
未标记的数据由监督学习网络标记,即所谓的伪标记。然后使用标记数据和伪标记数据训练网络。
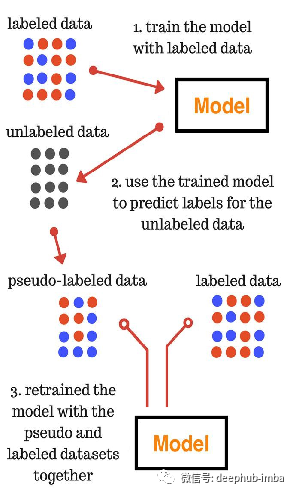
伪标签 (Pseudo-Labels)
伪标签是对未标记数据的进行分类后的目标类,在训练的时候可以像真正的标签一样使用它们,在选取伪标签的时使用的模型为每个未标记样本预测的最大预测概率的类:
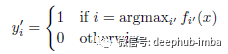
伪标签可以用于带有 Dropout 的微调阶段。预训练网络以监督方式同时使用标记和未标记数据进行训练:
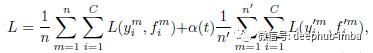
其中 n 是 SGD 标记数据中的样本数,n' 是未标记数据中的样本数;C 是分类总数;
fmi 是标注数据的输出,ymi 是对应的标签;
f'mi 为未标注数据,y'mi 为对应的伪标签;
α(t) 是在 t 时期平衡它们的系数。如果 α(t) 太高,即使是标记数据也会干扰训练。而如果 α(t) 太小,我们就不能利用未标记数据的好处。所以α(t)在训练期间缓慢增加,以帮助优化过程避免局部最小值不佳:
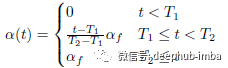
实验结果
t-SNE 可视化

使用MNIST 数据集。神经网络有 1 个隐藏层。ReLU 用于激活,Sigmoid Unit 用于输出。隐藏单元的数量为 5000。使用 600 个标记数据和 60000 个未标记数据进行伪标签标记后再次进行训练。
尽管在这两种情况下训练误差为零,但通过使用未标记数据和伪标签进行训练,测试数据的输出明显更好。
熵
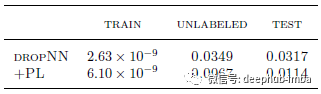
MNIST 上标记(训练)数据、未标记数据和测试数据的网络输出的条件熵。
DropNN:在没有未标记数据的情况下进行训练。(Drop 意味着 Dropout。)
+PL:使用未标记的数据进行训练。
虽然在这两种情况下标记数据的熵接近于零,但通过 Pseudo-Label 训练,未标记数据的熵会降低,此外,测试数据的熵也会随之降低。
错误率
具有 600、1000 和 3000 个标记训练样本的 MNIST 测试集上的分类错误。

标记训练集的大小减少到 100、600、1000 和 3000。对于验证集,分别选取 1000 个标记示例。
使用相同的网络和参数进行了 10 次随机分割实验。在 100 个标记数据的情况下,结果在很大程度上取决于数据拆分,因此进行了 30 个实验。
尽管简单,但所提出的方法优于小标记数据的传统方法。训练方案没有Manifold Tangent Classifier 复杂,并且不使用样本之间计算量大的相似度矩阵。
总结
这是一篇2013年的论文。虽然论文很老了,但是论文所给出的伪标签的方式在现在(2022年)还是一直在使用,所以对于这方面不了解的小伙伴推荐查看。
[2013 ICLRW] [Pseudo-Label (PL)] Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
作者:Sik-Ho Tsang