
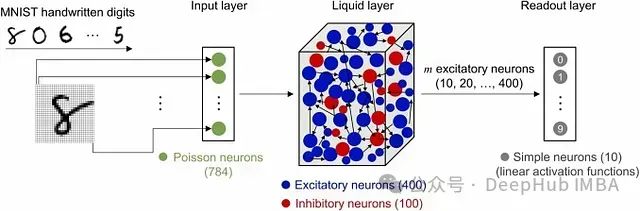
Liquid State Machine (LSM) 是一种 脉冲神经网络 (Spiking Neural Network, SNN) ,在计算神经科学和机器学习领域中得到广泛应用,特别适用于处理 时变或动态数据。它是受大脑自然信息处理过程启发而提出的一种 脉冲神经网络 。
设想你正处于一片平静的湖面,四周环绕着高山,你向水中投入一块石头。涟漪开始形成,向四周扩散。此时,在附近再投入一块石头。第二块石头产生的涟漪与第一块s石头产生的涟漪相互交叠,在水面上形成复杂多变的图案。这种图案并非随机产生;它包含了每块石头落水的位置、时间、大小,甚至每次撞击释放的能量等信息。
利用这种涟漪效应来理解和解决问题。在某种程度上,这就是 Liquid State Machines (LSMs) 的工作原理。
由于其处理时间信息的独特方法和特殊的网络结构,Liquid State Machine (LSM) 模型与传统神经网络存在显著差异。
LSM简介
标准神经网络,如前馈网络,本身并不处理时间信息。循环神经网络(Recurrent Neural Network, RNN),如长短期记忆网络(Long Short-Term Memory, LSTM),通过反馈回路捕获序列信息,但需要对每一步进行显式训练。相比之下,LSM使用随机连接的神经元储备池("液体")将输入数据转化为高维动态状态。储备池的设计目的是随时间"回响"输入信号,被动捕捉时间模式而无需直接训练。这种结构以稀疏、高效的方式捕获输入数据的时间依赖性。
传统模型如RNN、LSTM和GRU(Gated Recurrent Unit)依赖于通过时间的反向传播(Backpropagation Through Time, BPTT)算法进行训练,这可能 计算量很大 ,而且经常出现梯度消失和梯度爆炸等问题。在LSM中,只对读出层进行训练,通常使用线性回归模型(例如岭回归),而储备池保持固定不变。这种方法 降低了计算负荷 ,简化了训练过程,因为只需要优化输出层的参数。
尽管RNN和LSTM可以对 时间模式 进行建模,但除非经过明确调优和多次迭代训练,否则这些模型在处理高度混沌或非线性系统时表现欠佳。得益于储备池的随机连接和丰富的非线性内部动力学,LSM可以有效处理 高度复杂和混沌的数据 。这种结构特别有利于需要对时间输入的微小变化保持敏感的任务,例如语音识别或混沌时间序列预测。
RNN主要用于顺序预测任务,而LSM则可以同时执行分类和预测任务。
代码实现
我们将使用Python构建一个时间序列数据的预测模型。
安装必要的库
!pip install reservoirpy matplotlib numpy
导入库并加载数据集
import numpy as np
import matplotlib.pyplot as plt
from reservoirpy.nodes import Reservoir, Ridge
from reservoirpy.datasets import mackey_glass
# 加载Mackey-Glass数据集
data = mackey_glass(n_timesteps=1000, tau=17)
# 可视化时间序列数据
plt.plot(data)
plt.title("Mackey-Glass Timeseries Data")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.show()
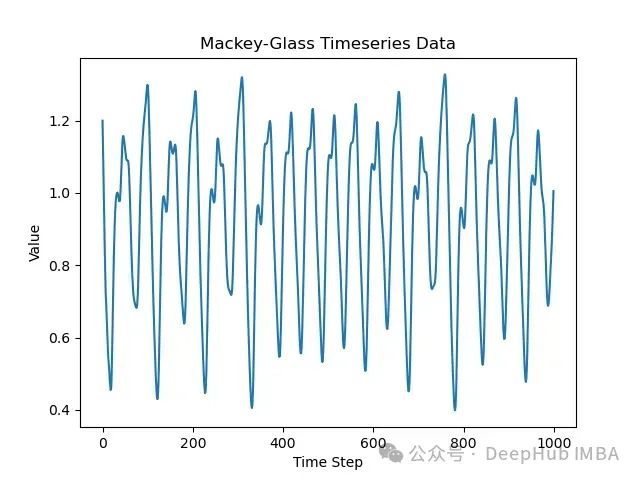
Mackey-Glass数据集 是一个在非线性系统建模和预测研究中经常使用的混沌时间序列。它模拟了一个生理反馈回路,根据延迟参数的不同可以表现出混沌特性。这使得它成为评估需要捕获复杂时间依赖性模型的理想数据集。
数据预处理
# 对数据进行归一化处理
data = (data - np.mean(data)) / np.std(data)
划分训练集和测试集
# 将数据集划分为训练集和测试集
split_ratio = 0.8
split_idx = int(split_ratio * len(data))
train_data, test_data = data[:split_idx], data[split_idx:]
定义储备池参数
# 构建并配置Liquid State Machine(储备池)
reservoir_size = 500 # 储备池中的神经元数量
LSM模型由一个储备层和一个读出层组成。储备池 在高维空间中捕获时间动力学信息,读出层 对这些动力学信息进行回归。
# 创建储备池和读出层
reservoir = Reservoir(units=reservoir_size, lr=0.1, input_scaling=0.5, sr=0.9) # 将'spectral_radius'参数简写为'sr'
readout = Ridge(ridge=1e-6)
通过将数据输入到储备池神经元,可以生成高维状态,捕获输入数据的时间依赖性。线性回归读出层(
Ridge
)将储备池状态映射到下一个时间步的值。
现在,创建完整的LSM模型。
# 连接各层,构建LSM模型
model = reservoir >> readout
使用训练数据的储备池状态训练模型,目标是预测下一个时间步的值。
# 调整数据形状以适应训练
X_train = train_data[:-1].reshape(-1, 1) # 输入数据
y_train = train_data[1:] # 目标数据(下一个时间步的值)
# 训练模型
model = model.fit(X_train, y_train, warmup=100)
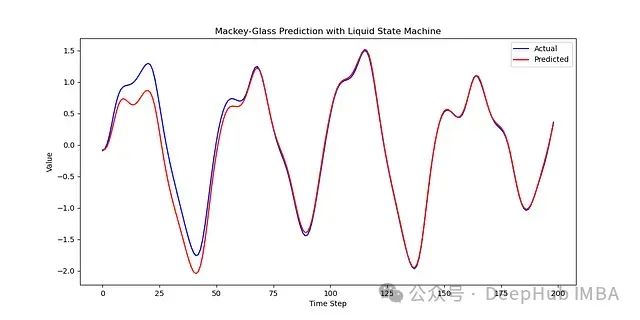
使用训练好的模型对测试集进行预测,并将预测结果与真实值进行对比。
# 生成预测结果
X_test = test_data[:-1].reshape(-1, 1)
y_test = test_data[1:]
predictions = model.run(X_test)
#绘制预测结果与真实测试数据的对比图
plt.figure(figsize=(12, 6))
plt.plot(y_test, label="Actual", color='b')
plt.plot(predictions, label="Predicted", color='r')
plt.title("Mackey-Glass Prediction with Liquid State Machine")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.legend()
plt.show()
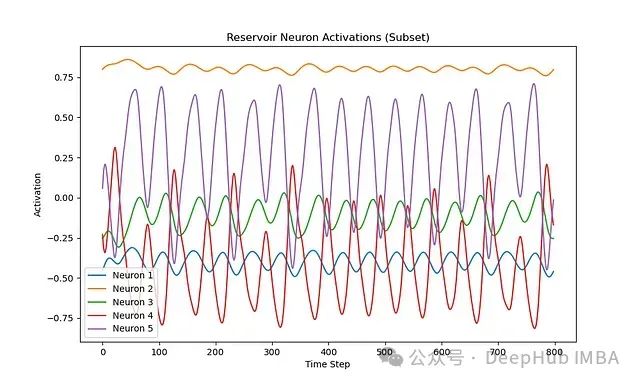
通过观察储备池神经元的激活情况,可以深入了解储备池如何将时间序列输入转化为高维状态。
# 通过观察部分神经元的激活情况来分析储备池动力学
plt.figure(figsize=(10, 6))
states = reservoir.run(X_train)
for i in range(5): # 绘制前5个神经元的激活情况
plt.plot(states[:, i], label=f"Neuron {i+1}")
plt.title("Reservoir Neuron Activations (Subset)")
plt.xlabel("Time Step")
plt.ylabel("Activation")
plt.legend()
plt.show()
LSM最初的设计灵感来自脉冲神经元,它对于需要实时处理和高时间精度的任务非常有效。在计算效率和训练复杂度要求较高的场景下,LSM也是一种强大的技术选择。
总结
这篇文章介绍了一种基于Liquid State Machine (LSM)模型的时间序列预测方法。LSM是一种脉冲神经网络,特别适用于处理时变或动态数据。与传统的神经网络模型相比,LSM通过随机连接的储备池捕获时间依赖性,并且只需训练读出层,大大降低了计算负荷。文章详细阐述了LSM的工作原理,并使用Python和ReservoirPy库实现了一个完整的时间序列预测案例。以Mackey-Glass数据集为例,展示了数据预处理、模型构建、训练和预测的完整流程。同时,通过可视化储备池神经元的激活情况,直观地展现了LSM将时间序列转化为高维状态的过程。文章表明,LSM模型在处理复杂时间序列和实时预测任务方面具有显著优势,为时间序列预测提供了一种高效、可扩展的新思路。
作者:Nivedita Bhadra