
概要
Deepfakes 是一种合成视频,通过深度学习技术将原视频中的人脸进行替换,然后输出新的视频。
本文针对 Clay Sciences Video Annotation 平台上长达300分钟、总计449977帧的真实视频以及Deepfake视频进行了人工标注。然后通过 Keras 和 TensorFlow 在谷歌云进行了深度学习模型的训练,开发了 single shot multibox detector,用于自动检测视频是否是 deepfake。检测的准确度在部分情况下高达 100%。通过实现对 deepfake的识别,将能够减少由其带来的潜在负面影响。
引言
由于视频剪辑软件的流行及其简单易用的特点,Facebook、Instagram、Snapchat等社交平台充斥着剪辑视频。通过视频剪辑可以伪造一些实际上并没有发生过的人物事件。如果放任剪辑视频的大肆传播,会有潜在的误导舆论的可能。现在已经有相关的反面事例了。近期就在网上流传有关于美国众议院议长 Nancy Pelosi 和美国总统候选人 Joe Biden 的伪造视频,在视频中显示他们曾在公开演讲中发表种族主义言论,而这些伪造的视频在社交媒体中大肆传播。
而 Pelosi 和 Biden 类似的伪造视频是非常简单的,只需要选择性地对内容进行编辑就能够实现。而最近更受媒体关注的是一种更为先进的技术——Deepfakes。Deepfakes 通过人工智能技术将人脸叠加到原视频上。
Deepfakes 于 2017 年在网络上得到极大关注。2017年7月27日,Radiolab 的一期“Breaking News”中,对 Deepfakes 及其可能存在的风险进行了讨论,甚至自行开发了自己的 deepfakes。通过这一技术,一个和原视频毫不相干的人可以被设计为视频的主角。而这些合成的视频几乎不可能通过人眼识别出来。显然其潜在的风险是很大的,可能在社会的各个领域产生不良的影响。因此,开发能够识别视频真实性(针对 deepfake 技术)的程序是很有必要的。在本项目中,通过训练一个机器学习模型实现了对于真实视频和合成视频的识别检测。
此外同时需要注意还有另一种形式的 deepfake 技术——语音合成,能够改变音频内容,并且语音合成和视频合成是可以相结合的。而本项目目前只专注于视觉领域的 deepfake。
数据和方法
数据集
训练数据主要是从150分钟的真实视频和150分钟的合成视频中提取的449977帧图像,并且通过 Clay Sciences 平台根据是否是合成的对这些图像中的人脸添加了边框并进行了“真实”/“合成”的标记。然后将数据集划分为训练集(323202 帧图像)、验证集(80855 帧图像)和测试集(45920 帧图像),并且每个源视频生成的帧图像被划分进同一个数据集中。
方法
为了实现对于人脸真实性的识别检测,需要开发一个深度学习模型对图像中的人脸进行识别并判断:1)在图像中识别出人脸;2)判断人脸是否真实。该模型还需要能够检测出图像中具有多个人脸对象,因为单个视频可能存在多个人脸对象,甚至可能同时存在真实的人脸和合成的人脸。为了实现这一功能,本项目选择基于 Single Shot MultiBox Detector(SSD) 模型进行开发,SSD是一个能够针对图像中对象进行识别和标记的神经网络模型。具体地,通过 TensorFlow 编写相关代码,通过谷歌云计算进行相关训练。
本项目中,输入为 300x300 的图像,训练 15 个 epoch,每个 epoch 包含 11000 步,每个 batch 包含 32 个图像。而误差函数为 SSD 模型的损失函数,该损失函数包含两个部分:1) 目标定位(预测的边框和实际标注边框的差异);2) 目标分类(预测标签和实际标签的差异)。通过不断训练减少误差,使得模型逐渐学习关键特征。但是需要注意不能一味谋求减少训练误差,应该也要考虑模型的泛化能力,否则模型将出现过拟合的情况,在训练集以外的数据达不到理想的效果。而验证集能够帮助评估模型的泛化能力,一般而言,模型在验证集上的误差越小,则模型越好。
训练完成后,使用测试集进行模型性能的评价。通常采用针对每个对象(本项目为真实人脸/合成人脸)的 PR 曲线(precision-recall curves)评价目标检测模型的性能。PR 曲线中纵轴为分类器对正例的识别准确程度,横轴为对正例的覆盖能力。PR 曲线上的任一点表示模型预测的置信度,precision 越高、 recall 越低,则置信度越高,模型预测准确性越好。precision 越低、 recall 越高,则置信度越低,模型预测准确性越差,但是能够识别大多数目标。通过计算所有目标类别的平均准确度,可以作为模型的准确度指标(mAP)。
最终选择训练准确度最高的模型对视频图像进行目标识别和标签判断。
结果
模型训练和评估
经过不断训练,模型在第 8 个 epoch(88000 steps)时,使得验证集误差最小。此时训练集误差 2.5144,验证集误差 4.1434。而继续训练后,模型表现为过拟合:训练集误差持续减小,而验证集误差增加。通过计算 mAP 可以进一步验证模型是否过拟合。

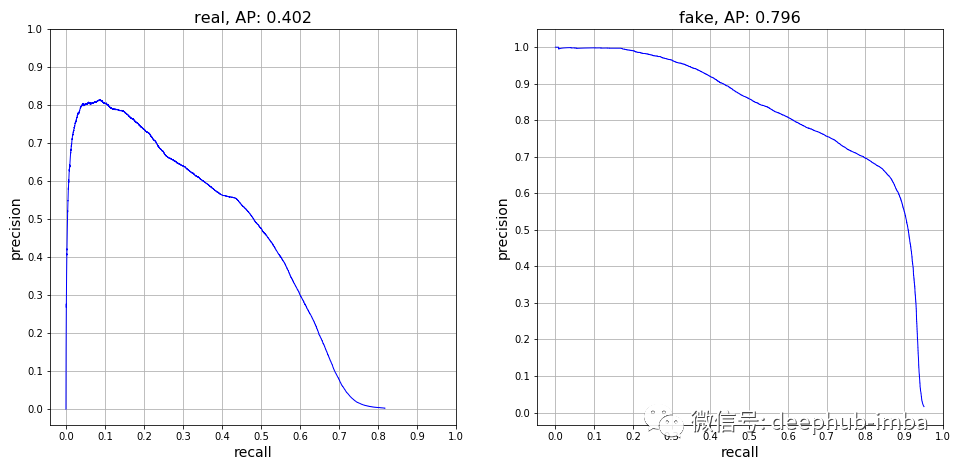
通过 epoch 8 的 SSD 模型 PR曲线可以看出,模型识别真实人脸的平均准确率为 40.2%,而识别合成人脸的平均准确率为 79.6%。
模型预测
经过训练的 SSD 模型被用于对测试集的图像进行真实人脸/合成人脸的识别。在所有测试集图像识别过程中,模型能够对大多人脸进行定位和判断,部分图像中将合成人脸识别为真实人脸,但是没有在任一图像将真实人脸识别为合成人脸。并且每次识别判断的置信度都同步输出在人脸的定位框中。


成功识别真实人脸


成功识别合成人脸


将合成人脸识别为真实人脸
最后将该模型用于未进行标注的 Deepfake 图像进行识别判断,也具有良好的总体表现。
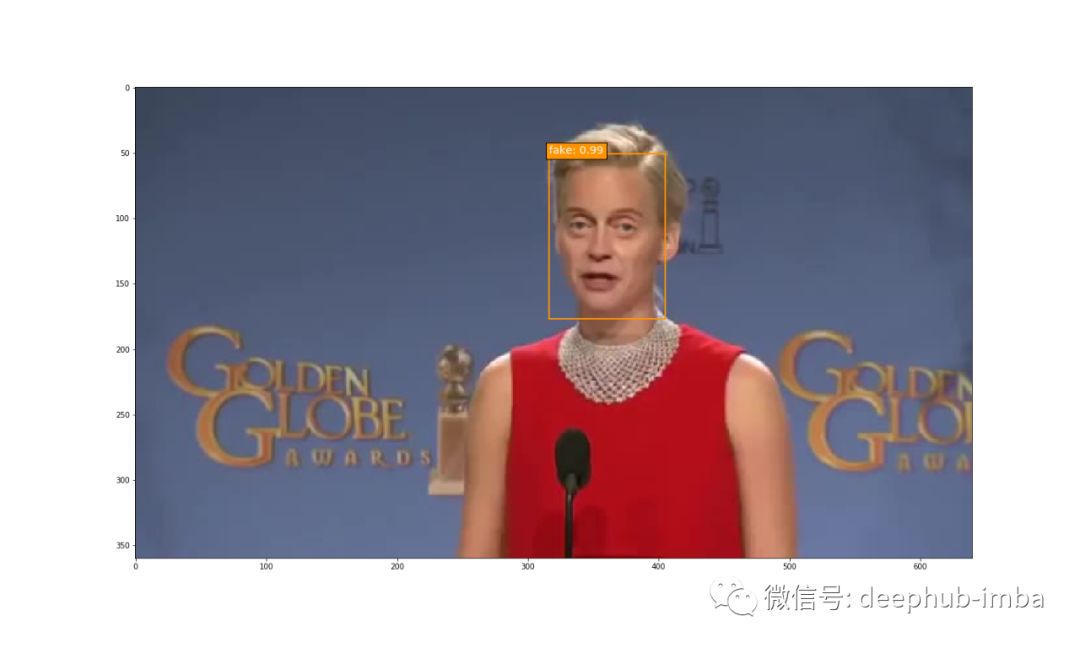

对未进行标注的数据集进行识别判断
讨论
要点
本项目的出发点在于训练一个机器学习模型用于分辨视频是否是通过技术手段合成的。本项目目前只是概念层面,所训练的模型虽然没有100%的准确率,但是具备有一定的判断视频真实性的能力。该模型尤其在识别合成人脸方面具有很好的效果。虽然它偶尔确实将合成人脸识别为真实人脸,但是当模型确实预测出合成人脸时,通常是正确的。通过 PR 曲线可以看到,模型在识别合成人脸方面具有很高的置信度,准确率接近 100%。同时,该模型还有很大的优化空间。通过 PR 曲线,发现模型在识别真实人脸方面不具有较高的置信度。因此为了更好地达到识别效果,还需要进一步地优化模型并训练。
尽管模型的效果并不完美,但是结果仍旧是很令人满意的。通过这个模型展示了目标检测模型可以用于减少剪辑视频的负面影响。
不足和展望
本项目除了上述不足以外,还存在着数据方面的问题。因为本项目中的图像是通过将每一帧单独提取出来并进行人为标注的,实际情况下视频的每一帧是连续的,并且具有一定的关联性,而这些特性对目标检测模型可能有一定的价值和影响。在后期的工作中,每帧图像不应该被单独提出了,而应该将视频作为一个整体,进而训练相关机器学习模型,判断整个视频是否是合成的。
此外,如前引言部分所述,本项目只是针对视频进行分析判断,而音频也存在 deepfake 的情况。所有一个可能的方向是将两者结合起来,共同进行判断。
值得注意的是,一些大型科技公司已经有开展“deepfake 检测挑战赛”,在竞赛中,选手需要通过技术方法对视频进行判断。主办方提供有视频和音频数据,该竞赛计划于2020年3月31日结束。参数选手如何完成相关工作很值得关注。