
贝叶斯营销组合建模(Bayesian Marketing Mix Modeling,MMM)作为一种先进的营销效果评估方法,其核心在于通过贝叶斯框架对营销投资的影响进行量化分析。在实践中为确保模型的可靠性和有效性,需要系统地进行模型诊断、分析和比较。本文将重点探讨这些关键环节,包括:
- 通过后验预测检验评估模型拟合度
- 采用敏感性分析评估先验假设的影响
- 利用收敛诊断确保参数估计的稳定性
- 解释模型参数与后验分析
- 评估预测准确性与模型校准
- 使用WAIC和LOO等指标进行模型选择
- 建立系统的贝叶斯模型比较框架
- 明确模型的核心假设与局限性
通过这些方面的深入分析,我们可以构建更加可靠和实用的贝叶斯MMM模型,为营销决策提供有力支持。
1. 后验预测检验:模型拟合评估
后验预测检验(Posterior Predictive Checks,PPC)是评估贝叶斯模型拟合质量的核心工具。它通过比较模型生成的预测数据与实际观测数据,为模型的有效性提供直接的验证依据。
后验预测检验的原理
后验预测检验的基本思路是利用模型的后验分布生成新的数据点,并将这些生成数据与实际观测数据进行对比。如果模型能够准确捕捉数据的本质特征,那么生成的数据应当与观测数据具有相似的统计特性。
后验预测检验的实施步骤
- 生成预测数据:利用已拟合贝叶斯MMM模型的后验分布,基于学习到的参数生成模拟数据。
- 数据比对:通过散点图、密度图或直方图等可视化方法,对比模型预测与实际观测数据的分布特征。
- 结果分析:评估预测数据与观测数据的一致性,显著的偏差表明模型可能未能充分捕捉数据的关键特征。
以下是使用PyMC实现后验预测检验的示例代码:
importpymcaspm
importnumpyasnp
importmatplotlib.pyplotasplt
importarvizasaz
# 生成示例数据
np.random.seed(42)
n_samples=100
# 定义三个营销渠道的支出数据
TV=np.random.uniform(0, 10, n_samples) # 电视广告支出
radio=np.random.uniform(0, 5, n_samples) # 广播广告支出
digital=np.random.uniform(0, 7, n_samples) # 数字媒体支出
# 设定真实参数
true_intercept=2.5
true_beta_TV=1.5
true_beta_radio=0.8
true_beta_digital=1.2
true_sigma=0.75
# 生成销售数据(线性组合加噪声)
sales= (true_intercept
+true_beta_TV*TV
+true_beta_radio*radio
+true_beta_digital*digital
+np.random.normal(0, true_sigma, n_samples))
# 可视化销售与电视广告支出的关系
plt.scatter(TV, sales, label="Observed sales vs TV spending")
plt.xlabel("TV Spend")
plt.ylabel("Sales")
plt.legend()
plt.show()
# 构建贝叶斯线性回归模型
withpm.Model() asmodel:
# 定义参数先验分布
intercept=pm.Normal("intercept", mu=0, sigma=10)
beta_TV=pm.Normal("beta_TV", mu=0, sigma=10)
beta_radio=pm.Normal("beta_radio", mu=0, sigma=10)
beta_digital=pm.Normal("beta_digital", mu=0, sigma=10)
sigma=pm.HalfNormal("sigma", sigma=1)
# 构建线性预测模型
mu=intercept+beta_TV*TV+beta_radio*radio+beta_digital*digital
# 定义似然函数
sales_obs=pm.Normal("sales_obs", mu=mu, sigma=sigma, observed=sales)
# 执行后验采样
trace=pm.sample(2000, tune=1000, return_inferencedata=True, target_accept=0.95)
# 执行后验预测检验
withmodel:
ppc=pm.sample_posterior_predictive(trace, var_names=["sales_obs"])
az.plot_ppc(ppc,figsize=(10,6))
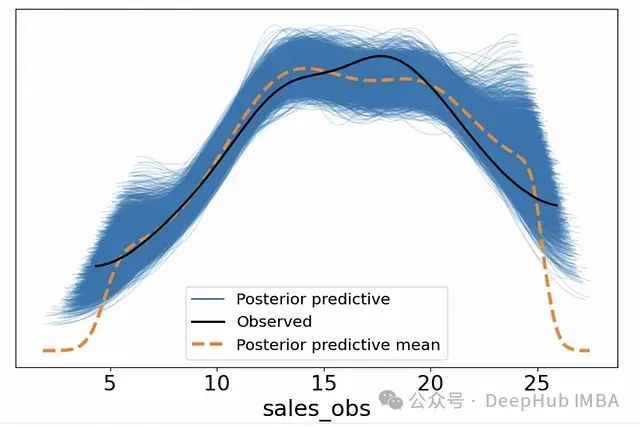
通过这种系统的后验预测检验,我们可以评估模型是否成功捕捉了数据的关键特征,从而为模型的可靠性提供重要的诊断依据。
2. 先验敏感性分析
先验敏感性分析是贝叶斯建模中的关键诊断步骤,用于评估先验分布选择对模型结果的影响程度。通过系统的敏感性分析,可以验证模型推断的稳健性,并深入理解先验假设对最终结论的影响。
2.1 比较分析法
比较分析法通过在不同先验设置下运行模型,观察参数后验分布的变化情况。这种方法能够直观地展示先验选择对模型结果的影响程度。
下面是一个使用PyMC实现比较分析的示例:
importpymcaspm
importnumpyasnp
importarvizasaz
importmatplotlib.pyplotasplt
# 生成模拟数据
np.random.seed(42)
n=100
x1=np.random.normal(10, 2, n) # 第一个营销渠道支出
x2=np.random.normal(20, 5, n) # 第二个营销渠道支出
sales=5+0.5*x1+0.3*x2+np.random.normal(0, 1, n) # 销售响应
# 构建弱信息先验模型
withpm.Model() asmodel_weak:
beta1=pm.Normal('beta1', mu=0, sigma=5) # 弱信息先验
beta2=pm.Normal('beta2', mu=0, sigma=5)
intercept=pm.Normal('intercept', mu=0, sigma=5)
sigma=pm.HalfNormal('sigma', sigma=2)
# 定义线性响应函数
mu=intercept+beta1*x1+beta2*x2
sales_obs=pm.Normal('sales_obs', mu=mu, sigma=sigma, observed=sales)
# 执行后验采样
trace_weak=pm.sample(1000, return_inferencedata=True, cores=1)
# 构建强信息先验模型
withpm.Model() asmodel_strong:
beta1=pm.Normal('beta1', mu=0.5, sigma=1) # 强信息先验
beta2=pm.Normal('beta2', mu=0.3, sigma=1)
intercept=pm.Normal('intercept', mu=5, sigma=1)
sigma=pm.HalfNormal('sigma', sigma=1)
# 定义线性响应函数
mu=intercept+beta1*x1+beta2*x2
sales_obs=pm.Normal('sales_obs', mu=mu, sigma=sigma, observed=sales)
# 执行后验采样
trace_strong=pm.sample(1000, return_inferencedata=True, cores=1)
2.2 图形化分析
通过可视化不同先验设置下的后验分布,可以直观地评估先验选择的影响。使用ArviZ库可以有效地实现这种可视化分析:
# 绘制后验分布比较图
az.plot_posterior(trace_weak, var_names=["beta1", "beta2"], hdi_prob=0.95)
plt.suptitle("后验分布 - 弱信息先验", y=1.05)
az.plot_posterior(trace_strong, var_names=["beta1", "beta2"], hdi_prob=0.95)
plt.suptitle("后验分布 - 强信息先验", y=1.05)
plt.show()
这些可视化结果能够揭示后验分布在不同先验设置下的变化。显著的差异表明模型对先验选择较为敏感,可能需要进行更深入的敏感性分析。
2.3 定量评估:KL散度分析
Kullback-Leibler (KL) 散度提供了一种定量方法来评估不同先验设置下后验分布的差异程度。较大的KL散度值表明先验选择对模型结果有显著影响。
fromscipy.statsimportentropy
# 提取后验样本
beta1_weak=trace_weak.posterior['beta1'].values.flatten()
beta1_strong=trace_strong.posterior['beta1'].values.flatten()
# 计算经验分布
hist_weak, bin_edges=np.histogram(beta1_weak, bins=50, density=True)
hist_strong, _=np.histogram(beta1_strong, bins=bin_edges, density=True)
# 计算KL散度
kl_div_beta1=entropy(hist_weak+1e-6, hist_strong+1e-6) # 添加小常数避免零值
print(f"beta1的KL散度: {kl_div_beta1:.4f}")
2.4 敏感性分析框架
完整的先验敏感性分析应包含以下三个核心组成部分:
- 比较分析:通过多次运行模型评估先验影响的定性特征
- 图形化分析:直观展示后验分布在不同先验设置下的变化
- KL散度分析:提供定量的敏感性度量
这种多层次的分析框架能够提供一下的信息:
- 评估模型对先验假设的敏感程度
- 识别需要特别关注的参数
- 为先验选择提供实证依据
在实际应用中,尤其是在营销组合建模这样的场景中,先验敏感性分析对于确保模型推断的稳健性和可靠性至关重要。通过系统的敏感性分析,可以更好地理解先验选择对渠道效果评估和优化建议的潜在影响。
3. 收敛诊断
收敛诊断是贝叶斯模型验证过程中的关键步骤,其目的是确保马尔可夫链蒙特卡罗(MCMC)采样过程已达到稳定状态,能够有效地从参数的真实后验分布中进行采样。即使模型在表面上很好地拟合了数据,如果没有适当的收敛,其推断结果也可能不可靠。
3.1 收敛的重要性
MCMC方法是贝叶斯推断中最常用的采样技术。其基本原理是通过构建马尔可夫链来从参数的后验分布中抽取样本。然而,这个过程存在两个关键考虑:
- 预热期(Burn-in):采样初期的样本可能受初始值影响,不能代表真实的后验分布
- 链的混合(Mixing):需要确保马尔可夫链充分探索了整个参数空间
只有当采样过程达到稳定状态,即实现了收敛,我们才能确保所得的后验样本能够可靠地代表true posterior分布。
3.2 核心诊断工具
3.2.1 迹线图(Trace Plots)
迹线图展示了参数在MCMC迭代过程中的采样轨迹,是最直观的收敛诊断工具。
importarvizasaz
importmatplotlib.pyplotasplt
# 生成迹线图
az.plot_trace(trace)
plt.show()
评估标准:
- 良好混合:参数值在某个范围内呈现随机波动,无明显趋势
- 混合不良:出现明显的趋势或周期性模式,表明可能未达到收敛
3.2.2 Gelman-Rubin统计量(R-hat)
R-hat统计量通过比较链内方差和链间方差来评估收敛性,是一个定量的诊断指标。
# 计算R-hat值
rhat_values=az.rhat(trace)
print("R-hat统计量:\n", rhat_values)
判断标准:
- R-hat ≈ 1:表明各链已充分混合,达到收敛
- R-hat > 1.1:表明存在收敛问题,需要增加采样或调整模型
3.2.3 有效样本量(ESS)
有效样本量衡量后验样本中独立信息的数量,考虑了样本间的自相关性。
# 计算有效样本量
ess_values=az.ess(trace)
print("有效样本量:\n", ess_values)
评估标准:
- 高ESS:表明采样效率良好,样本间相对独立
- 低ESS:表明样本间存在高度相关性,可能需要增加采样量或改进采样策略
3.3 综合诊断示例
以下是一个完整的收敛诊断分析示例:
importarvizasaz
# 综合诊断分析
# 1. 生成诊断图
az.plot_trace(trace)
plt.show()
# 2. 计算R-hat值
rhat_values=az.rhat(trace)
print("R-hat值:\n", rhat_values)
# 3. 计算有效样本量
ess_values=az.ess(trace)
print("有效样本量:\n", ess_values)
# 4. 生成诊断报告
summary=az.summary(trace, hdi_prob=0.95)
print(summary)
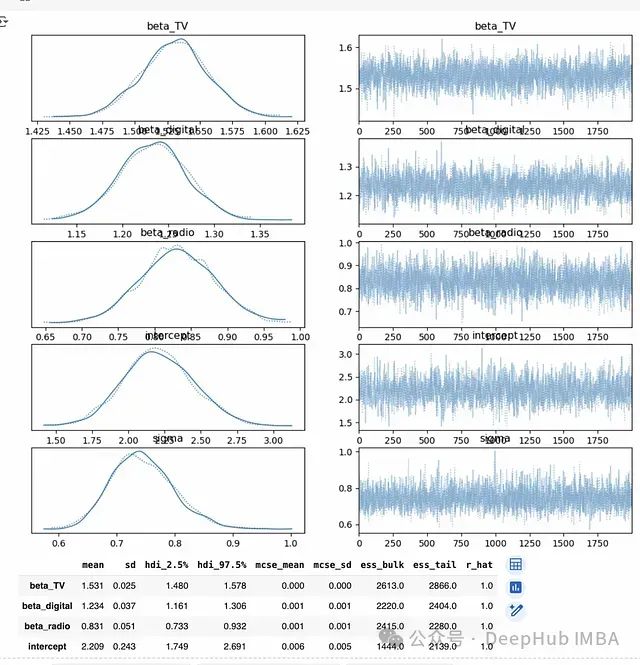
3.4 收敛诊断流程
一个完整的收敛诊断流程应包含:
- 视觉检查:通过迹线图观察参数轨迹的稳定性
- 定量评估:计算并分析R-hat值
- 样本质量评估:检查有效样本量
- 诊断整合:综合多个指标,得出收敛性结论
诊断结果的应用:
- 如果诊断指标显示良好收敛,可以进行后续的参数推断和预测
- 如果发现收敛问题,可采取以下措施:- 增加采样迭代次数- 延长预热期- 调整采样器参数- 重新考虑模型规范
在营销组合建模中,收敛诊断尤为重要,因为模型结果往往直接影响营销资源的分配决策。通过严格的收敛诊断,我们可以确保模型估计的可靠性,为营销决策提供坚实的数据支持。
4. 参数可解释性与后验分析
参数可解释性分析是贝叶斯建模中的核心环节,其目的是深入理解模型参数的统计特性和实际含义。通过系统的后验分析,我们可以评估参数估计的可靠性,并为模型的实际应用提供理论支撑。
4.1 后验分布的中心趋势分析
后验分布的中心趋势度量提供了参数最可能取值的估计。在贝叶斯分析中,常用的中心趋势指标包括:
- 后验均值:参数后验分布的期望值
- 后验中位数:后验分布的中位点,对异常值更稳健
实现示例:
importpymcaspm
importnumpyasnp
importmatplotlib.pyplotasplt
# 构造示例数据
advertising_spend=np.array([10, 20, 30, 40, 50]) # 广告支出
sales=np.array([12, 24, 30, 38, 45]) # 销售额
# 构建贝叶斯模型
withpm.Model() asmodel:
# 定义参数先验
alpha=pm.Normal('alpha', mu=0, sigma=10) # 截距项
beta=pm.Normal('beta', mu=0, sigma=10) # 效应系数
sigma=pm.HalfNormal('sigma', sigma=1) # 误差项标准差
# 构建线性响应函数
mu=alpha+beta*advertising_spend
likelihood=pm.Normal('sales', mu=mu, sigma=sigma, observed=sales)
# 执行后验采样
trace=pm.sample(2000, return_inferencedata=False)
# 计算后验统计量
mean_beta=trace['beta'].mean()
median_beta=np.median(trace['beta'])
# 输出结果
print(f'beta参数的后验均值: {mean_beta:.4f}')
print(f'beta参数的后验中位数: {median_beta:.4f}')
4.2 可信区间分析
可信区间(Credible Interval)提供了参数真实值的概率范围估计,这是贝叶斯推断的一个显著优势。最常用的是95%可信区间,它表示参数真实值有95%的概率落在该区间内。
可信区间的计算:
# 计算beta参数的95%可信区间
credible_interval=np.percentile(trace['beta'], [2.5, 97.5])
print(f'beta参数的95%可信区间: [{credible_interval[0]:.4f}, {credible_interval[1]:.4f}]')
注意事项:
- 可信区间与频率学派的置信区间有本质区别
- 可信区间直接表达了参数取值的概率分布
- 区间宽度反映了参数估计的不确定性
4.3 后验方差分析
后验方差是衡量参数估计不确定性的关键指标。较大的后验方差可能源于:
- 数据信息不足
- 模型结构不当
- 先验假设不准确
方差分析实现:
# 计算后验方差
variance_beta=np.var(trace['beta'])
print(f'beta参数的后验方差: {variance_beta:.4f}')
4.4 诊断方法集成
在实际应用中,应综合运用多种诊断工具进行参数分析:
4.4.1 迹线图分析
迹线图能够直观展示参数采样的稳定性和混合效果:
- 稳定的横向波动表明采样充分
- 趋势或周期性模式表明可能存在收敛问题
4.4.2 R-hat统计量
R-hat值近似1表明不同链之间达到了良好的混合:
- R-hat < 1.1: 表明收敛良好
- R-hat ≥ 1.1: 需要进一步诊断和调整
4.5 参数解释框架
在营销组合建模中,参数解释应遵循以下框架:
- 直接效应解释- 系数的实际含义(如广告支出对销售的边际效应)- 效应的方向和大小
- 不确定性量化- 可信区间的宽度- 后验分布的形状特征
- 业务导向分析- 参数估计的实际应用价值- 对决策制定的指导意义
4.6 实践建议
- 系统性评估- 对所有关键参数进行完整的后验分析- 保持分析过程的一致性和可重复性
- 结果可视化- 使用适当的图形展示后验分布- 突出关键的统计特征
- 文档记录- 详细记录分析过程和结果- 明确说明各项统计量的解释
通过这种系统的参数分析框架,我们可以:
- 确保模型估计的可靠性
- 提供清晰的参数解释
- 支持基于证据的决策制定
在营销组合建模的具体应用中,这种严谨的参数分析方法能够帮助我们更好地理解营销活动的效果,为营销资源的优化配置提供科学依据。
5. 预测准确性与模型校准
预测准确性和模型校准是评估贝叶斯模型性能的关键维度。准确的预测概率分布应当与实际观测结果保持一致,这种一致性通过系统的校准评估来验证。
5.1 概率积分变换(PIT)分析
概率积分变换(Probability Integral Transform,PIT)是一种基础的模型校准诊断工具。其核心思想是:如果模型校准良好,则经过变换的预测概率应在[0,1]区间上呈均匀分布。
5.1.1 PIT分析实现
importpymcaspm
importnumpyasnp
importmatplotlib.pyplotasplt
# 生成示例数据
n=1000
observed_outcomes=np.random.binomial(1, 0.7, n) # 二元实际结果
predicted_probabilities=np.random.uniform(0, 1, n) # 模型预测概率
# 计算PIT值
pit_values= [pm.distributions.dist_math.invlogit(
np.random.normal(loc=pred_prob, scale=0.1))
forpred_probinpredicted_probabilities]
# 绘制PIT直方图
plt.figure(figsize=(8, 6))
plt.hist(pit_values, bins=20, density=True, alpha=0.7, color='navy')
plt.title('概率积分变换(PIT)分析')
plt.xlabel('PIT值')
plt.ylabel('密度')
plt.grid(True, alpha=0.3)
plt.show()
5.1.2 PIT结果解读
- 理想情况:直方图近似均匀分布
- 过度离散:直方图呈U形
- 过度集中:直方图呈倒U形
5.2 校准曲线分析
校准曲线(Calibration Curve)通过比较预测概率与实际观测频率来评估模型的校准程度。
5.2.1 校准曲线实现
# 构建校准曲线
bins=np.linspace(0, 1, 11) # 创建概率分箱
bin_centers= (bins[:-1] +bins[1:]) /2
observed_freq=np.zeros_like(bin_centers)
# 计算每个分箱的观测频率
fori, bin_centerinenumerate(bin_centers):
bin_mask= (predicted_probabilities>=bins[i]) & \
(predicted_probabilities<bins[i+1])
observed_freq[i] =observed_outcomes[bin_mask].mean()
# 绘制校准曲线
plt.figure(figsize=(8, 8))
plt.plot(bin_centers, observed_freq, 'bo-', label='校准曲线')
plt.plot([0, 1], [0, 1], 'r--', label='完美校准')
plt.title('模型校准曲线')
plt.xlabel('预测概率')
plt.ylabel('观测频率')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
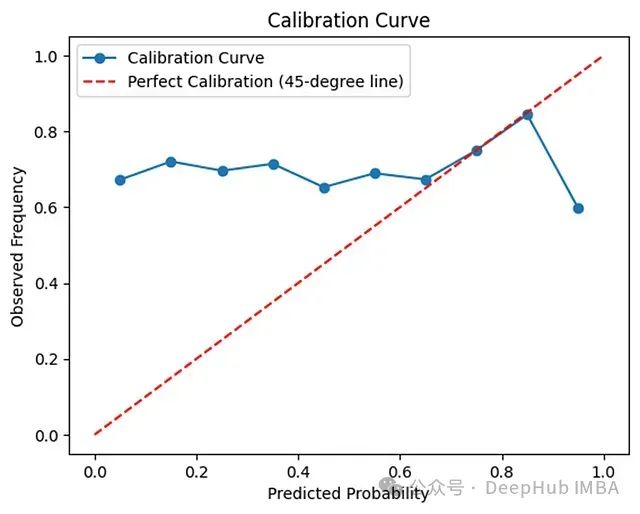
5.2.2 校准曲线评估标准
- 完美校准:曲线与45度对角线重合
- 过度自信:实际曲线偏离对角线,斜率小于1
- 信心不足:实际曲线偏离对角线,斜率大于1
5.3 预测评分指标
5.3.1 布里尔分数(Brier Score)
布里尔分数是二分类预测任务中最常用的校准评估指标。它度量预测概率与实际结果之间的均方误差。
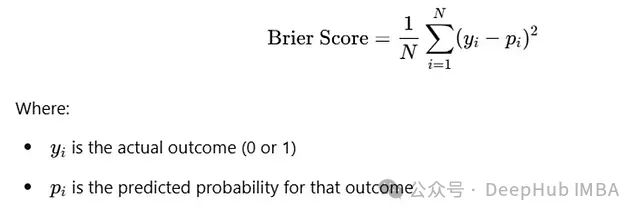
5.3.2 对数分数(Log Score)
对数分数通过对数似然函数评估预测准确性,对预测错误的惩罚更为严重。
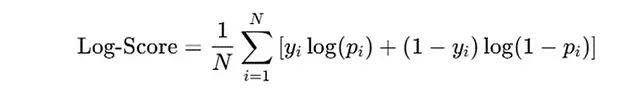
5.3.3 评分指标实现
fromsklearn.metricsimportbrier_score_loss
importscipy.statsasstats
# 计算布里尔分数
brier_score=brier_score_loss(observed_outcomes, predicted_probabilities)
print(f'布里尔分数: {brier_score:.4f}')
# 计算对数分数
log_score=np.mean(
observed_outcomes*np.log(predicted_probabilities) +
(1-observed_outcomes) *np.log(1-predicted_probabilities)
)
print(f'对数分数: {log_score:.4f}')
5.4 综合评估框架
5.4.1 评估维度
- 概率校准- PIT分析- 校准曲线检验
- 预测准确性- 布里尔分数- 对数分数
- 不确定性量化- 预测区间覆盖率- 预测分布的离散程度
5.4.2 应用建议
- 系统性评估- 结合多个评估指标- 关注不同视角的诊断信息
- 持续监控- 定期进行校准检查- 及时发现和处理校准问题
- 实践优化- 根据校准结果调整模型- 平衡预测准确性和模型复杂度
在营销组合建模的应用中,模型校准对于准确评估营销活动的效果至关重要。通过系统的校准分析可以得到:
- 确保预测概率的可靠性
- 提供合理的不确定性估计
- 支持基于风险的决策制定
良好的模型校准是一个持续的过程,需要在模型开发和应用的各个阶段保持持续的关注和优化。
6. 拟合优度评估
在贝叶斯建模中,拟合优度评估需要采用特定的指标和方法,这些方法不仅要考虑模型对观测数据的拟合程度,还要考虑模型的复杂度和泛化能力。本节将重点介绍两个核心指标:WAIC(Watanabe-Akaike信息准则)和LOO(留一法)交叉验证。
6.1 WAIC(Watanabe-Akaike信息准则)
WAIC是经典AIC的贝叶斯版本,它通过评估模型的预测性能和复杂度来进行模型选择。
6.1.1 WAIC的优势
- 完全贝叶斯框架下的信息准则
- 考虑参数的后验不确定性
- 适用于奇异统计模型
6.1.2 计算原理
WAIC由两个主要部分组成:
- 对数预测密度的平均值(衡量拟合优度)
- 有效参数数量的惩罚项(控制模型复杂度)
6.2 LOO交叉验证
LOO交叉验证通过系统地留出每个观测值,评估模型的预测性能。尽管计算密集,但它提供了模型泛化能力的可靠估计。
6.2.1 实现方法
使用PSIS-LOO(Pareto Smoothed Importance Sampling LOO)可以高效地近似完整的LOO交叉验证:
importcmdstanpy
importarvizasaz
importnumpyasnp
importpandasaspd
importjson
# 定义包含对数似然的Stan模型
stan_model_code="""
data {
int<lower=0> N; // 样本数量
array[N] real y; // 响应变量
real mu; // 先验均值
real<lower=0> sigma; // 先验标准差
}
parameters {
real alpha; // 截距
real beta; // 斜率
}
model {
// 先验分布
alpha ~ normal(mu, sigma);
beta ~ normal(mu, sigma);
// 似然函数
y ~ normal(alpha + beta * mu, sigma);
}
generated quantities {
// 计算对数似然
real log_lik = normal_lpdf(y | alpha + beta * mu, sigma);
}
"""
# 保存模型代码
withopen("model.stan", "w") asfile:
file.write(stan_model_code)
# 编译Stan模型
model=cmdstanpy.CmdStanModel(stan_file="model.stan")
# 准备示例数据
N=10
y=np.random.randn(N)
mu=0
sigma=1
# 准备Stan数据
data= {
"N": N,
"y": y.tolist(),
"mu": mu,
"sigma": sigma
}
# 保存数据
withopen("/tmp/data.json", "w") asfile:
json.dump(data, file)
# 执行后验采样
fit=model.sample(
data="/tmp/data.json",
chains=4,
iter_sampling=2000,
iter_warmup=1000
)
# 提取后验样本和对数似然
posterior_samples=fit.stan_variables()
log_lik=fit.stan_variable('log_lik')
# 转换为InferenceData格式
idata=az.from_dict(
posterior=dict(posterior_samples),
log_likelihood={'log_lik': log_lik},
coords={"chains": np.arange(4), "draws": np.arange(2000)},
)
# 计算WAIC和LOO
waic=az.waic(idata)
loo=az.loo(idata)
# 输出结果
print("WAIC结果:")
print(waic)
print("\nLOO结果:")
print(loo)
6.3 模型比较框架
6.3.1 比较指标
- WAIC比较- 较小的WAIC值表示更好的模型- 需考虑WAIC的标准误差
- LOO比较- 比较不同模型的LOO得分- 分析Pareto k诊断以评估可靠性
6.3.2 模型选择流程
- 初步筛选- 基于WAIC/LOO值的排序- 考虑模型复杂度的平衡
- 差异性检验- 计算WAIC/LOO差异的标准误- 评估模型间的显著性差异
- 稳健性分析- 检查不同数据子集上的表现- 评估结果的稳定性
6.4 实践建议
6.4.1 指标选择
- 使用WAIC当:- 需要快速的模型比较- 数据量相对较小- 模型相对简单
- 使用LOO当:- 需要更稳健的评估- 计算资源充足- 模型较为复杂
6.4.2 注意事项
- 计算效率- WAIC计算相对高效- LOO计算可能较为耗时- 考虑使用并行计算
- 结果解释- 考虑估计的不确定性- 结合多个指标综合判断- 注意实际应用场景的需求
- 模型改进- 基于诊断结果进行模型优化- 平衡模型复杂度和预测性能- 考虑业务约束和实际需求
在营销组合建模的具体应用中,拟合优度评估不仅要关注统计意义上的表现,还要考虑模型的实用性和可解释性。通过系统的评估框架,我们可以:
- 选择最适合特定应用场景的模型
- 确保模型预测的可靠性
- 提供稳健的决策支持
拟合优度评估应当是一个持续的过程,需要在模型开发和应用的各个阶段不断进行验证和优化。
7. 贝叶斯模型比较
在贝叶斯营销组合建模中,模型比较是一个系统性的过程,需要综合考虑多个维度的评估指标。本节将从可解释性、预测准确性、计算效率等多个角度,构建完整的模型比较框架。
7.1 比较维度体系
7.1.1 可解释性评估
可解释性是模型能否在实际业务场景中有效应用的关键因素。
评估标准:
- 参数解释的直观性- 参数含义的清晰程度- 与业务概念的对应关系
- 结果理解的难易度- 对非技术人员的可理解性- 结果展示的直观程度
应用建议:
- 对于需要向管理层汇报的场景,优先考虑简单直观的模型结构
- 在技术团队内部分析时,可以接受更复杂的模型形式
7.1.2 预测准确性
预测准确性是模型性能的直接度量,需要通过严格的统计指标进行评估。
核心指标:
- 样本外预测能力- 交叉验证性能- 时序预测准确度
- 预测区间的准确性- 覆盖率评估- 区间宽度分析
7.1.3 业务相关指标
业务相关指标将模型性能与实际应用需求相结合。
关键考量:
- 计算效率- 模型训练时间- 预测生成速度- 资源消耗水平
- 可扩展性- 处理大规模数据的能力- 模型更新的便利性- 与现有系统的集成难度
- 维护成本- 参数调整的复杂度- 模型监控的难易程度- 更新维护的资源需求
7.2 比较方法论
7.2.1 贝叶斯因子分析
贝叶斯因子是比较竞争模型的标准化方法,它通过计算模型间的后验概率比来进行评估。
实施步骤:
- 计算每个模型的边际似然
- 构建模型间的贝叶斯因子
- 解释贝叶斯因子的含义
7.2.2 后验比值分析
后验比值分析考虑了先验信息和观测数据的综合影响。
核心要素:
- 模型后验概率的比较
- 参数估计的不确定性评估
- 预测表现的稳定性分析
7.3 决策理论框架
7.3.1 损失函数设计
在模型选择中,应根据具体应用场景设计合适的损失函数。
常见考虑:
- 预测误差损失- 均方误差- 绝对误差- 自定义业务损失
- 模型复杂度惩罚- 参数数量- 计算复杂度- 维护成本
7.3.2 风险评估
基于损失函数进行系统的风险评估。
评估维度:
- 预测风险- 点预测的准确性- 区间估计的可靠性
- 决策风险- 错误决策的成本- 机会成本的评估
7.4 实践应用指南
7.4.1 模型选择流程
- 初步筛选- 基于基本性能指标- 考虑计算资源约束- 评估实现复杂度
- 深入比较- 详细的统计性能分析- 业务指标的全面评估- 可维护性分析
- 最终决策- 综合多维度评分- 考虑实际应用约束- 平衡各项指标
7.4.2 实施建议
- 文档记录- 记录比较过程- 保存评估结果- 维护决策依据
- 持续优化- 定期重新评估- 收集实际应用反馈- 及时调整优化策略
- 知识管理- 建立模型库- 积累比较经验- 形成最佳实践
在营销组合建模的具体应用中,模型比较不应局限于单一维度的评估,而应该:
- 建立多维度的评估体系
- 考虑实际应用场景的需求
- 平衡统计性能和业务价值
- 确保决策的可操作性
通过系统的模型比较框架,我们可以选择最适合特定应用场景的模型,并为营销决策提供可靠的支持。这个过程应该是动态的、持续的,需要根据实际应用效果不断进行调整和优化。
8. 贝叶斯模型的假设与局限性
在贝叶斯建模实践中,清晰理解和明确模型的基本假设与局限性至关重要。这不仅有助于正确解释模型结果,也能为模型改进提供明确方向。本节将系统探讨贝叶斯营销组合模型中的核心假设和潜在局限。
8.1 线性性假设
线性性假设是许多贝叶斯模型的基础,它假定预测变量与响应变量之间存在线性关系。
8.1.1 假设验证方法
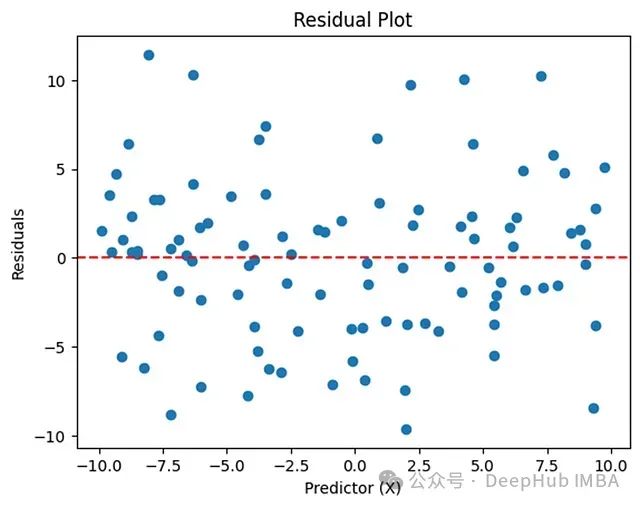
主要通过残差分析来评估线性性假设:
importpymcaspm
importnumpyasnp
importmatplotlib.pyplotasplt
# 生成示例数据
np.random.seed(42)
X=np.random.uniform(-10, 10, 100) # 预测变量
y=3*X+np.random.normal(0, 5, 100) # 响应变量
# 构建贝叶斯线性模型
withpm.Model() asmodel:
# 定义先验分布
alpha=pm.Normal('alpha', mu=0, sigma=10)
beta=pm.Normal('beta', mu=0, sigma=10)
sigma=pm.HalfNormal('sigma', sigma=1)
# 定义似然函数
likelihood=pm.Normal('y', mu=alpha+beta*X, sigma=sigma, observed=y)
# 执行后验采样
trace=pm.sample(1000, return_inferencedata=False)
# 计算预测值和残差
y_pred=trace['alpha'][:, None] +trace['beta'][:, None] *X
residuals=y-y_pred.mean(axis=0)
# 绘制残差图
plt.figure(figsize=(10, 6))
plt.scatter(X, residuals, alpha=0.5)
plt.axhline(0, color='r', linestyle='--')
plt.xlabel('预测变量')
plt.ylabel('残差')
plt.title('残差分析图')
plt.grid(True, alpha=0.3)
plt.show()
8.1.2 应对策略
- 引入非线性变换
- 采用更复杂的函数形式
- 使用非参数化方法
8.2 残差正态性
残差正态性假设对于参数估计和不确定性量化具有重要影响。
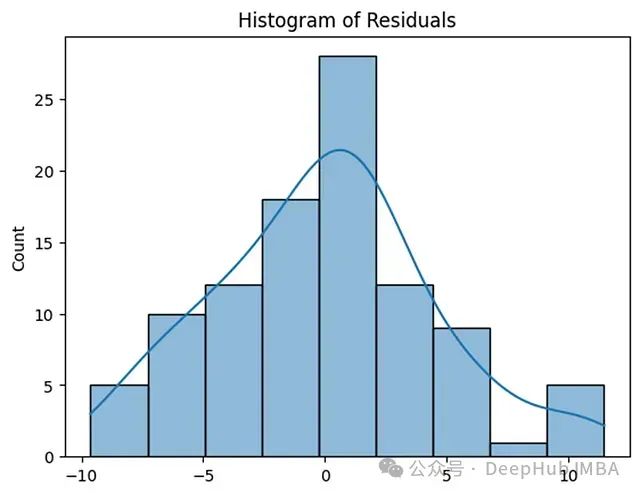
8.2.1 正态性检验
通过图形和统计方法验证残差分布:
importseabornassns
importscipy.statsasstats
# 残差分布分析
plt.figure(figsize=(12, 5))
# 直方图
plt.subplot(121)
sns.histplot(residuals, kde=True)
plt.title('残差分布直方图')
# Q-Q图
plt.subplot(122)
stats.probplot(residuals, dist="norm", plot=plt)
plt.title('残差Q-Q图')
plt.tight_layout()
plt.show()
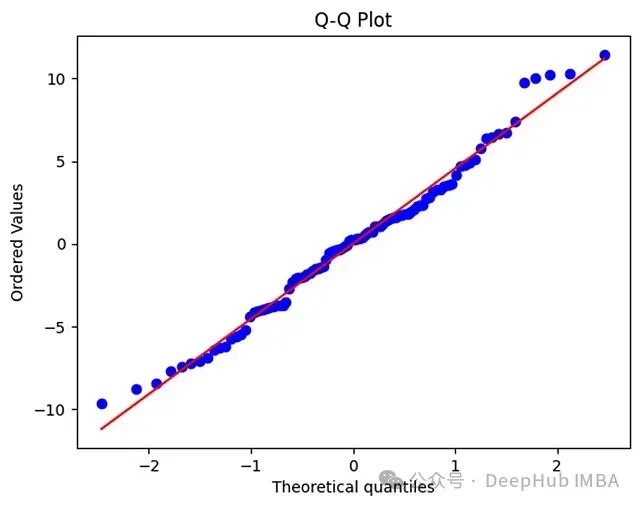
8.2.2 偏离处理
- 轻度偏离- 使用稳健的似然函数- 采用t分布替代正态分布
- 严重偏离- 考虑数据转换- 使用非参数方法- 采用混合分布模型
8.3 计算资源约束
8.3.1 计算效率优化
- 采样策略优化- 使用高效的MCMC算法- 优化预热期设置- 调整采样参数
- 计算加速方法- 并行计算实现- 变分推断近似- 模型简化策略
8.3.2 资源管理建议
- 根据数据规模选择适当的算法
- 在精度和效率间寻找平衡
- 建立计算资源监控机制
8.4 数据质量要求
8.4.1 数据质量问题
- 数据稀疏性- 样本量不足- 特征覆盖不全- 时间序列不连续
- 数据噪声- 测量误差- 异常值影响- 系统性偏差
8.4.2 数据质量提升策略
- 数据增强技术- 合成数据生成- 特征工程- 多源数据整合
- 稳健性提升- 异常值处理- 缺失值填补- 数据平滑处理
8.5 综合改进框架
8.5.1 假设验证流程
- 系统检验- 明确验证目标- 选择适当方法- 设定判断标准
- 结果评估- 量化偏离程度- 评估影响范围- 确定改进优先级
8.5.2 局限性应对
- 方法层面- 模型结构优化- 算法效率提升- 诊断工具完善
- 实践层面- 预期管理- 结果解释规范- 应用场景界定
8.5.3 持续优化建议
- 监控体系- 建立监控指标- 定期检查评估- 记录优化效果
- 知识积累- 总结最佳实践- 建立问题库- 更新优化方法
8.6 实践指导要点
- 假设验证- 系统性检验关键假设- 量化评估偏离程度- 明确改进优先级
- 局限性管理- 清晰认识模型局限- 合理设定应用边界- 制定应对策略
- 持续优化- 建立评估体系- 积累改进经验- 更新优化方法
在贝叶斯营销组合建模中,明确理解并妥善处理模型假设和局限性对于确保模型的有效应用至关重要。通过系统的假设验证和局限性管理,我们可以:
- 提高模型可靠性
- 明确应用边界
- 持续改进模型性能
- 确保决策支持的质量
这个过程应该是动态和持续的,需要根据实际应用效果不断调整和优化。
总结
本文系统阐述了基于MCMC的贝叶斯营销组合模型评估方法论,从理论基础到实践应用建立了一个完整的评估框架。通过严谨的理论框架和实用的技术工具,我们不仅提高了模型的可靠性,也为实践应用提供了明确的指导。
通过这种系统化和动态的评估方法,我们可以不断提升贝叶斯营销组合模型的应用价值,为营销决策提供更加可靠的数据支持。