
Deephub
更多文章请关注公众号:Deephub-IMBA
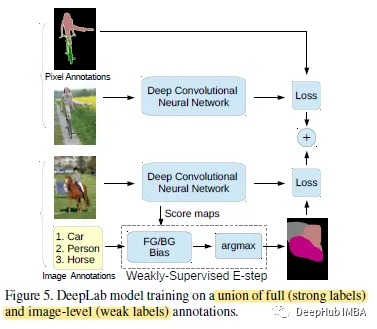
用于语义图像分割的弱监督和半监督学习:弱监督期望最大化方法
这篇论文只有图像级标签或边界框标签作为弱/半监督学习的输入。使用期望最大化(EM)方法,用于弱/半监督下的语义分割模型训练。

10个图像处理的Python库
在这篇文章中,我们将整理计算机视觉项目中常用的Python库,如果你想进入计算机视觉领域,可以先了解下本文介绍的库,这会对你的工作很有帮助。

本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama
在本文中,我将演示如何利用LLaMA 7b和Langchain从头开始创建自己的Document Assistant。
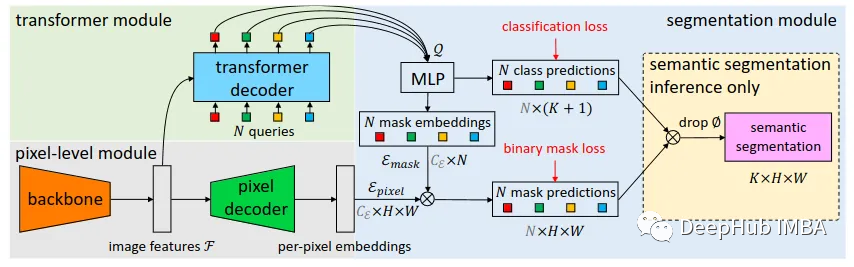
MaskFormer:将语义分割和实例分割作为同一任务进行训练
本文中将介绍Facebook AI Research在21年发布的一种超越这些限制的实例分割方法MaskFormer。

轻量级的深度学习框架Tinygrad
Tinygrad是一个轻量级的深度学习库,它提供了一种简化和直观的方法来理解和实现神经网络。在本文中,我们将探讨Tinygrad及其主要功能,以及它如何成为那些开始深度学习之旅的人的有价值的工具。
PromptBench:大型语言模型的对抗性基准测试
PromptBench是微软研究人员设计的一个用于测量大型语言模型(llm)对对抗性提示鲁棒性的基准测试。这个的工具是理解LLM的重要一步,随着这些模型在各种应用中越来越普遍,这个主题也变得越来越重要。

Video-LLaMa:利用多模态增强对视频内容理解
本文将重点介绍称为video - llama的多模态框架。Video-LLaMA旨在使LLM能够理解视频中的视觉和听觉内容。

图解transformer中的自注意力机制
本文将将介绍注意力的概念从何而来,它是如何工作的以及它的简单的实现。
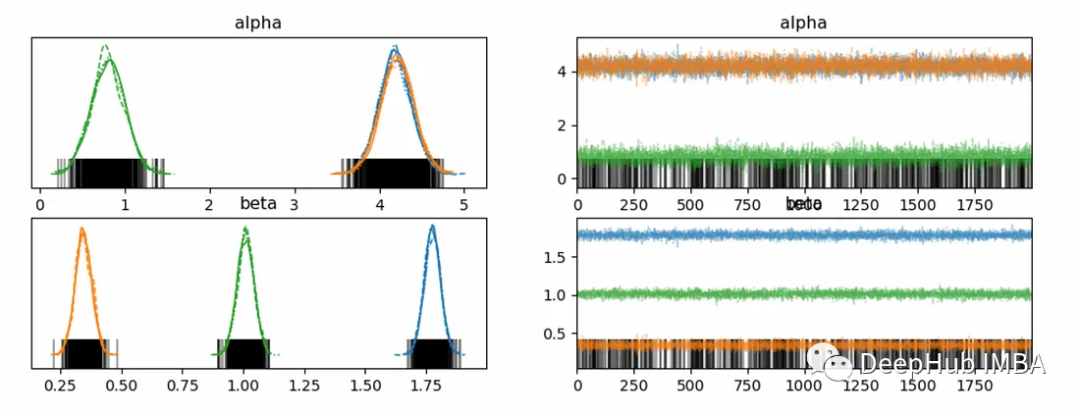
使用PyMC进行时间序列分层建模
在统计建模领域,理解总体趋势的同时解释群体差异的一个强大方法是分层(或多层)建模。这种方法允许参数随组而变化,并捕获组内和组间的变化。在时间序列数据中,这些特定于组的参数可以表示不同组随时间的不同模式。
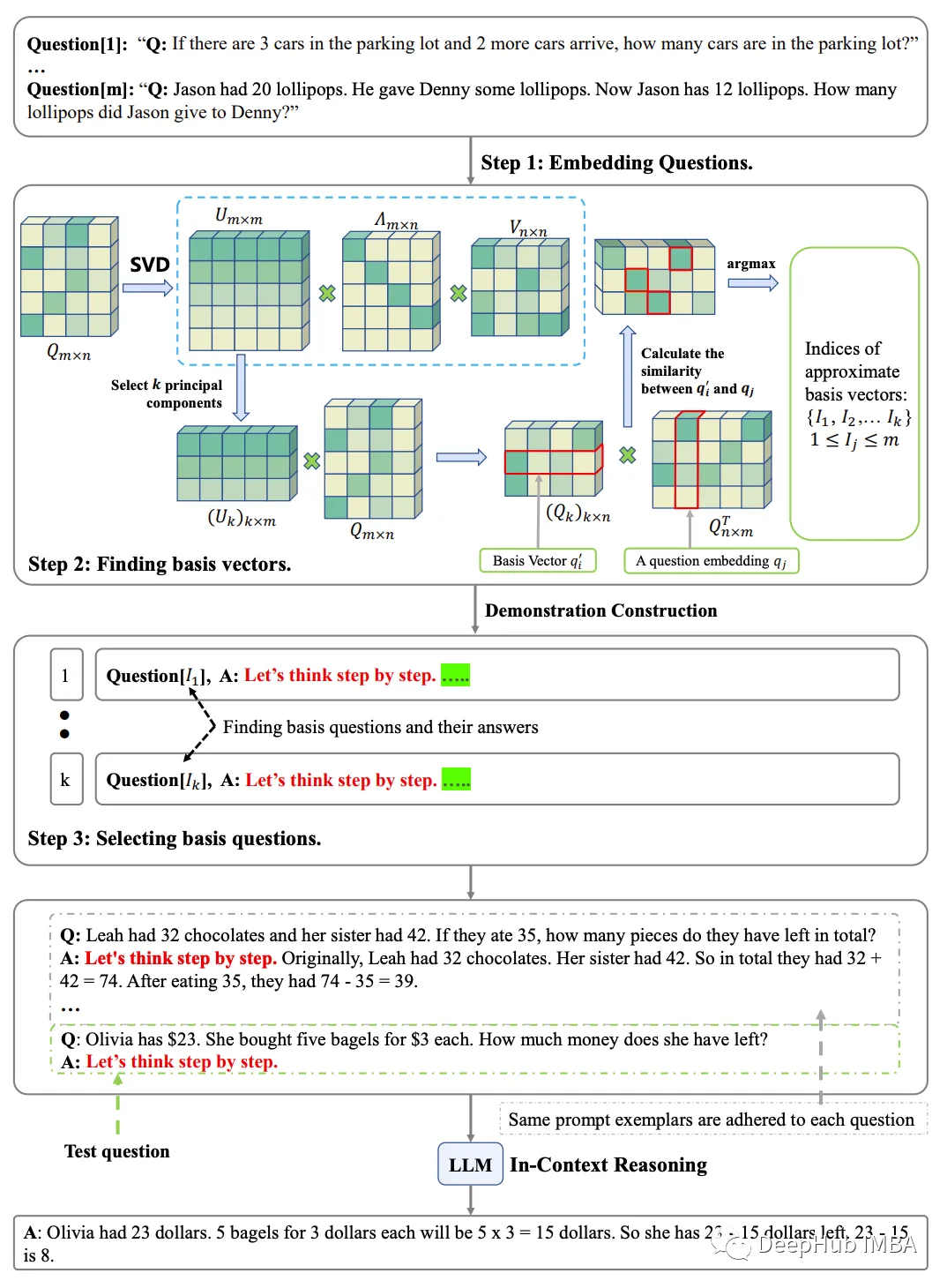
6月人工智能论文推荐
6月人工智能论文推荐
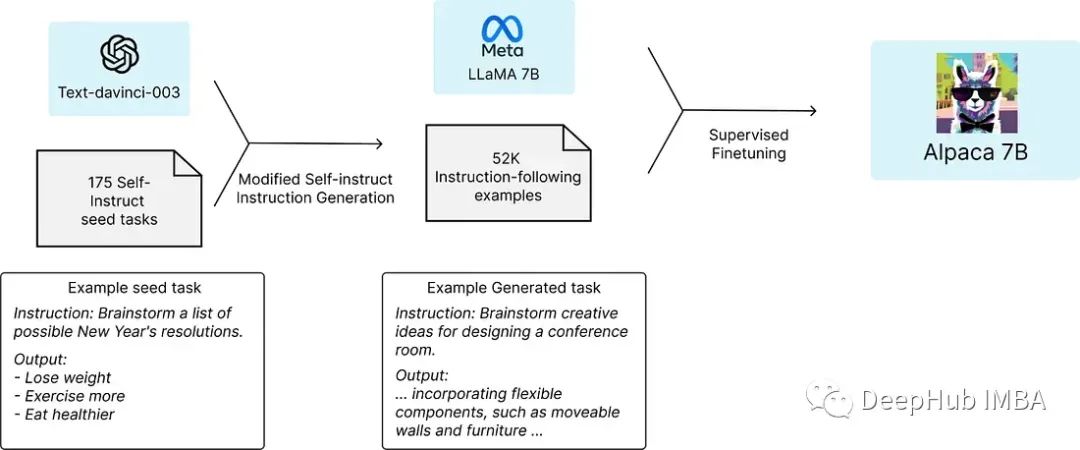
开源大型语言模型(llm)总结
大型语言模型(LLM)是人工智能领域中的一个重要研究方向,在ChatGPT之后,它经历了快速的发展。
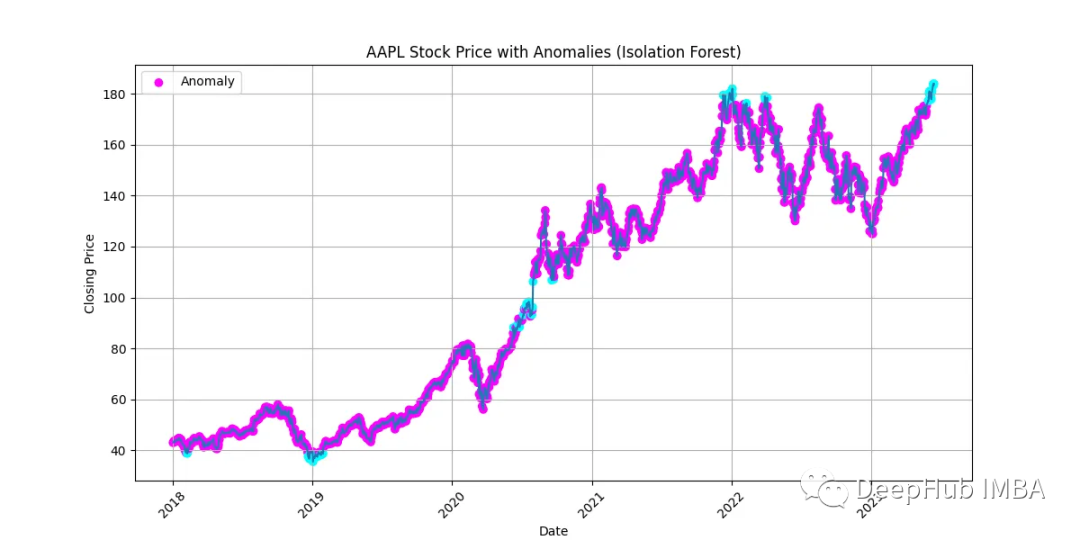
时间序列异常检测:统计和机器学习方法介绍
在本文中将探索各种方法来揭示时间序列数据中的异常模式和异常值。

XGBoost超参数调优指南
本文将详细解释XGBoost中十个最常用超参数的介绍,功能和值范围,及如何使用Optuna进行超参数调优。
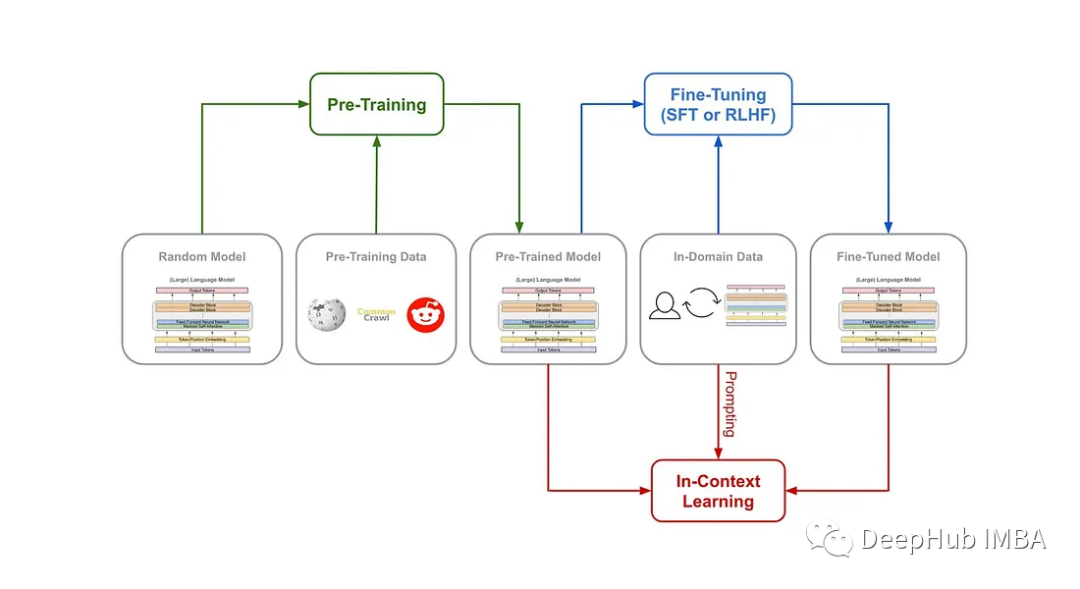
预训练、微调和上下文学习
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。
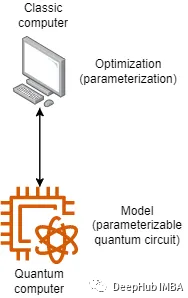
量子机器学习Variational Quantum Classifier (VQC)简介
变分量子分类器(Variational Quantum Classifier,简称VQC)是一种利用量子计算技术进行分类任务的机器学习算法。它属于量子机器学习算法家族,旨在利用量子计算机的计算能力,潜在地提升经典机器学习方法的性能。


时间序列预测的20个基本概念总结
时间序列是一组按时间顺序排列的数据点

使用NLPAUG 进行文本数据的扩充增强
数据增强可以通过添加对现有数据进行略微修改的副本或从现有数据中新创建的合成数据来增加数据量。这种数据扩充的方式在CV中十分常见,因为对于图像来说可以使用很多现成的技术,在保证图像信息的情况下进行图像的扩充。

谷歌发布一个免费的生成式人工智能课程
谷歌推出了一个生成式人工智能学习课程,课程涵盖了生成式人工智能入门、大型语言模型、图像生成等主题。
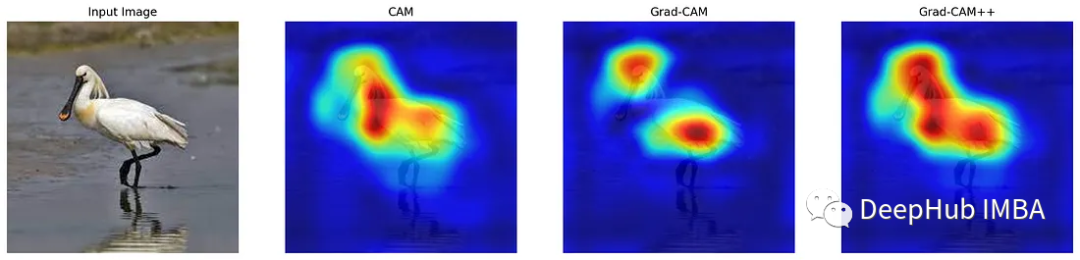
CAM, Grad-CAM, Grad-CAM++可视化CNN方式的代码实现和对比
理解CNN的方法主要有类激活图(Class Activation Maps, CAM)、梯度加权类激活图(Gradient Weighted Class Activation Mapping, Grad-CAM)和优化的 Grad-CAM( Grad-CAM++)。