
特征工程是构建机器学习模型最重要的方面之一。在本文中,我将通过一个实际示例讨论如何从 DateTime 变量中提取新特征以提高机器学习模型的准确性。
从日期中提取特征
一些数据集提供了日期或日期时间字段,通常在为机器学习模型构建输入特征时会被删除(除非您正在处理时间序列,显然 😃)。
但是,DateTime 是可用于提取新特征的,这些新特征可以添加到数据集的其他可用特征中。
日期由日、月和年组成。从这三个部分中,至少可以提取四个不同的特征:
- 一年中的一天或一个月中的一天或一周中的一天
- 一年中的月份
- 季节
- 年
除了年以外,所有的特征都可以两部分:正弦和余弦,这样可以获得时间的周期性,例如 1 月 1 日接近 12 月 31 日。
一年中的一天或一个月中的一天或一周中的一天
一年中的某一天是指 1 到 365(或 366)之间的数字。当你有一个粒度精细的数据集并且在天数内具有平衡分布时可以使用这个特征,否则使用此特征可能会产生过拟合。
在 Python 中,一年中的某一天可以计算如下:
import numpy as np
current_date = "2022-01-25 17:21:22"
cdate = datetime.strptime(current_date, '%Y-%m-%d %H:%M:%S')
day_sin = np.sin(2 * np.pi * cdate.timetuple().tm_yday/365.0)
day_cos = np.cos(2 * np.pi * cdate.timetuple().tm_yday/365.0)
对于数据集中更稀疏的日期值,建议将日期用作月份或星期几。
一年中的月份
一年中的月份指的是 1 到 12 之间的数字。如果 DF中有 DateTime 列,则可以按如下方式提取一年中的月份:
df['month_sin'] = np.sin(2 * np.pi * df['date_time'].dt.month/12.0)
df['month_cos'] = np.cos(2 * np.pi * df['date_time'].dt.month/12.0)
季节
季节是一个分类变量,包括以下值:春季、夏季、秋季和冬季。
在 Python 中,可以按照 Stackoverflow 上这个有趣的回复中的说明提取季节。(https://stackoverflow.com/questions/16139306/determine-season-given-timestamp-in-python-using-datetime)
或者可以将季节视为数字特征。
年
当必须预测未来的值时,年份作为输入特征并不是很有用。但是为了完整起见本篇文章还是将描述如何将其作为输入特征加以利用。
如果数据集包含多年,则可以使用年份。它可以是分类变量或数值变量,具体取决于需求。
如果 Pandas 有 DateTime 列,则可以按如下方式提取年份:
df['year'] = df['date_time'].dt.year
从时间中提取特征
根据数据集的粒度,可以从 DateTime 列中提取不同级别的时间特征(小时、分钟、秒……)。但是,最频繁的时间特征是以小时为单位。时间特征应分割为正弦和余弦以反映数据循环性(例如 23:59 接近 0:01)。
在 Python 中,给定一个 DateTime 变量,可以按如下方式提取一个小时:
hour_sin = np.sin(2 * np.pi * cdate.hour/24.0)
hour_cos = np.cos(2 * np.pi * cdate.hour/24.0)
一个实际的例子
该示例利用了 Kaggle 上的天气数据集,该数据集在 CC0:公共领域许可证下。
此示例的目的是构建一个多类分类器,该分类器根据输入特征预测天气状况(由数据集的摘要列给出)。我计算了两种情况的准确性:有和没有 DateTime特征。
加载数据集
该数据集可在 Kaggle 上获得。并且通过 Pandas加载:
import pandas as pd
df = pd.read_csv('../input/weather-dataset/weatherHistory.csv')
该数据集包含 96,453 条记录和 12 列。
探索性数据分析
现在,我删除了对预测没有太大影响的变量。所有行的 Loud Cover 都是相同的,所以也可以删除它。
df['Loud Cover'].value_counts()
0.0 96453
Name: Loud Cover, dtype: int64
我还可以删除 Daily Summary 列,因为它只包含文本。
df.drop(['Daily Summary','Loud Cover'],axis=1,inplace=True)
最后,处理缺失值:
df.isnull().sum()
给出以下输出:
Formatted Date 0
Summary 0
Precip Type 517
Temperature (C) 0
Apparent Temperature (C) 0
Humidity 0
Wind Speed (km/h) 0
Wind Bearing (degrees) 0
Visibility (km) 0
Pressure (millibars) 0
Precip Type 列包含一些缺失值,也删除它。
df.dropna(inplace=True)
数据清洗
首先,我将分类数据转换为数值数据:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Precip Type']=le.fit_transform(df['Precip Type'])
df['Summary']=le.fit_transform(df['Summary'])
然后,特征标准化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[df.columns[2:]] = scaler.fit_transform(df[df.columns[2:]])
从第三列开始,因为我没有标准化前两列(日期时间和摘要)。
特征工程
现在,准备提取一年中的日期和时间。我定义了一个函数,在给定日期的情况下,提取正弦和天数和小时数的余弦:
import numpy as np
from datetime import datetime
def discretize_date(current_date, t):
current_date = current_date[:-10]
cdate = datetime.strptime(current_date, '%Y-%m-%d %H:%M:%S')
if t == 'hour_sin':
return np.sin(2 * np.pi * cdate.hour/24.0)
if t == 'hour_cos':
return np.cos(2 * np.pi * cdate.hour/24.0)
if t == 'day_sin':
return np.sin(2 * np.pi * cdate.timetuple().tm_yday/365.0)
if t == 'day_cos':
return np.cos(2 * np.pi * cdate.timetuple().tm_yday/365.0)
现在提取新特征:
date_types = ['hour_sin', 'hour_cos', 'day_sin', 'day_cos']
for dt in date_types:
df[dt] = df['Formatted Date'].apply(lambda x : discretize_date(x, dt))
df.drop(['Formatted Date'],axis=1,inplace=True)
计算特征之间的相关性,以检查是否存在一些高度相关的特征。在这种情况下,可以删除两个相关的特征之一。
df.corr()
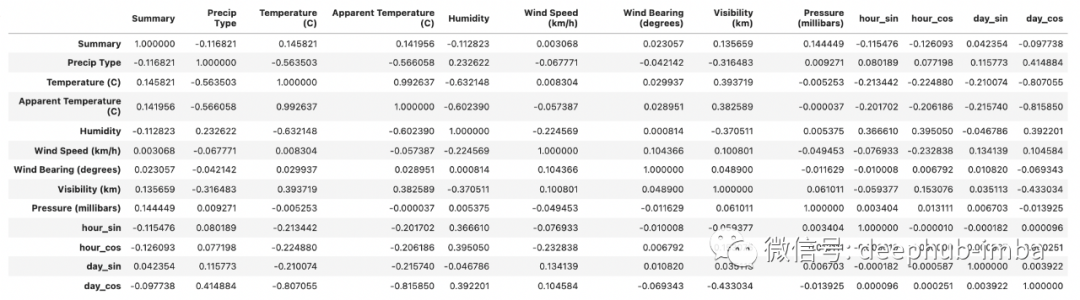
Apparent Temperature 和Temperature 高度相关,因此我可以删除Apparent Temperature:
df.drop(['Apparent Temperature (C)'],axis=1,inplace=True)
训练测试拆分
我在 X 和 y 中拆分数据,然后在训练和测试集中:
from sklearn.model_selection import train_test_split
X = df.iloc[:,1:]
y=df.iloc[:,0]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1)
模型训练和评估
我测试了两种模型,一种具有 DateTime 特征,另一种没有。首先,使用 DateTimeFeatures 训练模型:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=32,n_estimators=120,random_state=1)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
计算精度:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
0.6695389319342622
现在,在没有 DateTime特征的情况下训练模型:
model = RandomForestClassifier(max_depth=32,n_estimators=120,random_state=1)
model.fit(X_train[X_train.columns[:-4]],y_train)
y_pred = model.predict(X_test[X_test.columns[:-4]])
accuracy_score(y_test, y_pred)
0.5827108161634411
具有 DateTime 特征的模型如何优于其他模型。
总结
以上就是如何从机器学习模型中提取 DateTime 特征!本文中描述的实际示例表明,日期时间特征的存在可以提高机器学习模型的性能。
下面带来一个具有挑战性的问题:
DateTime 功能是否会引入过拟合?
本文作者:Angelica Lo Duca