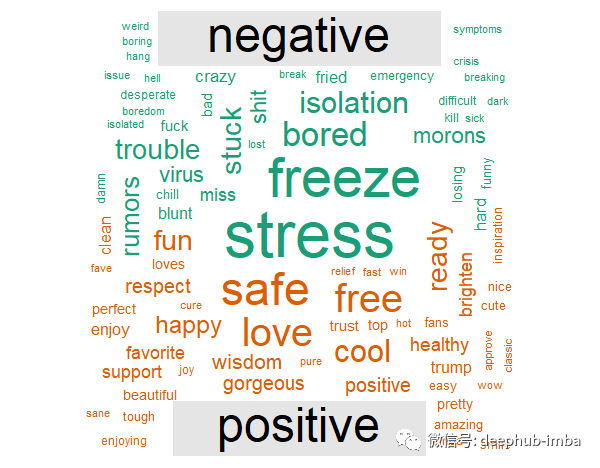
词云展示中,我们知道在隔离期间大多数人感到压力和无聊。但从好的方面来看,我们还了解到人们正在发出友善的信息,告诉其他人保持安全和健康。
#Positive and negative terms word cloud
no_stop_words %>%
inner_join(get_sentiments("bing"), by = c("word" = "word")) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = brewer.pal(2, "Dark2"),
max.words = 100)
情感分析
情感分析可帮助我们从文本数据中识别表达的文本和观点。它有助于我们了解人们对特定主题的态度和感受。
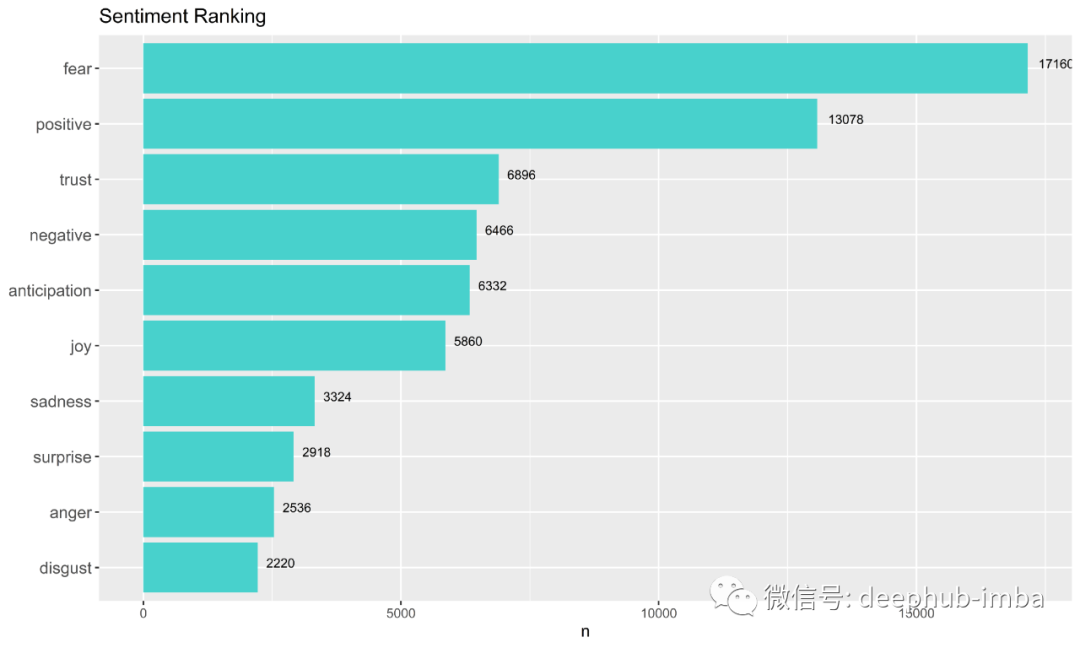
提取推文的情感排名
当人们担心冠状病毒时,我们大多数人仍然保持积极态度。令人惊讶的是,与否定词相比,人们在隔离期间发布了更多肯定的词。
#Sentiment ranking
nrc_words <- no_stop_words %>%
inner_join(get_sentiments("nrc"), by = "word")sentiments_rank <- nrc_words %>%
group_by(sentiment) %>%
tally %>%
arrange(desc(n))#ggplot
sentiments_rank %>%
#count(sentiment, sort = TRUE) %>%
#filter(n > 700) %>%
mutate(sentiment = reorder(sentiment, n)) %>%
ggplot(aes(sentiment, n)) +
geom_col(fill = "mediumturquoise") +
xlab(NULL) +
coord_flip() +
ggtitle("Sentiment Ranking") +
geom_text(aes(x = sentiment, label = n), vjust = 0, hjust = -0.3, size = 3)
情感内省-弄清人们的情感
通过使用“ NRC”词典,我们还可以将单词标记为八种类型的情感以及正面和负面的词语。
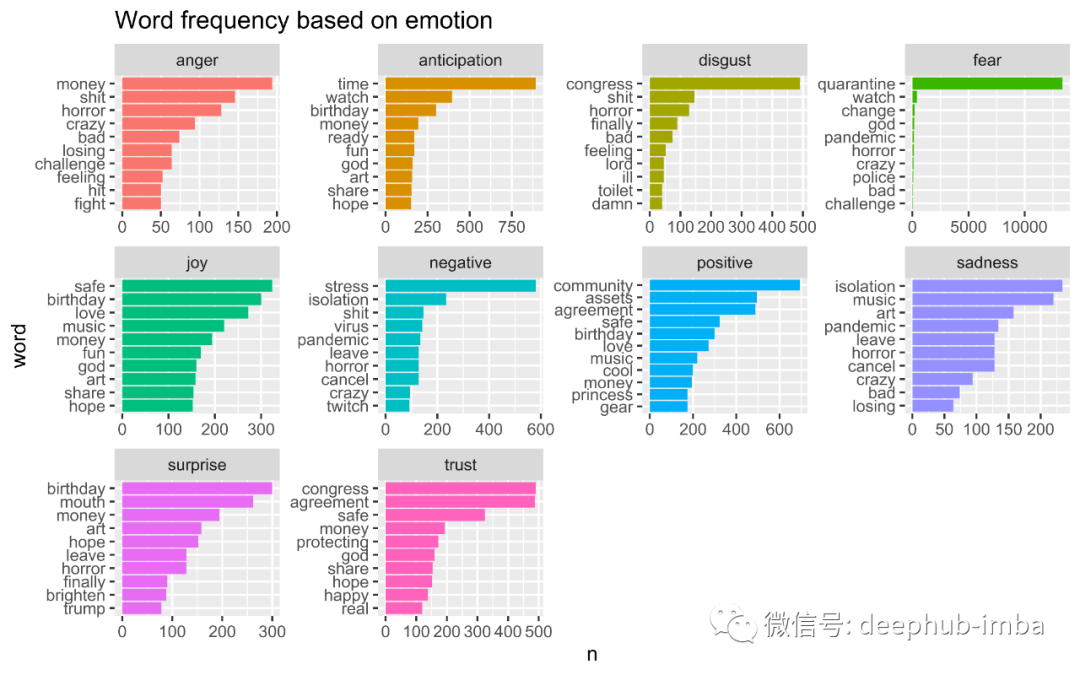
分配标签后,我们可以对情绪进行分组并生成一个单词频率图表,如下图所示。另请注意,可以在多个情感标签下找到某些术语,例如音乐和金钱。
基于上述情感标签的一些见解:
在此期间,人们正在努力争取金钱,(没有)生日,音乐和艺术品
人们在谈论政府:国会与协议
#Ten types of emotion chart
tweets_sentiment <- no_stop_words %>%
inner_join(get_sentiments("nrc"), by = c("word" = "word"))tweets_sentiment %>%
count(word, sentiment, sort = TRUE)#ggplot
tweets_sentiment %>%
# Count by word and sentiment
count(word, sentiment) %>%
# Group by sentiment
group_by(sentiment) %>%
# Take the top 10 words for each sentiment
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~ sentiment, scales = "free") +
coord_flip() +
ggtitle("Word frequency based on emotion")
可视化单词关系
进行文本挖掘时,单词关系的可视化很重要。通过将单词排列到“网络”图中,我们可以看到单词在数据集中如何相互连接。
首先,我们需要将数据集标记为双字(两个字)。然后,我们可以将单词排列到连接的节点的组合中以进行可视化。
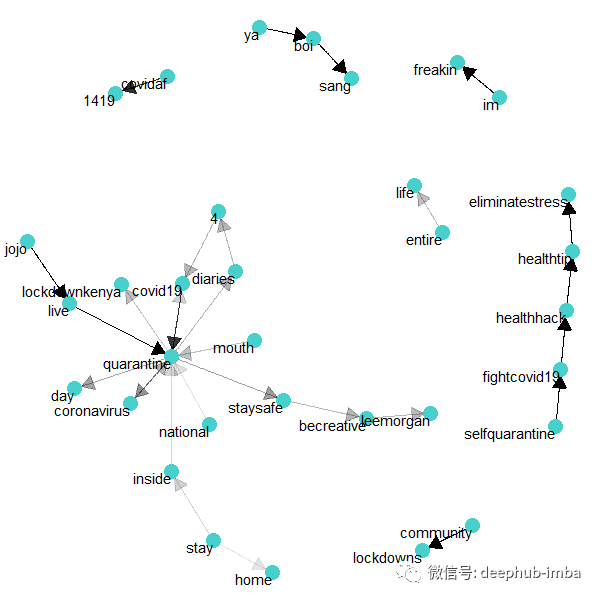
“隔离”数据集的网络图
#Tokenize the dataset into bigrams
tweets_bigrams <- tweets %>%
select(id,
# screenName,
text,
created) %>%
mutate(created_date = as.POSIXct(created, format="%m/%d/%Y %H")) %>%
mutate(text = replace_non_ascii(text, replacement = "", remove.nonconverted = TRUE)) %>%
mutate(text = str_replace_all(text, regex("@\\w+"),"" )) %>%
mutate(text = str_replace_all(text, regex("[[:punct:]]"),"" )) %>%
mutate(text = str_replace_all(text, regex("http\\w+"),"" )) %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)#Separate the bigrams into unigrams
bigrams_separated <- tweets_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")#Remove stop words
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% all_stop_words$word) %>%
filter(!word2 %in% all_stop_words$word)#Combine bigrams together
bigrams_united <- bigrams_filtered %>%
unite(bigram, word1, word2, sep = " ")
来自网络图的一些有趣的见解:
人们在隔离期间在推上写日记
在检疫期间,人们会听李·摩根(Lee Morgan)的爵士音乐
在检疫期间,Jojo的现场表演越来越受欢迎
自我隔离是与Covid-19对抗的一种方式,人们对健康技巧和消除压力的技巧很感兴趣
单词相关性分析—那么人们对社交距离的感觉如何?
隔离或远离社交可能会在情感上带来挑战,我想进一步了解人们在此期间的感受。
单词相关性使我们能够研究一对单词在数据集中一起出现的常见程度。它使我们对特定单词及其与其他单词的关联有了更多的了解。
通过词云,我们知道“压力”和“无聊”经常出现在我们的数据集中。因此,我提取了三个单词:“无聊”,“重音”,“卡住”以查看其单词相关性。
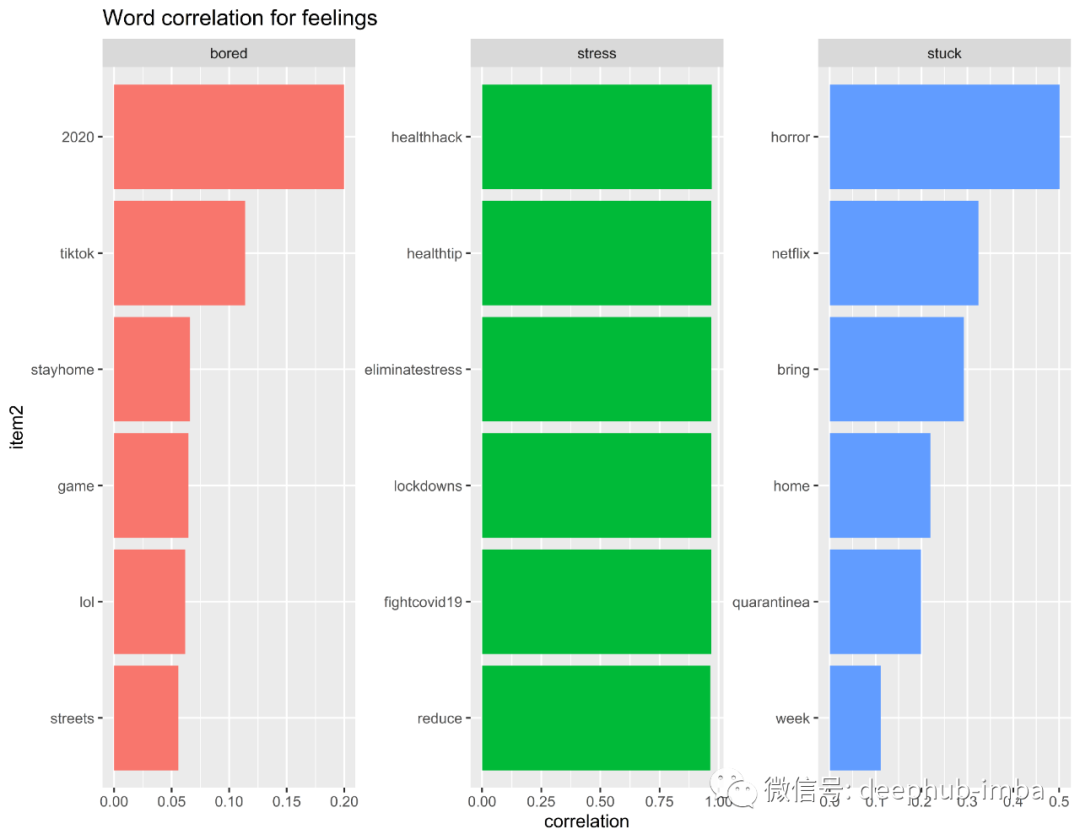
隔离期间,待在家里期间感觉的单词相关性
从“无聊”,“压力”和“卡住”的单词相关性中得出的见解:
人们在感到无聊时会使用TikTok(抖音的海外版)和游戏来消磨时间
乏味几乎可以概括大多数人在2020年的生活
造成压力,人们正在网上寻找减轻压力的提示
人们在家中“被困”时在Netflix上观看恐怖电影/连续剧
单词相关性分析—那么人们在家做什么呢?
为了了解人们在此居家和隔离期间在家里做什么,以度过自己的时间,我提取了三个词:“玩耍”,“阅读”和“观看”,以获取更多见解。
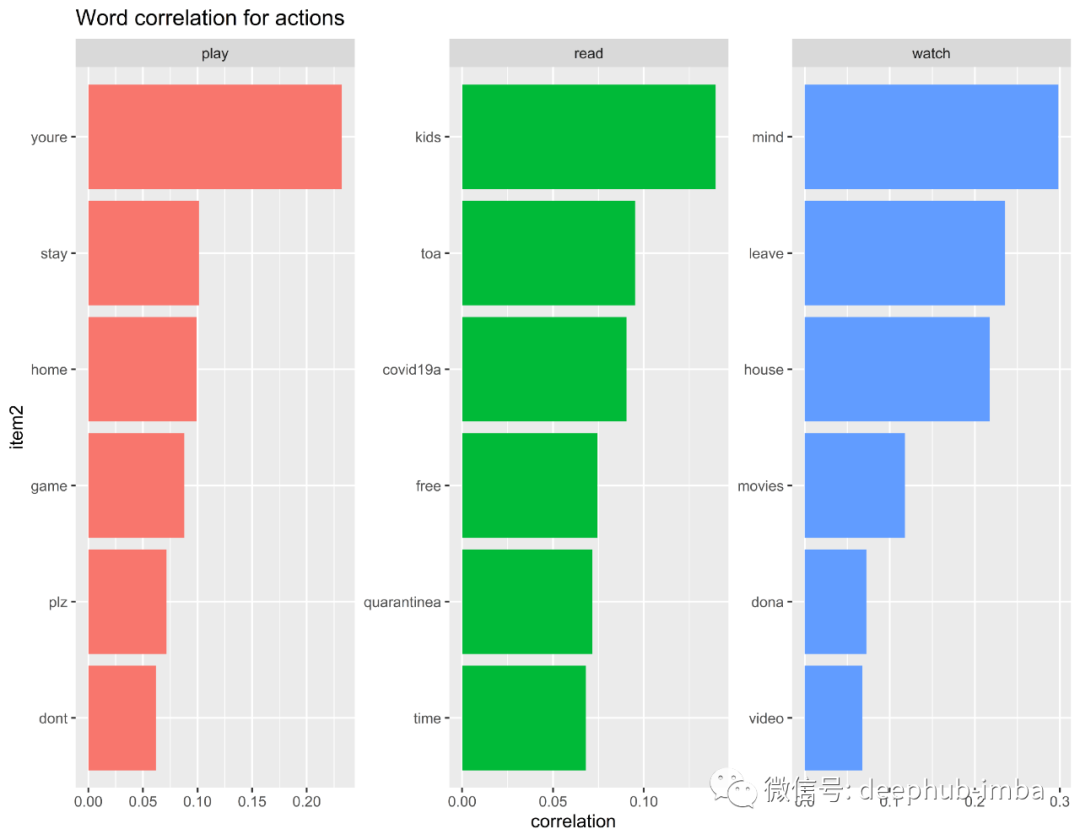
隔离期间,待在家里期间所采取措施的单词相关性
从“玩耍”,“阅读”和“观看”的词相关性中得出的见解:
大多数人可能会通过玩游戏,看电影和视频来度过自己的时间
人们花时间阅读他们的孩子
人们在此期间也终于有时间阅读
单词相关性分析-生日,金钱和社区…
情感标签图表中经常出现三个单词,分别是“生日”,“社区”和“金钱”。因此,我研究了该词与其他术语的相关性。
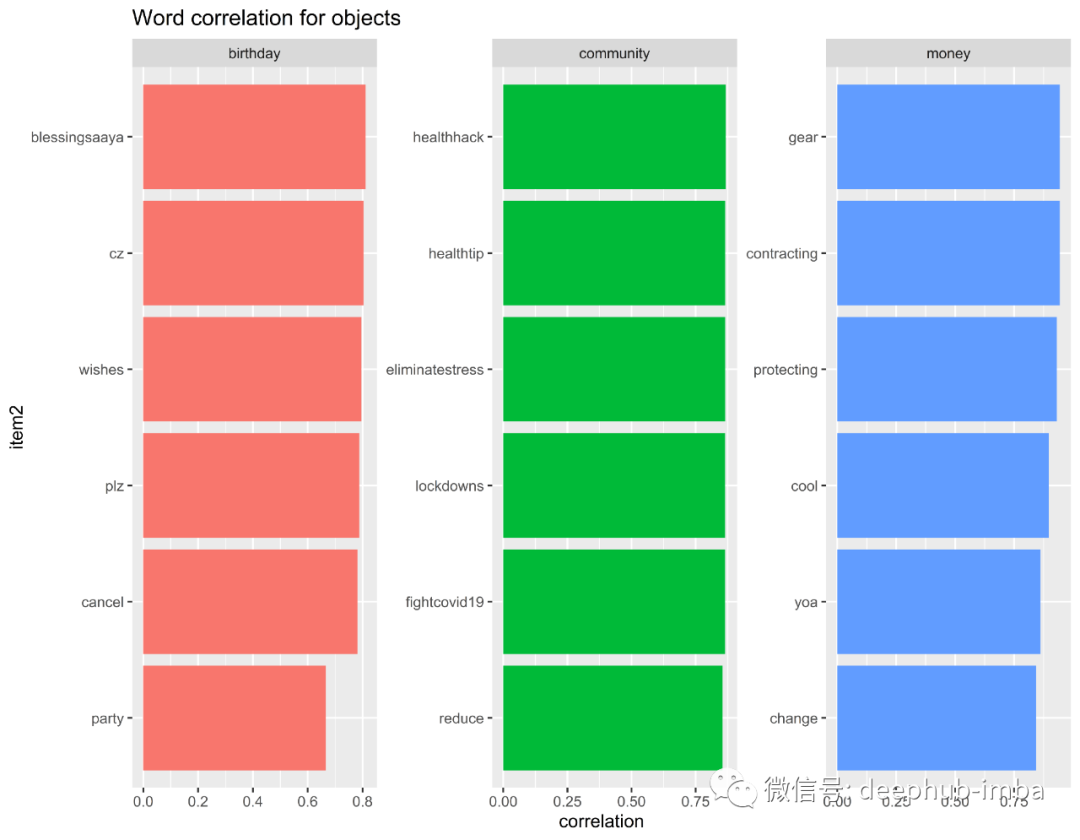
从“生日”,“社区”和“金钱”一词的相关性得出的见解:
生日聚会被取消。取而代之的是,人们在推上表达自己的愿望
人们同意金钱并不能阻止我们感染该病毒的观点
结论
我们能够深入了解人们在此冠状病毒关闭期间的感受以及他们在做什么,同时仍然遵循社会隔离规则。
我们提取的一些主要见解包括:
人们在冠状病毒情况下感到压力重重,但仍保持积极态度
在此居家和隔离期间,Tiktok和Netflix被广泛使用
人们将更多的时间花在与孩子,艺术,音乐和电影上
最后:以上主要基于对数据科学和机器学习的研究。我们不是卫生专业人员或流行病学家,因此本文的观点不应解释为专业建议。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********