
本文是对发表于arXiv的论文 "TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS" 的深入解读与扩展分析。主要探讨了一种革新性的Transformer架构设计方案,该方案通过参数标记化实现了模型的高效扩展和计算优化。
论文动机
如今的人工智能离不开Transformer,因为它是大型语言模型背后的基础架构。然而它的影响力并不仅限于自然语言处理。Transformer在其他领域也发挥着重要作用,比如计算机视觉领域中的Vision Transformer(ViT)就扮演着重要角色。随着我们的进步,模型规模不断扩大,从头开始训练模型变得越来越昂贵且不可持续
论文的研究团队观察到,虽然Transformer架构在多个领域取得了巨大成功,但其可扩展性受到了严重限制,主要是因为在token-parameter交互计算方面采用了固定的线性投影方法。
Tokenformer创新设计
Tokenformer消除了在增加模型规模时需要从头开始重新训练模型的需求,大大降低了成本。
论文中提出的关键创新包括:
- 完全基于注意力的架构设计:- 不仅用于token之间的交互- 还用于token和模型参数之间的交互- 提供了更大的架构灵活性
- 参数标记化方法:- 将模型参数视为可学习的token- 使用交叉注意力机制管理交互- 支持动态参数扩展
Transformer vs Tokenformer — 架构对比
让我们从高层次比较传统的Transformer架构和Tokenformer:
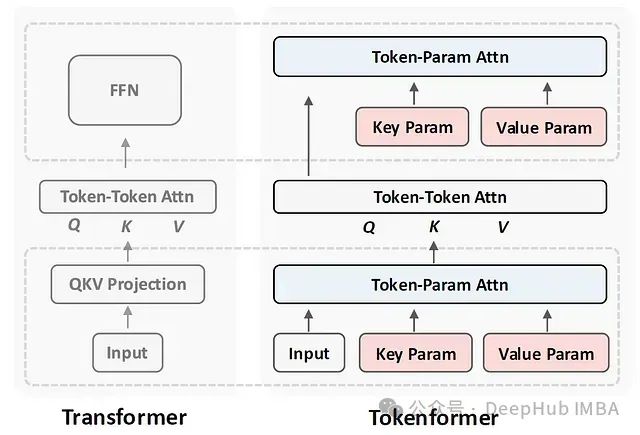
Transformer高层流程
在左侧,我们可以看到原始Transformer架构的简化视图。从底部的输入token序列开始:
输入首先通过线性投影块来计算注意力块的输入,即Q、K和V矩阵。这个阶段涉及模型参数和输入token之间的交互,使用线性投影进行计算。然后,自注意力组件允许输入token之间相互交互,通过注意力块进行计算。最后,前馈网络(FFN)产生下一层的输出,同样表示使用线性投影计算的token和参数之间的交互。
论文指出,传统Transformer架构中的这种线性投影设计限制了模型的灵活性和可扩展性。当需要增加模型规模时,必须改变这些线性投影层的维度,这就需要重新训练整个模型。
Tokenformer的架构创新
Token-参数交互是通过线性投影组件计算的,这些组件具有固定大小的参数,在增加模型规模时需要从头开始训练。Tokenformer的主要理念是创建一个完全基于注意力的模型,包括token-参数交互,以实现一个更灵活的架构,支持增量参数数量的增加。
Tokenformer高层流程
在上面架构图的右侧,我们可以看到Tokenformer架构的简化视图:
为了计算自注意力块的输入(Q、K和V矩阵),输入token被送入一个称为token-参数注意力的新组件,在这里除了输入token外,还传入了参数。输入token代表查询部分,参数代表token-参数注意力块的键和值部分。然后有和之前相同的自注意力组件。最后为了准备下一层的输出,用另一个token-参数注意力块替代了前馈网络,其中来自自注意力块的输出用作查询,再次包含了不同的参数用于键和值矩阵。
Tokenformer架构详解
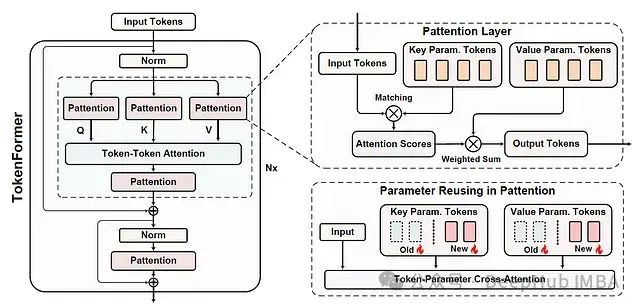
论文中的详细架构图展示了Tokenformer的完整设计。主要包括:
- 输入处理:
defprocess_input(X, K_P, V_P): # X: 输入tokens # K_P, V_P: 参数tokens attention_scores=compute_attention(X, K_P) returnweighted_sum(attention_scores, V_P) - 改进的注意力机制:
defimproved_attention(query, key, value): # 使用改进的softmax (theta函数) scores=theta(matmul(query, key.transpose())) returnmatmul(scores, value)
Pattention机制详解
论文对比了标准注意力机制和新提出的Pattention机制:
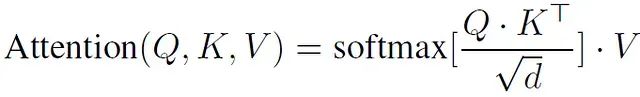
原始注意力机制的计算公式
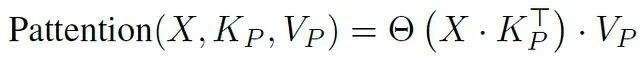
Pattention的计算公式
这种新的注意力机制设计具有以下优势:
- 更好的梯度稳定性
- 支持动态参数扩展
- 保持输出分布的连续性
FFN的革新
传统Transformer中的前馈网络被替换为:
- 两个连续的pattention块
- 通过残差连接与输入token合并
- 支持参数的动态扩展# 增量模型增长
在架构图的右下方,我们可以看到当想要通过添加新参数来增量增加模型规模时会发生什么。基本上是在每个pattention块的键和值矩阵中添加更多的参数token行,但保留已训练的参数token。然后在训练更大模型时所有token都会继续更新,从实验结果中可以看到,相比从头开始训练,规模增加的模型训练速度要快得多。
实验结果
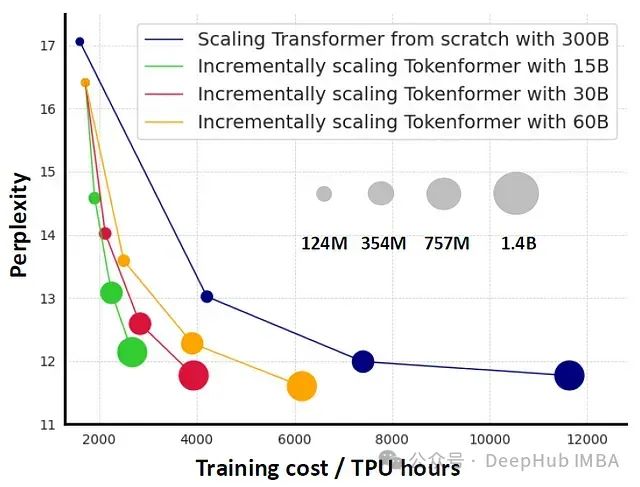
论文中呈现的实验结果显示了y轴上的Tokenformer模型性能和x轴上的训练成本,与从头训练的Transformer进行比较:
- 基线模型(蓝线):- 使用3000亿个token从头训练的Transformer模型- 不同圆圈大小代表不同的模型规模(从124M到1.4B参数)
- Tokenformer性能(其他颜色线):- 红线:从1.24亿参数扩展到14亿参数- 仅使用300亿个token进行增量训练- 最终性能与完整训练相当,但训练成本显著降低
- 效率提升:- 黄线表明使用600亿个token的增量训练- 达到了比传统Transformer更好的性能- 同时保持较低的训练成本
关键优势
论文的实验结果证明了Tokenformer在以下方面的优势:
- 计算效率:
# 传统Transformer的计算复杂度 flops_transformer=O(n_layer*d_model^2*T+d_model*T^2) # Tokenformer的计算复杂度 flops_tokenformer=O(n_layer*d_token*N*T+d_token*T^2) # 其中N为参数token数量,可以灵活调整 - 扩展性能:- 支持从124M到1.4B参数的顺滑扩展- 保持模型性能的同时显著降低训练成本- 实现了更高效的参数利用
- 实际应用价值:- 降低了大模型训练的资源门槛- 支持模型的持续演进和更新- 提供了更环保的AI模型训练方案
未来展望
论文最后提出了几个重要的研究方向:
- 将Tokenformer扩展到混合专家系统
- 探索参数高效的迁移学习方法
- 研究视觉-语言模型的统一架构
- 开发基于Tokenformer的设备-云协同系统
- 提升模型的可解释性
这些方向都显示了Tokenformer架构的巨大潜力,有望在未来的AI发展中发挥重要作用。
论文地址
https://arxiv.org/abs/2410.23168
随论文的还同时发布了完整的源代码,可以在下面链接查看