

1.什么是主动学习?
这篇文章的主要目的是为了揭开主动学习的神秘面纱,以及将展示它与传统监督学习的不同之处。
首先,什么是主动学习?从本质上讲,主动学习是机器学习框架中的一种,它的算法能够通过与用户(专家或权威)交互的方式来对样本重新贴上真实的标签,其学习过程也被称为最优的实验设计。
研究主动学习的目的是为了去应对大量未标记的数据。考虑去训练一个能对猫和狗进行图像分类的模型,其中猫和狗都分别有数百万张图片,但这个分类模型并不需要用所有的图片去进行训练,毕竟有些图片比较模糊不是特别适合用作训练。另一个类似的应用场景是对Youtube视频的内容进行分类,因为它所需要训练的数据量也非常很大。
而与此相反的被动学习则是需要拿大量标记好的数据给算法进行训练,因此被动学习需要在标记整个数据集方面花费很大的精力。
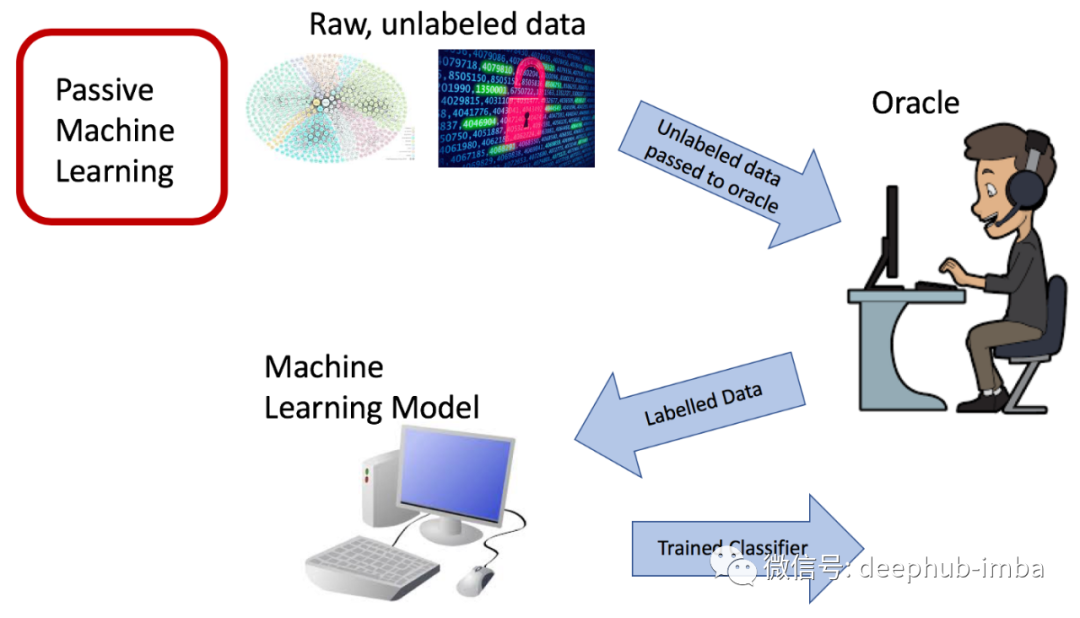
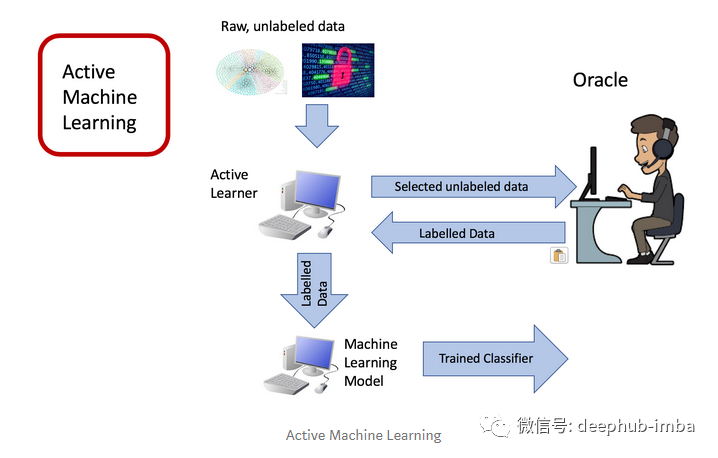
对于主动学习,我们可以选择采用一个类似众包的数据集,让专家有选择地给数据集中的一些数据贴上标签,但不必给整个数据集中的数据都贴上标签。主动学习算法根据某个度量值进行不断迭代选择数据,并将这些未标记的数据发送给权威,然后权威将其标记后并返回给算法。
在某些情况下,主动学习比随机抽样表现得更好。下图展示了一个线性分类的例子,说明了主动学习比随机抽样更有效。需要说明的是,下面的整个数据集(红色三角形和绿色圆形)是线性不可分的。
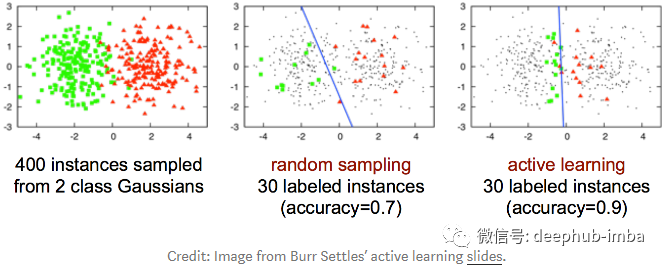
主动学习它能够认识到并不是所有的数据都是同等有价值的。由于用来训练的数据集是均匀抽样上来的,导致了这样的学习模型并不能代表每一种类别之间的划分。而主动学习则选择那些靠近边界的数据进行训练,使得它能够更加快速地训练出分类模型。之前的研究也表明,在多种图像的分类任务中,主动学习比传统的随机抽样更有效[1,2,3,4]。
为确定数据集中哪些数据更有价值,信息量更大,主动学习将数据的选择进行了简化。在主动学习中,信息量最大的数据通常是数据集中最不确定的数据,这也就需要研究出能够用来度量或量化不确定性的方法。
**2.**不同类型的主动学习框架
主动学习被认为是一种半监督学习,即介于无监督学习和监督学习之间。主动学习可以通过迭代的方式来增加被标记的训练集,这样也使得它更接近监督学习,但花费的成本或时间却只是使用全部数据进行训练的一小部分。
**2.1 **基于池的主动学习框架
在基于池的主动学习框架中,训练数据来自于未被标记的数据池中,之后由权威对从这个数据池中选择出来的数据进行标记。
**2.2 **基于流的主动学习框架
在基于流的主动学习框架中,所有的训练数据以数据流的形式发送给算法。每个数据都单独发送给算法进行训练,并且算法需要立即决定是否给这个数据贴上标签。即从数据池中选择训练数据给权威标记,在对下一个数据进行训练之前,当前训练数据的标签应该马上发送给算法。
**3.**不确定性
对于该如何去选择信息最为丰富的数据,可以考虑采用“不确定性”来进行度量。在基于池的样本中,主动学习算法选择最有价值的数据添加到训练集中。信息量最大的数据也即是对分类器而言最不确定的数据。选择最不确定的数据作为训练数据是原因:确定性越小的数据可能是越难进行分类的数据——特别是在边界附近的一些数据,而主动学习算法能通过观察这些数据来了解到更多的边界信息。
下面是四种在主动学习中常用的不确定性测量方法,常用来选择信息最为丰富的数据。
**3.1 **最小裕度不确定性
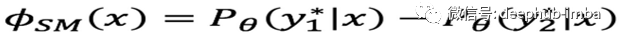
最小裕度不确定性(The smallest margin uncertainty,SMU)反映了最佳与次最佳的概率,即采用最可能类别的概率减去第二可能类别的概率。这个数值背后的意义在于:如果最可能类别的概率显著大于第二可能类别的概率的话,那么分类器就非常确定这个数据所属哪一类。同样地,如果最可能类别的概率并不比第二可能类别的概率大多少的话,那么分类器对这个数据所属哪一类就不那么确定了。因此,主动学习算法将选择SMU值最小的数据作为训练数据。
**3.2 **最小置信不确定性
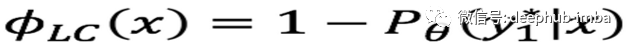
最小置信不确定性(Least confidence uncertainty, LCU)是选择分类器最不确定的数据作为训练数据。LCU的选择只看重那些确定性最小的类别,并选择它们作为训练数据。
**3.3 **熵减
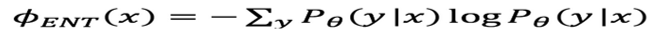
熵能够对随机变量的不确定性进行度量。在这个实验中,我们使用了香农熵。香农熵具有几个基本的性质:(1)均匀分布且具有最大的不确定性;(2)不确定性是独立事件的叠加;(3)增加一个概率为零的数据对其没有影响;(4)具有确定结果的事件对其没有影响[6,7]。将分类预测作为输出,我们可以测量这个输出的香农熵。
熵值越大暗示着不确定性的概率就越大[1]。在每个主动学习的步骤中,对于训练集中未标记的训练数据,主动学习算法都将会计算其熵超过所预测类别的概率,并选择熵最大的作为训练数据,因为熵最大的数据就是分类器对其类别最不确定的数据。
**3.4 **最大裕度不确定性
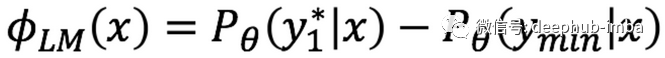
最大裕度不确定性(The largest margin uncertainty,LMU)反映了最佳与最差的概率,即采用最可能类别的概率减去最不可能类别的概率。这个数值背后的意义在于:如果最可能类别的概率显著大于最不可能类别的概率,那么分类器就十分确定这个数据所属哪一类。同样地,如果最可能类别的概率并不比最不可能类别的概率大多少,那么分类器对这个数据所属哪一类就不那么确定了。因此,主动学习算法将选择LMU值最小的数据作为训练数据。
**4.**算法
下面是基于池的主动学习算法。基于流的主动学习算法也可以类似地被写出来。
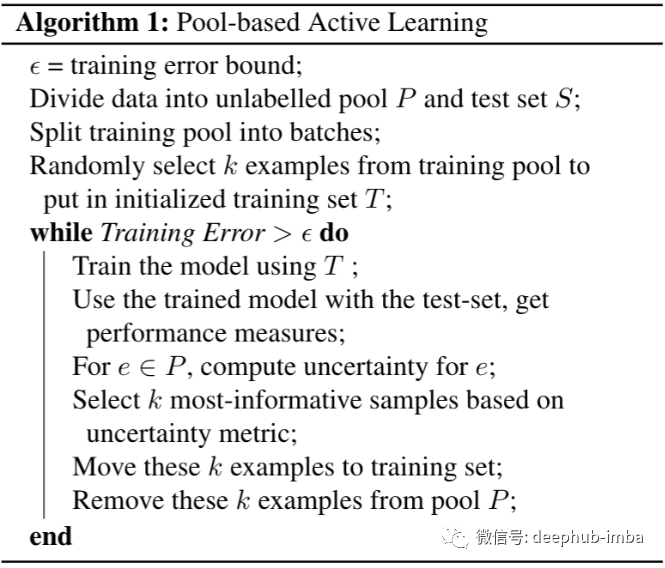
由于训练一个分类器需要大量的标签数据,这成为了之前大规模分类任务得到发展的一个主要瓶颈。但是现在主动学习的研究,使得我们可以策略性地选择特定的训练数据来减少一个分类器所需要训练的数量。
你或许会在文献中看到主动学习被称为最佳实验设计。因此,我将发布一个关于主动学习的教程,主动学习也是人工智能领域中一个非常令人兴奋和有前途的分支!
相关参考文献:
[1] A.J. Joshi, F. Porikli and N. Papanikolopoulos, “Multi-class active learning forimage classification,” 2009 IEEE Conference on Computer Vision and PatternRecognition, Miami, FL, 2009, pp. 2372–2379.
[2]Guo-Jun Qi, Xian-Sheng Hua, Yong Rui, Jinhui Tang and Hong-Jiang Zhang,“Two-Dimensional Active Learning for image classification,” 2008 IEEEConference on Computer Vision and Pattern Recognition, Anchorage, AK,2008, pp. 1–8.
[3] E.Y. Chang, S. Tong, K. Goh, and C. Chang. “Support vector machine concept-dependentactive learning for image retrieval,” IEEE Transaction on Multimedia,2005.
[4] A.Kapoor, K. Grauman, R. Urtasun and T. Darrell, “Active Learning with GaussianProcesses for Object Categorization,” 2007 IEEE 11th InternationalConference on Computer Vision, Rio de Janeiro, 2007, pp. 1–8.
[5] https://becominghuman.ai/accelerate-machine-learning-with-active-learning-96cea4b72fdb
[6] https://towardsdatascience.com/entropy-is-a-measure-of-uncertainty-e2c000301c2c
[7] L.M. Tiwari, S. Agrawal, S. Kapoor and A. Chauhan, “Entropy as a measure ofuncertainty in queueing system,” 2011 National Postgraduate Conference,Kuala Lumpur, 2011, pp. 1–4.
[8] https://towardsdatascience.com/active-learning-tutorial-57c3398e34d
作者:****Michelle Zhao
Deephub**翻译组:李爱(Li Ai)**
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********