

分类模型(分类器)是一种有监督的机器学习模型,其中目标变量是离散的(即类别)。评估一个机器学习模型和建立模型一样重要。我们建立模型的目的是对全新的未见过的数据进行处理,因此,要建立一个鲁棒的模型,就需要对模型进行全面而又深入的评估。当涉及到分类模型时,评估过程变得有些棘手。
在这篇文章中,我会做详细的介绍,说明如何评估一个分类器,包括用于评估模型的一系列不同指标及其优缺点。
我将介绍的概念包括:
- 分类精度(Classification Accuracy)
- 混淆矩阵(Confusion matrix)
- 查准率与查全率(Precision & recall)
- F1度量(F1 score)
- 敏感性与特异性(Sensitivity & specificity)
- ROC曲线与AUC(ROC curve & AUC)
分类精度(Classification Accuracy)
分类精度显示了我们所做的预测中有多少是正确的。
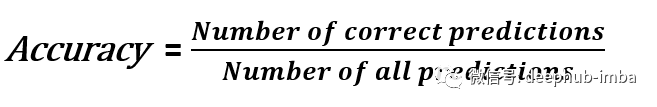
在很多情况下,它表示了一个模型的表现有多好,但在某些情况下,精度是远远不够的。例如,93%的分类精度意味着我们正确预测了100个样本中的93个。在不知道任务细节的情况下,这似乎是可以接受的。
假设我们正在创建一个模型来对不平衡的数据集执行二分类。93%的数据属于A类,而7%属于B类。
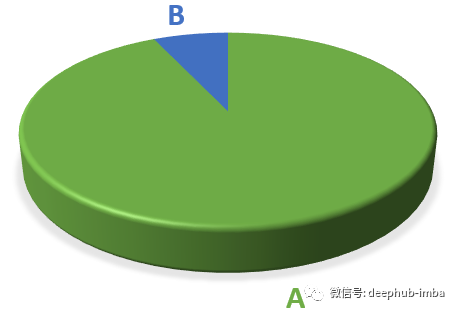
我们有一个只把样本预测为A类的模型,其实我们很难称之为“模型”,因为它只能预测A类,没有任何计算推理。然而,由于93%的样本属于A类,我们的模型的分类精度是93%。
如果正确检测B类至关重要,而且我们无法承受把B类错误地预测为A类的代价(如癌症预测,把癌症病人预测为正常人的后果是不可想象的),该怎么办?在这些情况下,我们需要其他指标来评估我们的模型。
混淆矩阵(Confusion Matrix)
混淆矩阵不是评估模型的一种数值指标,但它可以让我们对分类器的预测结果有深刻的理解。学习混淆矩阵对于理解其他分类指标如查准率和查全率是很重要的。
相比分类精度,混淆矩阵的使用意味着我们在评估模型的道路上迈出了更深的一步路。混淆矩阵显示了对每一类的预测分别是正确还是错误。对于二分类任务,混淆矩阵是2x2矩阵。如果有三个不同的类,它就是3x3矩阵,以此类推。
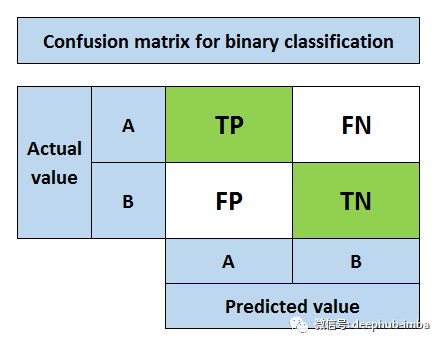
假设A类是正类,B类是反类。与混淆矩阵相关的关键术语如下:
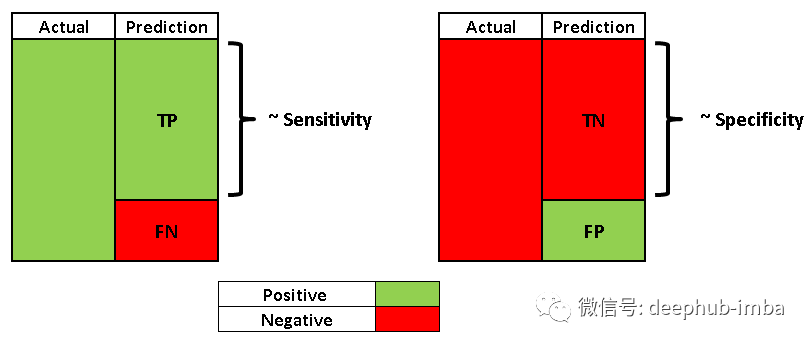
- 真阳性(TP):把正类预测为正类(没问题)
- 假阳性(FP):把负类预测为正类(不好)
- 假阴性(FN):把正类预测为负类(不好)
- 真阴性(TN):把负类预测为负类(没问题)
我们期望的结果是我们的预测能够与真实类别相匹配。这些术语看起来有些让人头晕眼花,但是你可以想一些小技巧来帮助你记住它们。我的诀窍如下:
第二个字表示模型的预测结果
第一个字表示模型的预测是否正确
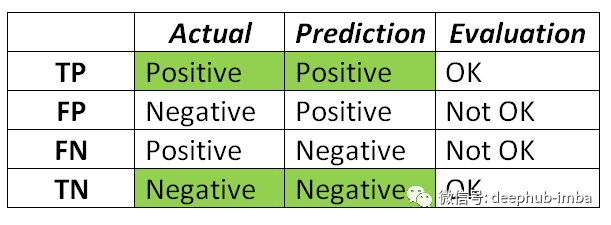
假阳性也称为I类错误,假阴性也称为II型错误。
混淆矩阵的用途是计算查准率和查全率。
查准率与查全率(Precision & Recall)
查准率(又称准确率)和查全率(又称召回率)相比分类精度来说更进一步,使我们对模型评估有了更加具体的了解。选择哪一个指标取决于任务要求与我们的目标。
查准率衡量的是我们的分类器预测正类的准确性
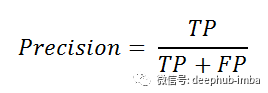
查准率的重点在于准确地预测正类,它显示了我们预测的正类中有多少是真正的正类。
查全率衡量的是我们的分类器把正类预测出来的能力
查全率的重点是把真正的正类预测出来,它显示了我们的分类器能够把真正的正类预测得多全面。
我们不可能同时提高查准率与查全率,因为这二者仿佛鱼和熊掌,不可兼得。提高查准率会降低查全率,反之亦然。根据任务的不同,我们可以最大限度地提高查准率或查全率中的某一个。对于垃圾邮件的检测等任务,我们尝试最大限度地提高查准率,因为我们希望在电子邮件被检测为垃圾邮件时最好检测地很准确,因为我们不想让有用的电子邮件被错误地标记成垃圾邮件。另一方面,对于肿瘤的检测等任务,我们需要最大化查全率,因为我们希望尽可能多地检测出来患者体内的阳性。
还有一种指标把查准率与查全率结合了起来,这就是F1度量。
F1度量(F1 Score)
F1度量是查准率与查全率的调和平均的倒数。

对于类别不平衡的分类问题,F1度量比分类精度更有用,因为它同时考虑了假阳性和假阴性。最佳的F1度量值是1,最差则是0。
敏感性与特异性(Sensitivity & Specificity)
敏感性,也称为真阳性率(TPR),与查全率实际上是相同的。因此,它测量的是被正确预测出来的正类占全部正类的比例。
特异性与敏感性相似,但相比之下它更着眼于阴性类别。它测量的是被正确预测出来的负类占全部负类的比例。
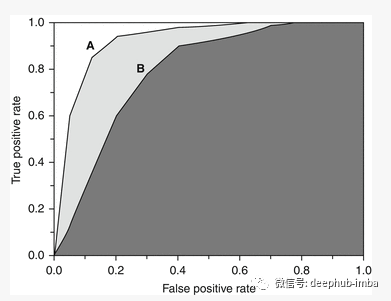
ROC曲线与AUC(ROC curve & AUC)
ROC曲线(受试者操作特性曲线)和AUC(曲线下面积)这两个指标最好用逻辑回归实例来解释。
Logistic回归给出了样本为正的概率。然后我们为这个概率设置一个阈值来区分正类和负类。如果概率高于阈值,则将样本分类为正。因此,不同样本的分类结果会随着阈值的改变而变化,进而改变查准率与查全率等指标。
ROC曲线通过组合不同阈值取值下的混淆矩阵,总结了模型在不同阈值下的性能。ROC曲线的x轴为真阳性率(TPR,即敏感性),y轴为假阳性率(FPR,定义为1 - 特异性)。
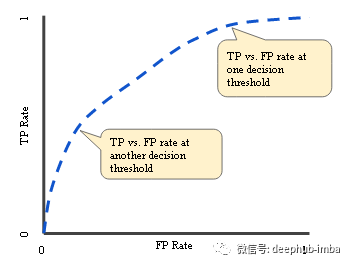
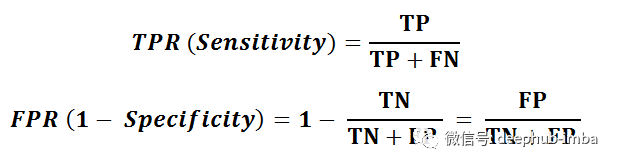
如果阈值设置为0,则模型将所有样本预测为正值。在这种情况下,TPR为1,然而,FPR也是1,因为没有负类预测。如果阈值设置为1,则TPR和FPR都将变为0。因此,将阈值设置为0或1并不是一个好的选择。
我们的目标是提高真阳性率(TPR),同时保持较低的假阳性率(FPR)。正如我们在ROC曲线上看到的,随着TPR的增加,FPR也增加。所以我们要决定我们能容忍多少误报。
相比在ROC曲线上寻找一个最佳阈值,我们可以使用另一种称为AUC(曲线下面积)的指标。AUC是ROC曲线下(0,0)到(1,1)之间的面积,可以用积分计算。AUC基本上显示了模型在所有阈值下的性能。AUC的最佳可能值是1,表示这一个完美的分类器。AUC越接近1,分类器越好。在下图中,分类器A比分类器B好。
总结
“没有免费的午餐”定理在分类模型评估上也是适用的,并非所有任务都有一个最佳且容易找到的选择。我们需要明确我们的需求,并根据这些需求选择合适的评价指标。
作者:Soner Yildirim
deephub翻译组:Alexander Zhao
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********