
在贝叶斯统计中,选择合适的先验分布是一个关键步骤。本文将详细介绍三种主要的先验分布选择方法:
- 经验贝叶斯方法
- 信息先验
- 无信息/弱信息先验
经验贝叶斯方法
经验贝叶斯方法是一种最大似然估计(MLE)方法,通过最大化先验分布下数据的边际似然来估计先验分布的参数。设X表示数据,θ表示参数,则经验贝叶斯估计可表示为:
θ = argmax P(X|θ)
信息先验
信息先验是一种基于先前知识或以前研究结果,纳入了关于估计参数信息或信念的先验分布。信息先验有以下几个关键特点:
- 在样本量小或数据有噪声的情况下,信息先验可以导致更有效和准确的推断。
- 通过对先验信息赋予更大的权重,信息先验可以帮助正则化估计并避免过拟合。
- 信息先验有助于将特定领域的知识或假设纳入模型,例如对参数值的约束或参数之间的关系。
以下是一些常见的信息先验及其特点:
1. Beta先验
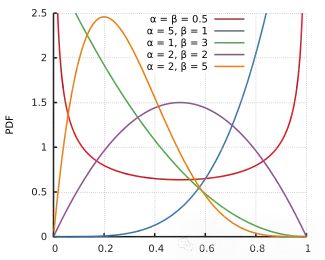
Beta先验的概率密度函数(PDF)由下式给出:
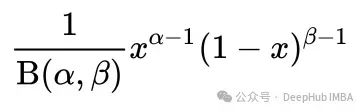
- Beta分布通常用作二项式或伯努利模型中概率参数的先验。
- 可以选择参数α和β来反映关于概率的先验知识或信念。例如,我们认为概率接近0.5,可以选择α=β=1的Beta先验,对应于[0,1]上的均匀分布。如果我们认为概率更可能接近0或1,可以选择较大α和β值的Beta先验,给极端值赋予更大的权重。
- 当我们对概率有一些先验知识或信念,或者想要对概率的可能值施加约束时,首选Beta先验。
2. 高斯先验
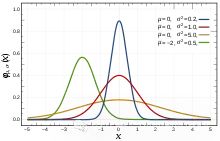
- 高斯分布或正态分布是连续参数先验的常见选择。
- 先验的均值和方差可以选择反映关于参数的先验知识或信念。例如,如果我们认为参数接近某个值,可以选择均值等于该值且方差较小的高斯先验。
- 当我们对参数的分布有一些先验知识或信念,或者想要正则化估计并避免过拟合时,首选高斯先验。
3. 狄利克雷先验
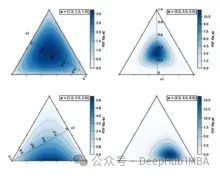
- 狄利克雷分布通常用作多项式或分类模型中概率参数的先验。
- 可以选择参数αi来反映关于每个类别相对频率的先验知识或信念。例如,如果我们认为某些类别比其他类别更可能,可以为这些类别选择较大αi值的狄利克雷先验。
- 当我们对类别的相对频率有一些先验知识或信念,或者想要对概率的可能组合施加约束时,首选狄利克雷先验。
4. 指数先验
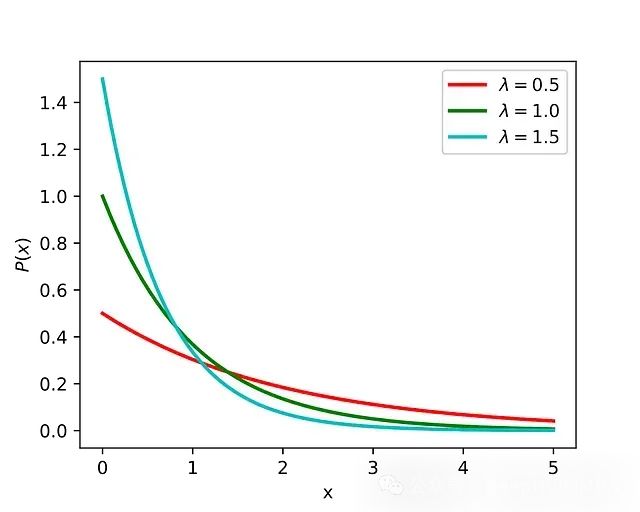
- 指数分布通常用作表示速率或时间参数的先验。
- 可以选择参数λ来反映关于速率或时间尺度的先验知识或信念。例如,如果我们认为速率较低,可以选择较大λ值的指数先验。
- 当我们对速率或时间尺度有一些先验知识或信念,或者想要正则化估计并避免过拟合时,首选指数先验。
5. Gamma先验
- Gamma分布是指数分布的推广,可以用作表示速率或时间参数的先验。
- 可以选择参数α和β来反映关于速率或时间尺度的先验知识或信念。
- 当我们对速率或时间尺度的分布有一些先验知识或信念,或者想要正则化估计并避免过拟合时,首选Gamma先验。
无信息/弱信息先验
当我们对数据没有先验知识时,可以在贝叶斯统计中为方程的系数选择无信息或弱信息先验分布。无信息先验不传达关于参数值的任何强先验信念或假设,而弱信息先验传达关于参数值的一些弱先验信念或假设。
以下是一些可用于贝叶斯线性回归模型中系数的无信息先验:
无信息先验
1. 平坦/均匀先验
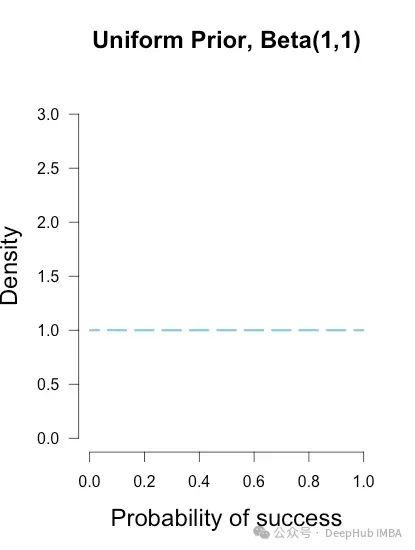
平坦/均匀先验为参数的所有可能值分配相等的概率,例如在广泛的值范围内的均匀分布。其概率密度函数为:
U(a, b), 其中a和b是分布的下限和上限。
2. 具有大方差的正态先验
具有大方差的正态先验假设参数在0附近正态分布,方差很大,表明我们对参数的先验知识很少。例如,均值为0,方差为100的正态先验,表示为:
N(0, σ²), 其中σ²是一个大值。
3. 柯西先验
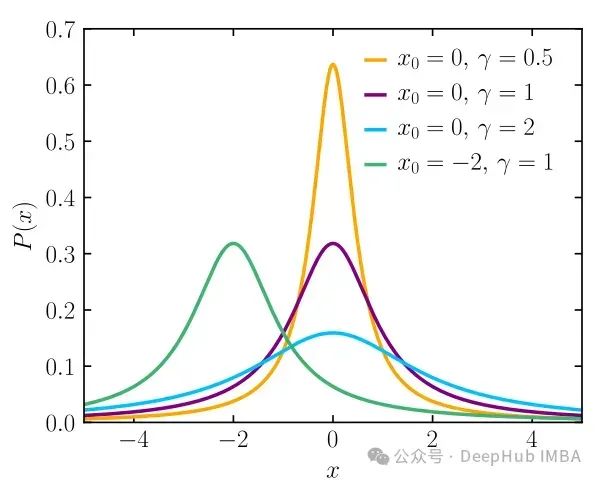
柯西先验是一种重尾分布,为参数的所有可能值分配相等的概率,但与正态先验相比,它在极端值上放置更多的概率质量。当数据稀疏或包含异常值时,柯西先验可能很有用。其概率密度函数为:
Cauchy(0, τ), 其中位置参数为0,比例参数为τ。
4. Jeffrey先验
Jeffrey先验是一种无信息先验,与Fisher信息的平方根成正比,Fisher信息是数据中关于参数信息量的度量。该先验在重新参数化下是不变的,并具有一些理想的数学性质。由于Fisher信息完全由数据确定,不包含任何主观或先验关于数据的信念,因此Jeffrey先验是无信息的。其概率密度函数为:
p(θ) ∝ √I(θ), 其中I(θ)是Fisher信息。
弱信息先验
1. 小方差的正态先验
小方差的正态先验假设参数在0附近正态分布,方差很小,表明我们对参数有一些弱先验知识。例如,均值为0,方差为1的正态先验,表示为:
N(0, σ²), 其中σ²是一个小值。
2. Student's t先验

在样本量小且总体标准差未知的情况下,可以使用Student's t先验。它与正态先验类似,但具有更重的尾部,允许更极端的值。当数据有噪声或有异常值时,Student's t先验可能很有用。其概率密度函数为:
t(0, σ, ν), 其中位置参数为0,比例参数为σ,自由度为ν。
3. 拉普拉斯先验
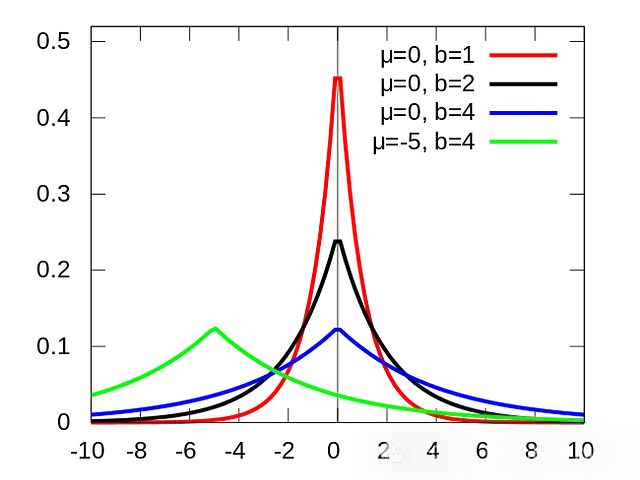
拉普拉斯先验的概率密度函数与exp(-λ|θ|)成正比,其中λ是控制先验强度的超参数。拉普拉斯先验通过为接近0的θ值分配更多的概率质量来鼓励稀疏解。其概率密度函数为:
Laplace(0, λ), 其中位置参数为0,比例参数为λ。
值得注意的是,先验的选择取决于具体问题以及我们对参数拥有的先验知识量。在实践中,通常使用无信息先验和弱信息先验的组合,并评估结果对先验选择的敏感性。
总结
本文详细介绍了贝叶斯统计中三种常见的先验分布选择方法:经验贝叶斯方法、信息先验和无信息/弱信息先验。
经验贝叶斯方法通过最大化先验分布下数据的边际似然来估计先验分布的参数。信息先验根据先前知识或研究结果,纳入了关于估计参数的信息或信念。常见的信息先验包括Beta先验、高斯先验、狄利克雷先验、指数先验和Gamma先验。在样本量小、数据有噪声或需要纳入领域知识时,信息先验特别有用。
无信息先验和弱信息先验适用于缺乏先验知识的情况。无信息先验不传达关于参数值的任何强先验信念或假设,常见的无信息先验包括平坦/均匀先验、具有大方差的正态先验、柯西先验和Jeffrey先验。弱信息先验传达关于参数值的一些弱先验信念或假设,如小方差的正态先验、Student's t先验和拉普拉斯先验。
在实践中,先验的选择取决于具体问题和已有的先验知识量。通常使用无信息先验和弱信息先验的组合,并评估结果对先验选择的敏感性。合理的先验分布选择可以提高贝叶斯推断的效率和准确性,帮助我们更好地利用先验知识和数据,从而得到可靠的估计和预测结果。
作者:Ganesh Bajaj