

作者:Ceyhun Derinbogaz
deephub 翻译组:孟翔杰

我的目标是创建一个对人有帮助并且超级简单的AI服务。做好GPT-2之后,我意识到它具有巨大的创作潜力,并且可以证明它在创作文字方面很有用。
因此,我创建了NameKrea,这是一个生成域名的AI。域名生成器业务长期以来一直很多,但是还没有看到这么优质的内容。
下面让我引导您逐步了解如何构建可生成域名和业务构想的AI服务!
介绍
从Majestic Millions的前100万个域名列表中取了大约100,000个网站之后,我对355M参数模型进行了微调。结果异常准确,同时又很有创意。看一下结果:

Namekrea AI生成的域名和元描述
如果有足够的训练数据,GPT-2就能理解上下文。为了训练它,我们需要大量数据。这可以通过抓取网站的元描述轻松完成。幸运的是,互联网上不乏网站:)
通过使用CSV文件读取每一行,可以微调GPT-2。在开始抓取之前,我们需要定义该算法可以理解的数据结构类型。为此,我采用了一种非常简单的方法,即为GPT-2的每个域提供1行文本并提供元描述。我们的训练数据中的一个条目将如下所示:
Create an account or log into Facebook. Connect with friends, family and other people you know. Share photos and videos, send messages and get updates. = @ = facebook.com
如您所见,我们首先输入给定上下文的元上下文,然后使用普通文本中不存在的定界符。您可以选择自然文本中通常不存在的任何内容。我选择了此定界符:-> = @ =
步骤一:抓取数据
如您所料,手动复制和粘贴网站的元上下文将花费大量时间。我们需要提出一种能够生成干净训练数据的抓取算法。
数据的清洁度很重要,因为大多数机器学习模型都依赖于质量。您的机器学习模型需要和您的训练数据一样好。因此:
在训练机器学习模型时,请切记:垃圾的进出!

那我所说的干净数据是什么意思呢?首先,GPT-2主要接受通过互联网收集的英语数据的培训。因此,我们需要确保以英语收集元上下文数据。其次,有很多带有元描述的网站,这些网站使用表情符号和不同的字符。我们不希望在最终收集的数据中有任何这些。
那我所说的干净数据是什么意思呢?首先,GPT-2主要接受通过互联网收集的英语数据。因此,我们需要确保以英语形式收集元上下文数据。其次,有很多带有元描述的网站使用表情符号和不同的字符。我们不希望在最终收集的数据中有任何这些字符。
我们设计一个抓取算法,它应该能够使用以下逻辑过滤来提取数据:
- 仅限英语
- 没有表情符号和类似的符号。只是单纯的英文文本。
- 仅收集一系列TLD(例如.com,.net,.org ..)的数据
- 速度快!我们需要进行多重处理,才能同时从多个域名中获取数据,如果速度不够,抓取数据将花费很多时间。
我们已经决定了主要需求,下面我们继续构建抓取程序!
Python有很多很棒的网站抓取的库,例如BeautifulSoup。它具有许多功能,可以立即开始抓取网站。我们将使用该库来获取域名,然后将其写入csv文件。
from bs4 import BeautifulSoup
import urllib3
import ssl
import pandas
from multiprocessing import Process
import tldextract
ssl._create_default_https_context = ssl._create_unverified_context
# Load data into pandas dataframe
df = pandas.read_csv('./data/majestic_million.csv')
# We will fetch and try to get the metadeffetch_meta(url):try:
res = req.request('GET', str(url),headers=headers, timeout=1)
soup = BeautifulSoup(res.data, 'html.parser')
description = soup.find(attrs={'name': 'Description'})
# If name description is big letters:if description == None:
description = soup.find(attrs={'name': 'description'})
if description == None:
print('Context is empty, pass')
meta_data = Noneelse:
content = description['content']
url_clean = tldextract.extract(url)
suffix = url_clean.suffix
domain = url_clean.domain
# Try to clean up websites with RU, JP, CN, PL we are trying to get only english trainig data.if suffix in ['com','org','ai','me','app','io','ly','co']:
print(url)
print(url_clean)
print(content)
meta_data = (str(content) + ' = @ = ' + str(domain) + '.' + str(suffix) + '\n')
# Domains with weird tld's are not in our priority. We would like to keep our training data as clean as possible.else:
print('Domain suffix is low priority ' + str(url))
meta_data = Nonereturn meta_data
except Exception as e:
print(e)
由于某些原因,Github Gist嵌入无法正常工作。所以请在namekrea的github仓库中查看源代码中的scraper.py
首先scraper.py从前100万个域名列表中读取域名,然后开始抓取数据。
注意:运行scraper.py后,您将最终获得来自5个不同线程的5个不同文件。因此,您需要将这些文件合并为1个,然后将其转换为csv文件,否则将无法进行微调。
scraper.py的.txt输出如下所示:
Create an account or log into Facebook. Connect with friends, family and other people you know. Share photos and videos, send messages and get updates. = @ = facebook.com
Search the world's information, including webpages, images, videos and more. Google has many special features to help you find exactly what you're looking for. = @ = google.com
Enjoy the videos and music you love, upload original content, and share it all with friends, family, and the world on YouTube. = @ = youtube.com
抓取数据完毕后,我们将继续执行下一步。
步骤二:微调
GPT-2模型非常大!中型预训练模型具有3.55亿个参数!使用普通的笔记本电脑CPU绝对不可能对这种架构进行微调。在我的设置中,我使用了2x1070Ti GPU,大约花了2个小时才能达到高质量的输出水平。
让我们看一下项目的总体架构,以了解如何训练该模型:
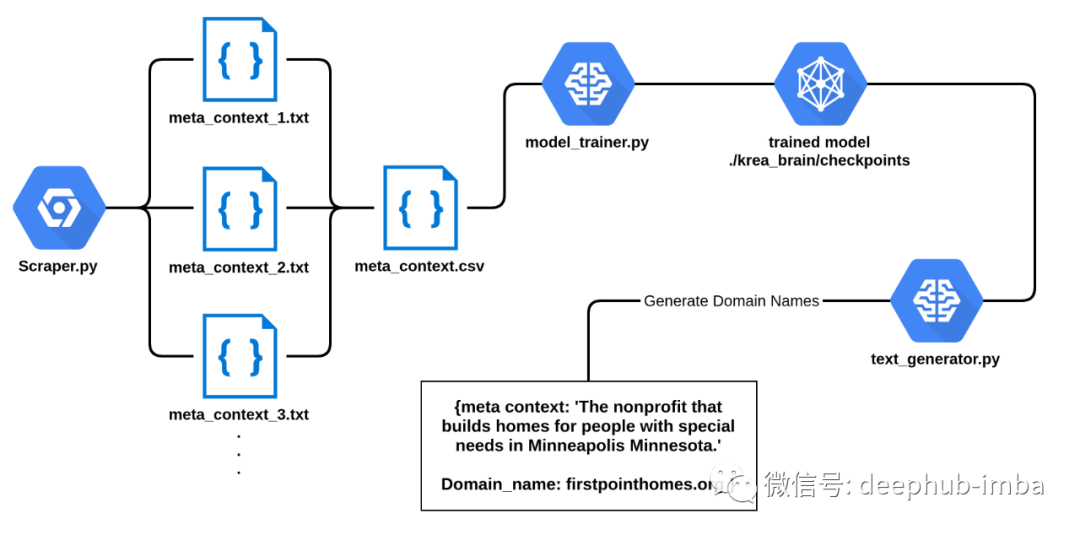
用于微调GPT-2以生成域名的工作流程的基本架构
因此,首先,我们将数据抓取并组合了文本文件到一个csv中,以使其可通过model_trainer.py脚本调用。
训练完成后,我们会将执行text_generator.py以随机生成域名。
步骤三:AI生成的域名
随机生成的域名很酷,但是如果我们不能向GPT-2发出提示,它就不是很有用。幸运的是,这可以通过前缀变量实现:
gpt2.generate(sess, model_name=model_name,
#run_name=run_name, checkpoint_dir=checkpoint_dir,
temperature=0.8, include_prefix=True, prefix='The best e-cigarette',
truncate='<|endoftext|>', nsamples=10, batch_size=2, length=128
)
结果非常好笑:
尼古丁含量超过99%的最佳电子烟。电子烟不只是一种电子烟。这是一个通讯APP。用作便携式蒸发器。或将其放在口袋中,并使用智能手机控制vape。Vaporsca是最好的电子烟比较网站。
vape还是通讯应用程序?我可以肯定地说这件事很有创意:D
GPT-2当然是令人惊讶的神经网络体系结构。没有GPT-2软件包,这个项目可能要花费更多的时间。
关注 deephub-imba 发送 gpt2-0327 即可获取项目源代码和网站地址
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********