
在数据科学和机器学习领域,构建可靠且稳健的模型是进行准确预测和获得有价值见解的关键。然而当模型中的变量开始呈现出高度相关性时,就会出现一个常见但容易被忽视的问题 —— 多重共线性。多重共线性是指两个或多个预测变量之间存在强相关性,导致模型难以区分它们对目标变量的贡献。如果忽视多重共线性,它会扭曲模型的结果,导致系数的可靠性下降,进而影响决策的准确性。本文将深入探讨多重共线性的本质,阐述其重要性,并提供有效处理多重共线性的方法,同时避免数据科学家常犯的陷阱。
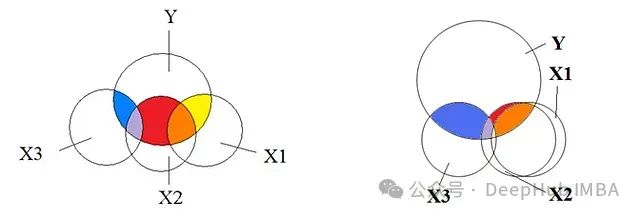
多重共线性的定义
多重共线性是指数据集中两个或多个自变量(预测变量)之间存在强烈的线性相关性。简而言之,这些自变量包含了重叠的信息,而不是提供预测因变量(目标变量)所需的唯一信息,使得模型难以确定每个自变量的individual贡献。
在回归分析中,自变量(independent variable)是影响结果的因素,而因变量(dependent variable)是我们试图预测的结果。举个例子,在房价预测模型中,房屋面积、卧室数量和地理位置等因素被视为自变量,而房价作为因变量,取决于这些自变量的变化。
为了充分理解多重共线性的影响,我们需要先了解线性回归的一些知识。
线性回归
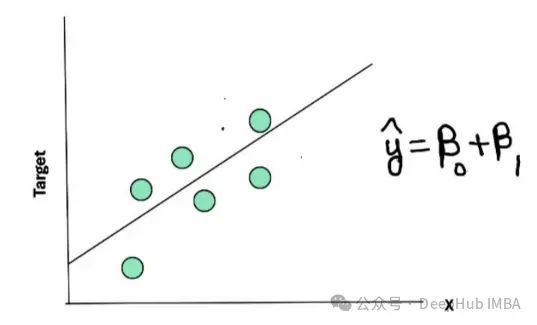
假设我们有一组用绿点表示的数据,我们希望通过这些点拟合一条直线来进行预测。穿过这些点的直线被称为回归线,它对数据进行了概括和总结。
在这个简单的例子中,目标变量(房价)是因变量,我们使用一个自变量(如房屋面积)来预测它。一个简单线性回归的方程可以表示为:
ŷ = β₀ + β₁X
其中:
- ŷ 表示预测值(回归线上的一个点)。
- X 表示自变量的值。
- β₀ 表示截距(回归线与y轴的交点)。
- β₁ 表示斜率(回归线的斜率)。
实际数据点与预测值(ŷ)之间的差异被称为残差(residual)或误差(error):
残差 = yᵢ - ŷᵢ
其中:
- yᵢ 表示第i个观测值的实际值。
- ŷᵢ 表示第i个观测值的预测值。
线性回归的目标是通过最小化残差平方和来找到最佳拟合直线,使得预测值与实际值之间的差异最小。
多个自变量的情况
在多元线性回归中,我们使用多个自变量来预测因变量,其方程可以表示为:
ŷ = β₀ + β₁X₁ + β₂X₂ + … + βₚXₚ
其中:
- X₁, X₂, …, Xₚ 表示不同的自变量(如房屋面积、卧室数量、地理位置等)。
- β₁, β₂, …, βₚ 表示各个自变量对应的回归系数。
我们希望每个自变量对目标变量有其独特的贡献。虽然因变量与自变量之间的相关性是我们所期望的,但自变量之间的相关性却是我们需要避免的。例如,我们不希望出现以下情况:
X₂ = β₀ + β₁X₁
这就是多重共线性的表现 —— 自变量之间表现出类似因变量的线性关系,给模型的训练和推断带来了混淆和不确定性。
为何需要处理多重共线性?
让我们通过一个简单的例子来理解多重共线性的影响。考虑以下用于预测目标变量ŷ的方程:
ŷ = 10 + 2X₁ + 5X₂
假设 X₁ 和 X₂ 之间存在强相关性,我们可以将它们的关系表示为:
X₁ = X₂ + 1
那么,原始方程可以转化为以下两种形式:
- ŷ = 12 + 0X₁ + 9X₂
- ŷ = 7.5 + 4.5X₁ + 0X₂
现在,我们有三个不同的方程来预测 ŷ ,这导致模型产生了混淆:
- 截距项(intercept)应该是10、12还是7.5?
- X₁ 和 X₂ 的系数(coefficients)应该如何确定?
由于 X₁ 和 X₂ 之间的相关性,回归系数变得不稳定和不可靠。随着多重共线性程度的增加,模型中的系数估计会出现更大的波动,导致模型的不稳定和不可靠。这种不确定性使得我们难以解释自变量和因变量之间的真实关系,这就是为什么有效处理多重共线性至关重要。
选择合适的多重共线性处理方法
处理多重共线性有多种有效的方法。以下是一些常用的技术:
- 从相关变量对中移除一个特征: 如果两个变量高度相关,可以考虑移除其中一个,以减少冗余信息。
- 检查方差膨胀因子(VIF): 识别具有高VIF值的特征,这表明存在多重共线性。移除高VIF特征有助于提高模型的稳定性。
- 使用主成分分析(PCA)进行数据转换: PCA通过创建原始变量的线性组合来降低数据维度,从而消除多重共线性。
- 应用岭回归(Ridge Regression)或Lasso回归: 这些正则化技术通过收缩回归系数来减轻多重共线性的影响。岭回归通过最小化系数的L2范数来实现,而Lasso回归则通过最小化系数的L1范数,可以将一些系数压缩为零。
需要避免的常见错误
- 盲目移除相关特征: 这种方法在只有少数特征相关的情况下是可行的,但如果存在大量相关特征,则可能不太实用。
- 过度依赖PCA: 尽管PCA在减轻多重共线性方面非常有效,但新生成的变量可解释性较差,这使得向非技术利益相关者解释结果变得更具挑战性。
- 对岭回归和Lasso回归的误解: 虽然这些方法可以减轻多重共线性的影响,但它们主要是正则化技术。它们并不能完全"治愈"多重共线性,而是通过调整系数来帮助控制其影响。
考虑到这些局限性,我们通常会将 方差膨胀因子(VIF) 作为识别和处理多重共线性的最有效工具之一。VIF可以帮助我们确定导致多重共线性的特征,从而做出明智的决策,在保持模型可解释性的同时提高其稳定性。
方差膨胀因子(VIF)
方差膨胀因子(VIF)是一种统计度量,用于检测回归模型中是否存在多重共线性。它量化了由于自变量之间的多重共线性而导致的回归系数方差的膨胀程度。VIF告诉我们其他自变量对特定预测变量方差的影响程度。
为了更好地理解VIF,让我们先回顾一下回归分析中的一个关键概念:决定系数(coefficient of determination),也称为R²。R²用于评估回归模型对数据的拟合优度。例如,R² = 0.9意味着目标变量(ŷ)中90%的变异可以由模型中的自变量解释。
VIF的工作原理
VIF通过以下步骤帮助我们识别和消除模型中的多重共线性:
步骤1: 对每个自变量建立一个线性回归模型,使用数据集中的其他自变量作为预测变量。这意味着我们不是直接预测目标变量(ŷ),而是尝试用其他自变量来解释每个自变量。
例如:
- X₁ = αX₂ + αX₃ + … + αXₚ
- X₂ = θX₁ + θX₃ + … + θXₚ
- X₃ = δX₁ + δX₂ + … + δXₚ
在VIF的计算过程中,我们为每个自变量拟合一个线性回归模型,使用数据集中其余的自变量作为预测变量。
步骤2: 对于每个线性回归模型,我们计算决定系数R²。这给出了每个自变量的R²值(记为R²ᵢ),表示其他自变量能够解释该自变量变异性的程度。
步骤3: 使用以下公式计算每个自变量的VIF:
- VIFᵢ = 1 / (1 - R²ᵢ)
这个公式表明,当R²ᵢ增加时,VIF也会随之增加。例如:
- 如果R²ᵢ = 1,则VIFᵢ = ∞(完全多重共线性)。
- 如果R²ᵢ = 0.9,则VIFᵢ = 10。
- 如果R²ᵢ = 0.8,则VIFᵢ = 5。
VIF值较高表示该自变量与其他自变量高度共线,这可能会扭曲回归系数的估计。
基于VIF的特征选择
基于VIF的特征选择通常以迭代的方式进行。这意味着我们每次移除一个具有高VIF值的特征,然后重新计算剩余特征的VIF值。重复这个过程,直到所有特征的VIF值都低于设定的阈值(通常为5或10)。
由于移除一个特征会影响其他特征之间的多重共线性,因此在每次移除后重新计算VIF值很重要,以确保模型逐步变得更加稳定和可靠。
Python代码示例
以下是一段使用Python实现VIF计算和基于VIF的特征选择的代码示例:
fromstatsmodels.stats.outliers_influenceimportvariance_inflation_factor
fromstatsmodels.tools.toolsimportadd_constant
defcalculate_vif(X):
"""
计算给定自变量矩阵X的方差膨胀因子(VIF)
"""
# 添加常数项
X=add_constant(X)
# 计算每个特征的VIF
vif=pd.Series([variance_inflation_factor(X.values, i)
foriinrange(X.shape[1])],
index=X.columns)
returnvif
defvif_feature_selection(X, threshold=5):
"""
基于VIF的特征选择
"""
vif=calculate_vif(X)
whilevif.max() >threshold:
# 移除具有最大VIF值的特征
feature_to_remove=vif.idxmax()
X=X.drop(columns=[feature_to_remove])
# 重新计算VIF
vif=calculate_vif(X)
returnX
# 使用示例
selected_features=vif_feature_selection(X)
在这个示例中,我们定义了两个函数:
calculate_vif(X):计算给定自变量矩阵X的VIF值。它首先为X添加一个常数项,然后使用variance_inflation_factor()函数计算每个特征的VIF。vif_feature_selection(X, threshold=5):基于VIF进行特征选择。它重复计算VIF并移除具有最大VIF值的特征,直到所有特征的VIF值都低于给定的阈值(默认为5)。
这段代码演示了如何使用VIF进行多重共线性检测和特征选择的完整过程。将其应用于自己的数据集,以识别和处理多重共线性问题。
总结
理解和处理多重共线性对于构建可靠和可解释的回归模型至关重要。当自变量之间存在高度相关性时,可能导致回归系数估计不稳定、标准误差膨胀以及模型预测不可靠。通过使用移除相关特征、主成分分析(PCA)、岭回归或Lasso回归等技术,我们可以有效地减轻多重共线性的影响。
在众多处理多重共线性的方法中,方差膨胀因子(VIF)脱颖而出,成为识别和量化多重共线性影响的实用工具。通过计算每个自变量的VIF值,我们能够确定导致多重共线性的特征,并采取相应的措施,以确保模型的稳健性和可解释性。
总的来说,恰当地处理多重共线性可以提高模型的性能,增强结果的可解释性,并确保我们的预测建立在稳定可靠的系数估计之上。通过有策略地应用这些方法,我们能够构建出不仅准确,而且更加可靠和易于理解的模型。