
强化学习、多模态、语言模型即服务、计算机视觉、信息检索等。
Meta 的新型超级计算机——AI Research SUperCLuster 的发布是为了满足大型机器学习模型日益苛刻的计算需求。 再次证明,增长模型的趋势远未结束。
PyTorch 已经 5 岁了! 它已成为最流行的深度学习框架,不仅用于学术研究,还为当今行业树立了标准。
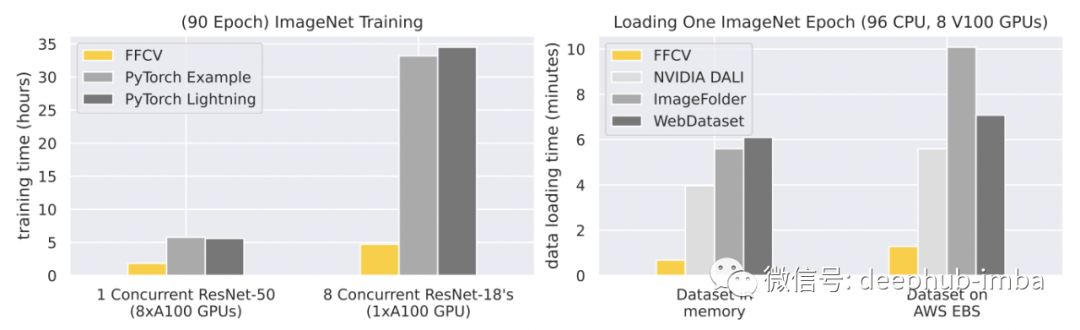
FFCV 库:一个计算机视觉加速数据加载系统,用于增加模型训练中的数据吞吐量。 只需更换数据加载器,然后……🚀
本篇文章选择了 10 篇论文,这些论文展示了各种 AI 子领域的关键发展:自动强化学习 (AutoRL)、多模态语言模型 (LM)、计算机视觉 (CV) 中的ConvNets vs Transformers 、无监督神经信息 检索 (IR) 等。
1、Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
By Jack Parker-Holder, Raghu Rajan, Xingyou Song et al.
机器学习的主要目标之一将多个数据处理工作流整合成自动化的工作并允许非专业人员使用 ,因此 AutoML 等主题很受欢迎。 AutoRL 是强化学习领域的类似物。
本文概述了该领域,提供了有用的分类法来统一 AutoRL 的各种方法。 它对 ML 从业者特别有用,因为 RL 词汇与 ML 词汇有很大不同,这使得跨领域的思想交叉变得更加困难。
讨论的主题包括针对不同目标的优化技术(例如超参数、任务设计、架构等):
- 随机与网格搜索驱动的方法
- 贝叶斯优化
- 进化(和/或基于人群)的方法
- 元梯度
- 黑盒优化
- 学习强化学习算法、环境设计

虽然开箱即用的强化学习的“梦想”似乎还很遥远,但它似乎并没有阻止研究人员进入它。
最近在强化学习和语言模型的交叉点上可能有趣的另一篇论文是Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents.
2、Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents.
By Wenlong Huang, Pieter Abbeel, Deepak Pathak and Igor Mordatch.
NLP 技术在 ML 中跨越到其他领域一直是过去几年反复出现的主题。
如果足够大并经过适当训练,大型的语言模型可以将高级任务分解为低级计划,而且无需进一步训练(即仅使用冻结模型)。
但是自由形式的语言模型生成可能是无法实现的,因为无法映射到现有的一组已知对象和操作。 这就是为什么作者建议引入从语言模型输出到有效动作的映射步骤。 此映射由句子相似度的变换器来进行操作,该变换器在嵌入空间中找到最接近的有效低级动作。

结果证明了冻结语言模型包含了从高级别指令中提取出低级别行动计划所需的信息。
3、CM3: A Causal Masked Multimodal Model of the Internet
By Armen Aghajanyan et al.
多模态一直是 AI 中一个快速发展的子领域,尤其是自从巨大的 Transformer 出现以来。尽管到目前为止,它们的性能对于现有基准测试而言可以说是平淡无奇,但在可预见的未来,关于该主题的研究数量肯定会继续增加。
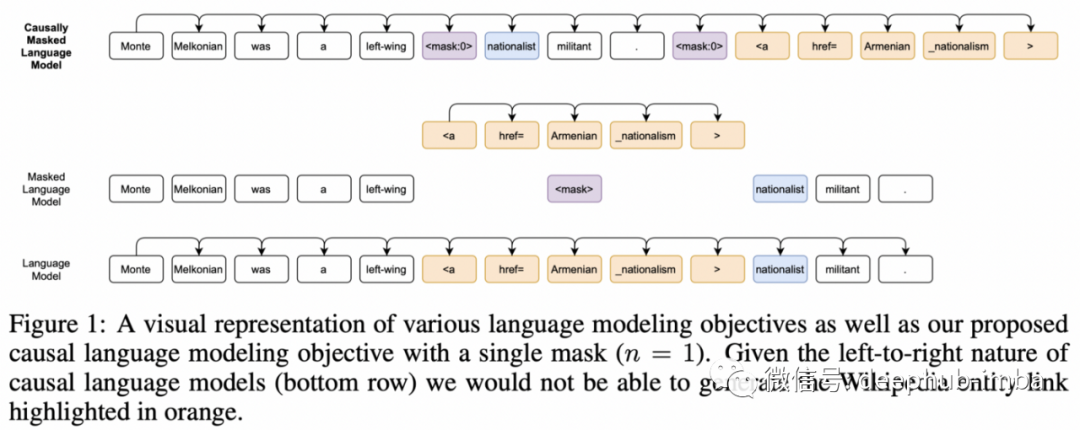
这项工作的作者巧妙地设计了一个预训练任务,该任务对包含文本和图像的 HTML 数据进行操作。但是如何将图像编码为可以输入模型的令牌?与 OpenAI 的 DALLE² 有点相似,他们使用 VQVAE-GAN¹ 学习图像块的量化表示,可以将其视为离散的符号字典,就像常规文本标记一样。
对于训练,他们使用了从左到右和双向语言建模相结合的方式,整个数据的规模很大,但对于今天的标准来说并没有大到离谱:1TB的训练语料库,最大的最大13B参数模型。
他们在zero-shot 设置中的单峰和多峰任务上对 CM3 进行了基准测试,显示出在图像字幕、图像生成、摘要、实体链接和其他几个 NLP 任务上的可靠(在某些情况下甚至是 SOTA)性能。
4、The Web Is Your Oyster — Knowledge-Intensive NLP against a Very Large Web Corpus
By Aleksandra Piktus et al.
GPT-3 于 2020 年 5 月问世时,一个普遍的批评是它对 Covid 一无所知,因为它的训练语料库是在大流行开始之前创建的。包括这些知识将需要使用新数据来训练模型以进行微调或从头开始,这是非常昂贵的。让语言模型访问知识库是最近的一项发展,这使他们能够成为更高效的学习者,并且在不重新训练神经网络的情况下能够更新知识的额外好处是更准确。
知识密集型 NLP 任务被定义为人类在不咨询知识库(例如书籍、网络)的情况下无法解决的任务。本文提出了一个新的基准,精确地衡量了 LM 在这方面的表现。它基于现有的 KILT 基准³,主要基于 Wikipedia 语料库来构建事实检查、实体链接、开放域 QA 和对话生成任务。
随着越来越多的检索增强语言模型被提出,拥有一个可靠的评估系统来比较它们变得越来越重要。此类模型的一些最新示例包括 WebGPT:具有人类反馈的浏览器辅助问答 (OpenAI)、通过从数万亿个令牌中检索来改进语言模型 (DeepMind)、 LaMDA:对话应用程序的语言模型 (Google)。

5、LaMDA: Language Models for Dialog Applications
By Romal Thoppilan et al.
尽管在文本生成方面取得了巨大进步,但你会发现的许多聊天机器人仍然很烦人,而且没那么有用。现代语言模型如何改进对话式人工智能?这是来自 Google 的最新提案。
这实际上是语言模型的另一个实例,它与知识库交互以回答用户的查询,基本上是检索增强的 LM。谷歌训练了一个庞大的 137B 模型,并使用人类判断来评估它,例如诸如敏感性和特异性等指标进行评估。不出所料,性能随着规模不断提高而不会饱和。
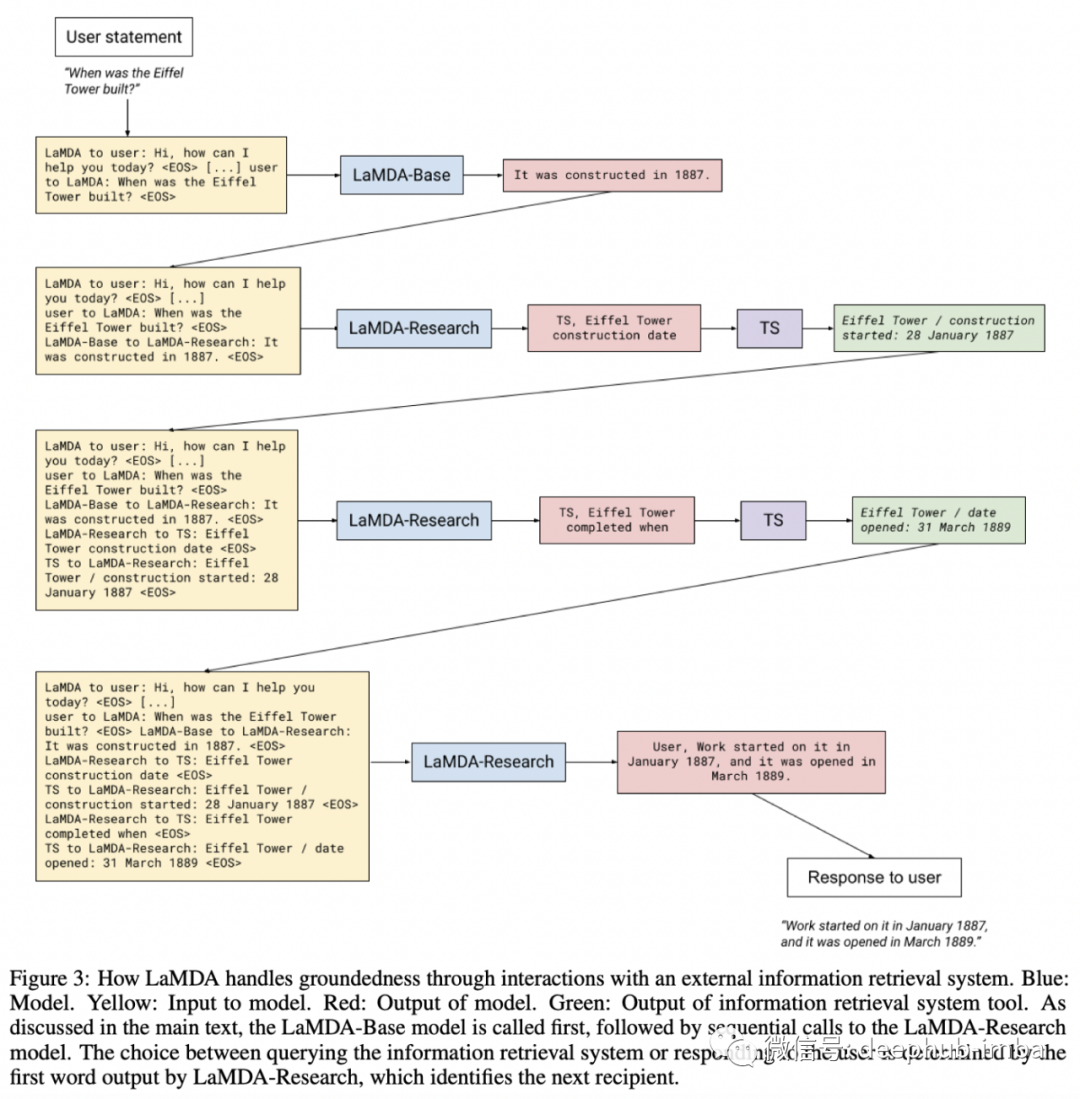
在概念层面上,该方法很简单:使用 LM 的两个变体,LaMDA-Base 是一个常规的 LM 对话训练,以及 LaMDA-Research它经过训练可以与外部知识系统交互,作者称之为工具集(TS)。该工具集不仅包括一个信息检索系统,还包括一个用于算术查询的计算器和一个翻译器。
LaMDA-Base 和 LaMDA-Research 通过传递它们的输入并将它们连接起来以保持全局上下文进行交互(见下图)。当然,该模型成功的关键之一是作者策划的高质量训练数据集,除了通常的大规模自监督预训练外,还包含超过 40k 带注释的对话交互。
6、Black-Box Tuning for Language-Model-as-a-Service
By Tianxiang Sun et al.
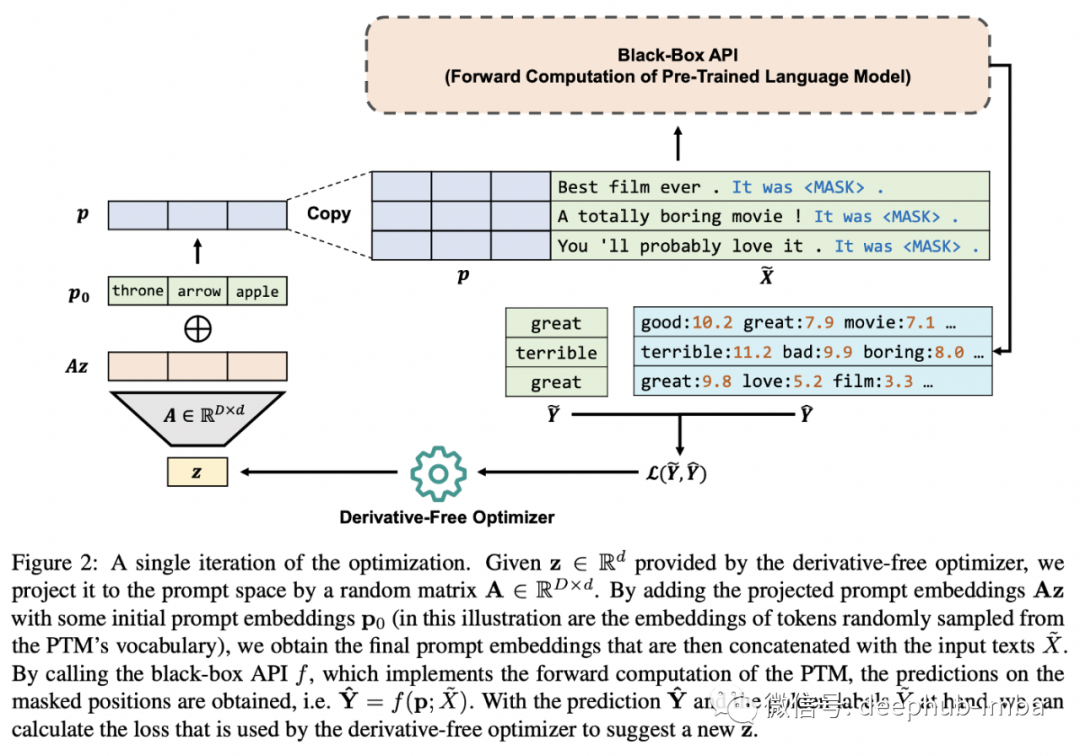
随着巨大的Transformers 成为许多研究领域的常态,它们的使用方式也出现了挑战。人们可以简单地下载一个几百 MB 大小的模型,然后在任何你想要的地方运行它。但是当大小接近 TB 时,它需要在多台机器上运行,而且下载是不可行的!此外对于像 OpenAI 这样的公司来说,如此大的模型已经成为极具价值的 IP,成为他们提供的服务的支柱和他们不愿放弃的明显竞争优势。因此作为服务的 ML 模型出现了,它仅将 ML 模型公开为黑盒 API,该 API 在给定一组输入的情况下返回预测。现在你能调整这样一个只能作为黑盒 API 访问的模型吗……?
黑盒 API 的用户可以使用无导数算法调整他们的系统(我们只能访问输入和输出,而不是梯度!)。特别是他们使用进化算法在提示和超参数空间中进行搜索,从而有效地学习了优于手动提示和上下文学习的提示,这意味着在提示中包含训练示例,就像 GPT-3 对小样本学习所做的那样。在某些情况下,他们的方法优于基于梯度的方法,例如快速微调!
7、A ConvNet for the 2020s
By Zhuang Liu et al.
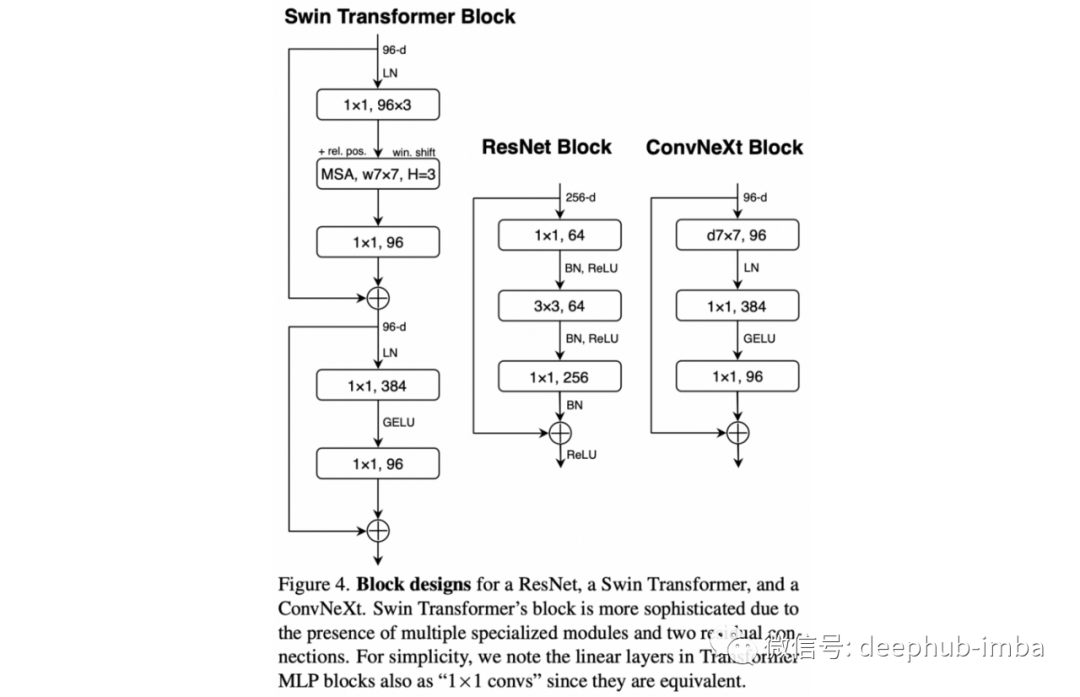
深度学习在 2010 年代初的强劲势头很大程度上归功于 AlexNet 在 2012 年 ImageNet 挑战赛中的巨大成功。从那时起,卷积——这种神经网络的主要组成部分——一手主导了计算机视觉的世界。然而随着 Transformer 的引入及其方便的可扩展性,将它们应用于 CV 的方法(如 Swin Transformer⁴)变得越来越流行;可以说卷积已经保持了这么长时间的王冠。
卷积仍然是王者。
本文通过进一步优化它们证明了 ConvNets 仍然比 Transformer 具有优势,从而产生了流行的 ResNets 的现代版本,与类似的基于 Transformer 的架构相比具有优势。这些变化包括放弃 BatchNorm 使用 LayerNorm,从 ReLU 切换到 GELU,或改变卷积核的大小等。差不多就是这样,他们在 ImageNet 上的结果略高于基于Transformer 的架构。
架构之战仍在继续,如果有一点很清楚,那就是人工智能领域肯定会从竞争中受益!
8、GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
By Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, et al.
自 2014 年引入 GAN 以来,图像生成一直是深度学习的一个非常引人注目的应用。最近使用 VQ-VAE(例如 DALL·E)和扩散模型的自回归生成等方法正在成为可行甚至更好的替代方案 .
扩散模型通过在像素网格上迭代地添加可微噪声来生成图像,最终成为真实的图像。 本文提出了一种基于扩散模型的文本提示生成和编辑图像的方法,该方法击败了著名的 OpenAI 的 DALL·E。 尽管如此这些模型仍然存在一些缺点,例如生成的每个图像所需的计算成本,这仍然阻止它们在许多应用中得到广泛使用。

9、Text and Code Embeddings by Contrastive Pre-Training
By Arvind Neelakantan, Tao Xu et al.
神经信息检索在深度学习中出现较晚,在某些方面仍不如 BM25 等 20 多年的算法!因为关键部分之一是对大量标记数据的依赖:今天所有成功的神经检索方法都严重依赖于来自 MS Marco 数据集的标签。这些模型可以在没有监督的情况下进行训练吗?
这是 OpenAI 提出的以完全自监督的方式学习文本的文本表示的提议。这些表示(即嵌入)旨在成为包括信息检索在内的各种任务中的可靠执行者。工作原理非常简单:使用相邻的文本片段作为正伪查询文档对和批量负样本。
这是无监督神经信息检索和表示学习的重要一步,但并不是像一些标题所暗示的那样是一个解决所有问题的嵌入式API。这是一个只能通过付费API访问的模型的例子,我们预计这样的例子会变得更加普遍。
10、DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale | Website
By Samyam Rajbhandari et al.
在过去的一年中,专家混合 (MoE) 已成为扩展大规模语言模型的首选策略。关键概念很简单:在推理期间仅通过模型内的子路径路由输入,这样在每个步骤中只使用一小部分模型参数。但目前此类系统的实现细节仍然很混乱,并且包括对密集模型(例如推理速度)的严重权衡。
DeepSpeed-MoE(即将在 GitHub 上开源)是 Microsoft 的 DeepSpeed 库的最新版本,旨在使分布式深度学习训练变得简单高效。
作者展示了MoE 的表现:更高效的训练——大约 5 倍——以及更好的参数效率。
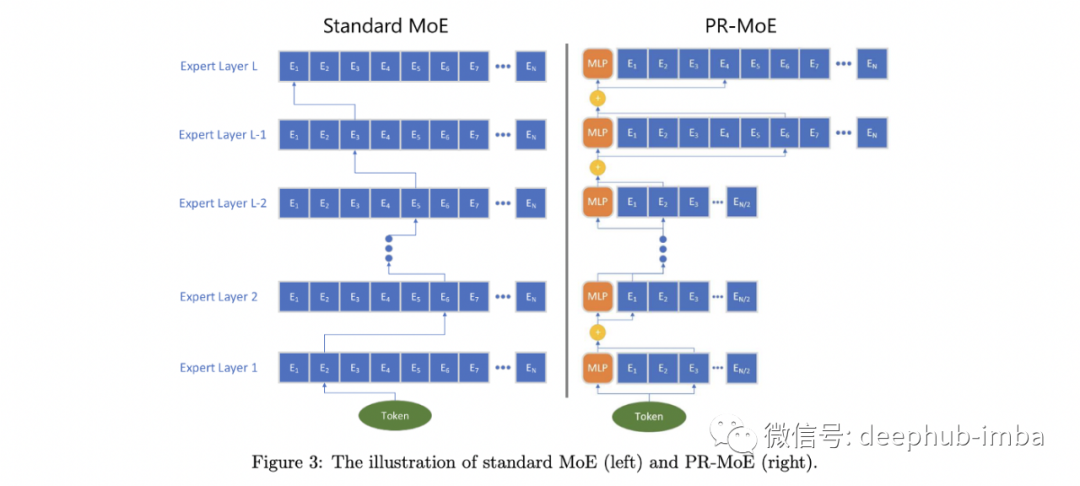
这篇论文还深入探讨了什么设计选择能让moe人学得更好。例如,浅层的专家多一些,还是深层的专家多一些?增加模型容量,是增加每个专家的容量还是增加专家的数量?虽然这些问题还没有绝对的答案,但本文通过经验探索了这些设计选择的权衡,将它们包装在通用PR-MoE(Pyramid Residual MoE)下。他们的PR-MoE的基本结构如下图所示,其中包括一个变化的“专家宽度”以及MLP的残差连接。
虽然 MoE 仍然不是主流,但如果解决了实现和设计的复杂性,它们有可能成为下一代大规模模型的标准。
作者:Sergi Castella i Sapé