
本文介绍如何使用 PyTorch 和三元组边缘损失 (Triplet Margin Loss) 微调嵌入模型,并重点阐述实现细节和代码示例。三元组损失是一种对比损失函数,通过缩小锚点与正例间的距离,同时扩大锚点与负例间的距离来优化模型。
数据集准备与处理
一般的嵌入模型都会使用Sentence Transformer ,其中的
encode()
方法可以直接处理文本输入。但是为了进行微调,我们需要采用 Transformer 库,所以就要将文本转换为模型可接受的 token IDs 和 attention masks。Token IDs 代表模型词汇表中的词或字符,attention masks 用于防止模型关注填充 tokens。
本文使用
thenlper/gte-base
模型,需要对应的 tokenizer 对文本进行预处理。该模型基于
BertModel
架构:
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12xBertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
利用 Transformers 库的
AutoTokenizer
和
AutoModel
可以简化模型加载过程,无需手动处理底层架构和配置细节。
fromtransformersimportAutoTokenizer, AutoModel
fromtqdmimporttqdm
tokenizer=AutoTokenizer.from_pretrained("thenlper/gte-base")
# 获取文本并进行标记
train_texts= [df_train.loc[i]['content'] foriinrange(df_train.shape[0])]
dev_texts= [df_dev.loc[i]['content'] foriinrange(df_dev.shape[0])]
test_texts= [df_test.loc[i]['content'] foriinrange(df_test.shape[0])]
train_tokens= []
train_attention_masks= []
dev_tokens= []
dev_attention_masks= []
test_tokens= []
test_attention_masks= []
forsentintqdm(train_texts):
encoding=tokenizer(sent, truncation=True, padding='max_length', return_tensors='pt')
train_tokens.append(encoding['input_ids'].squeeze(0))
train_attention_masks.append(encoding['attention_mask'].squeeze(0))
forsentintqdm(dev_texts):
encoding=tokenizer(sent, truncation=True, padding='max_length', return_tensors='pt')
dev_tokens.append(encoding['input_ids'].squeeze(0))
dev_attention_masks.append(encoding['attention_mask'].squeeze(0))
forsentintqdm(test_texts):
encoding=tokenizer(sent, truncation=True, padding='max_length', return_tensors='pt')
test_tokens.append(encoding['input_ids'].squeeze(0))
test_attention_masks.append(encoding['attention_mask'].squeeze(0))
获取 token IDs 和 attention masks 后,需要将其存储并创建一个自定义的 PyTorch 数据集。
importrandom
fromcollectionsimportdefaultdict
importtorch
fromtorch.utils.dataimportDataset, DataLoader, Sampler, SequentialSampler
classCustomTripletDataset(Dataset):
def__init__(self, tokens, attention_masks, labels):
self.tokens=tokens
self.attention_masks=attention_masks
self.labels=torch.Tensor(labels)
self.label_dict=defaultdict(list)
foriinrange(len(tokens)):
self.label_dict[int(self.labels[i])].append(i)
self.unique_classes=list(self.label_dict.keys())
def__len__(self):
returnlen(self.tokens)
def__getitem__(self, index):
ids=self.tokens[index].to(device)
ams=self.attention_masks[index].to(device)
y=self.labels[index].to(device)
returnids, ams, y
由于采用三元组损失,需要从数据集中采样正例和负例。
label_dict
字典用于存储每个类别及其对应的数据索引,方便随机采样。DataLoader 用于加载数据集:
train_loader=DataLoader(train_dataset, batch_sampler=train_batch_sampler)
其中
train_batch_sampler
是自定义的批次采样器:
classCustomBatchSampler(SequentialSampler):
def__init__(self, dataset, batch_size):
self.dataset=dataset
self.batch_size=batch_size
self.unique_classes=sorted(dataset.unique_classes)
self.label_dict=dataset.label_dict
self.num_batches=len(self.dataset) //self.batch_size
self.class_size=self.batch_size//4
def__iter__(self):
total_samples_used=0
weights=np.repeat(1, len(self.unique_classes))
whiletotal_samples_used<len(self.dataset):
batch= []
classes= []
for_inrange(4):
next_selected_class=self._select_class(weights)
whilenext_selected_classinclasses:
next_selected_class=self._select_class(weights)
weights[next_selected_class] +=1
classes.append(next_selected_class)
new_choices=self.label_dict[next_selected_class]
remaining_samples=list(np.random.choice(new_choices, min(self.class_size, len(new_choices)), replace=False))
batch.extend(remaining_samples)
total_samples_used+=len(batch)
yieldbatch
def_select_class(self, weights):
dist=1/weights
dist=dist/np.sum(dist)
selected=int(np.random.choice(self.unique_classes, p=dist))
returnselected
def__len__(self):
returnself.num_batches
自定义批次采样器控制训练批次的构成,本文的实现确保每个批次包含 4 个类别,每个类别包含 8 个数据点。验证采样器则确保验证集批次在不同 epoch 间保持一致。
模型构建
嵌入模型通常基于 Transformer 架构,输出每个 token 的嵌入。为了获得句子嵌入,需要对 token 嵌入进行汇总。常用的方法包括 CLS 池化和平均池化。本文使用的
gte-base
模型采用平均池化,需要从模型输出中提取 token 嵌入并计算平均值。
importtorch.nn.functionalasF
importtorch.nnasnn
classEmbeddingModel(nn.Module):
def__init__(self, base_model):
super().__init__()
self.base_model=base_model
defaverage_pool(self, last_hidden_states, attention_mask):
# 平均 token 嵌入
last_hidden=last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
returnlast_hidden.sum(dim=1) /attention_mask.sum(dim=1)[..., None]
defforward(self, input_ids, attention_mask):
outputs=self.base_model(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_state=outputs.last_hidden_state
pooled_output=self.average_pool(last_hidden_state, attention_mask)
normalized_output=F.normalize(pooled_output, p=2, dim=1)
returnnormalized_output
base_model=AutoModel.from_pretrained("thenlper/gte-base")
model=EmbeddingModel(base_model)
EmbeddingModel
类封装了 Hugging Face 模型,并实现了平均池化和嵌入归一化。
模型训练
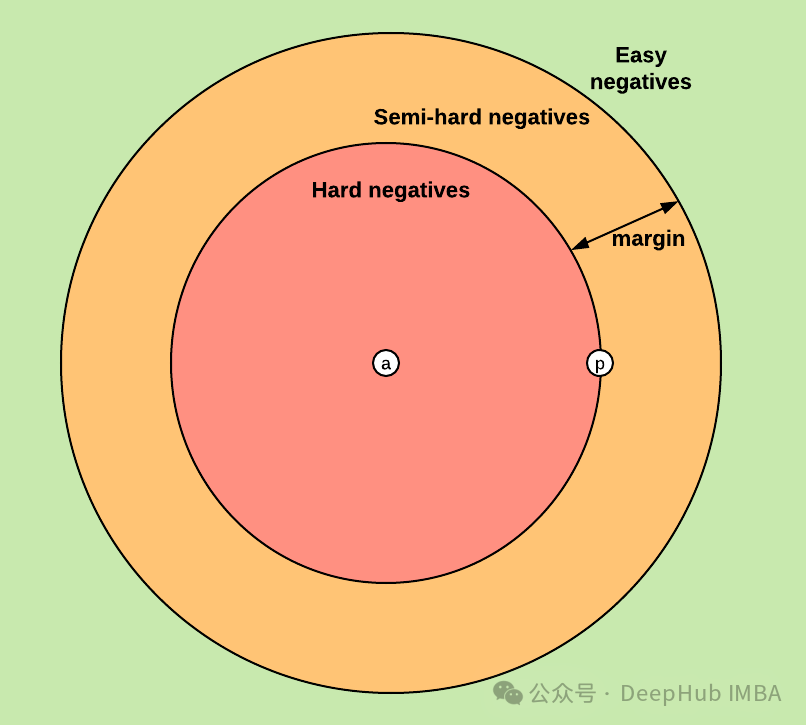
训练循环中需要动态计算每个锚点的最难正例和最难负例。
importnumpyasnp
deftrain(model, train_loader, criterion, optimizer, scheduler):
model.train()
epoch_train_losses= []
foridx, (ids, attention_masks, labels) inenumerate(train_loader):
optimizer.zero_grad()
embeddings=model(ids, attention_masks)
distance_matrix=torch.cdist(embeddings, embeddings, p=2) # 创建方形距离矩阵
anchors= []
positives= []
negatives= []
foriinrange(len(labels)):
anchor_label=labels[i].item()
anchor_distance=distance_matrix[i] # 锚点与所有其他点之间的距离
# 最难的正例(同一类别中最远的)
hardest_positive_idx= (labels==anchor_label).nonzero(as_tuple=True)[0] # 所有同类索引
hardest_positive_idx=hardest_positive_idx[hardest_positive_idx!=i] # 排除自己的标签
hardest_positive=hardest_positive_idx[anchor_distance[hardest_positive_idx].argmax()] # 最远同类的标签
# 最难的负例(不同类别中最近的)
hardest_negative_idx= (labels!=anchor_label).nonzero(as_tuple=True)[0] # 所有不同类索引
hardest_negative=hardest_negative_idx[anchor_distance[hardest_negative_idx].argmin()] # 最近不同类的标签
# 加载选择的
anchors.append(embeddings[i])
positives.append(embeddings[hardest_positive])
negatives.append(embeddings[hardest_negative])
# 将列表转换为张量
anchors=torch.stack(anchors)
positives=torch.stack(positives)
negatives=torch.stack(negatives)
# 计算损失
loss=criterion(anchors, positives, negatives)
epoch_train_losses.append(loss.item())
# 反向传播和优化
loss.backward()
optimizer.step()
# 更新学习率
scheduler.step()
returnnp.mean(epoch_train_losses)
训练过程中使用
torch.cdist()
计算嵌入间的距离矩阵,并根据距离选择最难正例和最难负例。PyTorch 的
TripletMarginLoss
用于计算损失。
结论与讨论
实践表明,Batch Hard Triplet Loss 在某些情况下并非最优选择。例如,当正例样本内部差异较大时,强制其嵌入相似可能适得其反。
本文的重点在于 PyTorch 中自定义批次采样和动态距离计算的实现。
对于某些任务,直接在分类任务上微调嵌入模型可能比使用三元组损失更有效。