
Deephub
更多文章请关注公众号:Deephub-IMBA
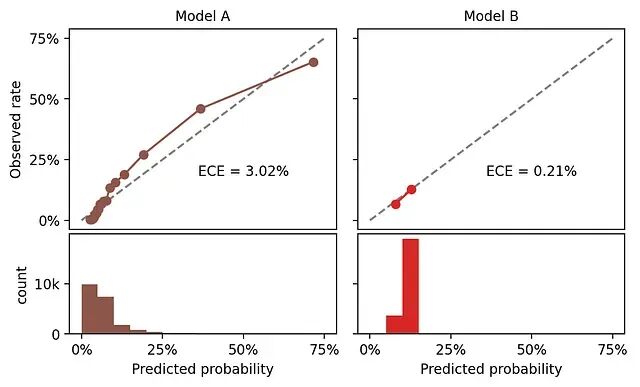
分类模型校准:ROC-AUC不够?用ECE/pMAD评估概率质量
这里校准的定义是:如果模型给一批样本都预测了25%的正例概率,那这批样本中实际的正例比例应该接近25%。这就是校准。
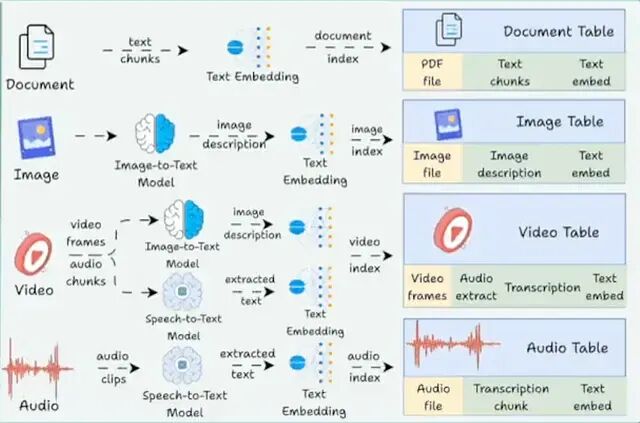
Pixeltable:一张表搞定embeddings、LLM、向量搜索,多模态开发不再拼凑工具
Pixeltable提供了一个统一的声明式接口,文档、embeddings、图像、视频、LLM 输出、分块文本、对话历史、工具调用这些东西,全部以表的形式存在
JAX 核心特性详解:纯函数、JIT 编译、自动微分等十大必知概念
如果你用过 NumPy 或 PyTorch,但还没接触过 JAX,这篇文章能帮助你快速上手。
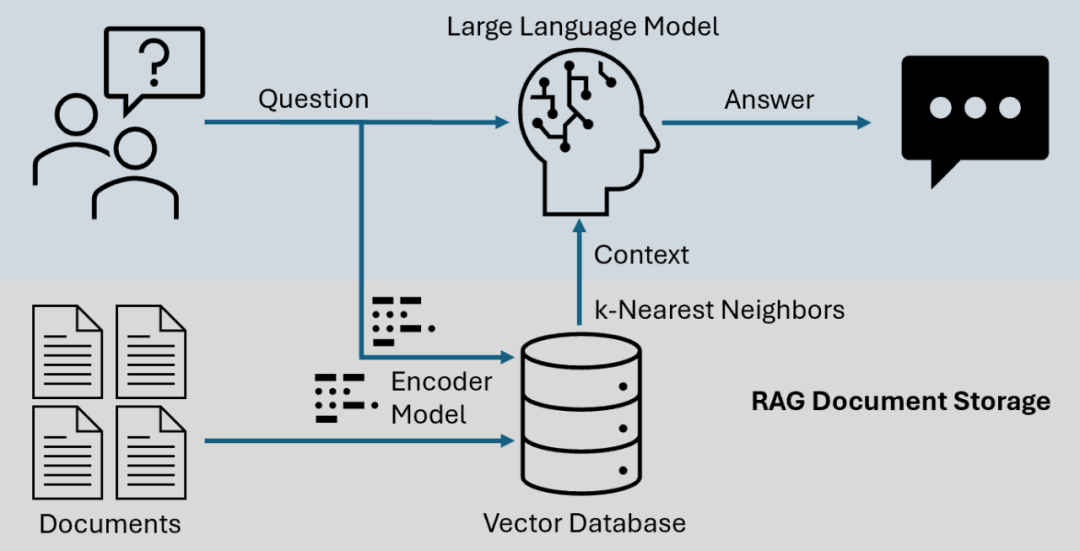
高级检索增强生成系统:LongRAG、Self-RAG 和 GraphRAG 的实现与选择
检索增强生成(RAG)早已不是简单的向量相似度匹配加 LLM 生成这一套路。LongRAG、Self-RAG 和 GraphRAG 代表了当下工程化的技术进展,它们各可以解决不同的实际问题。
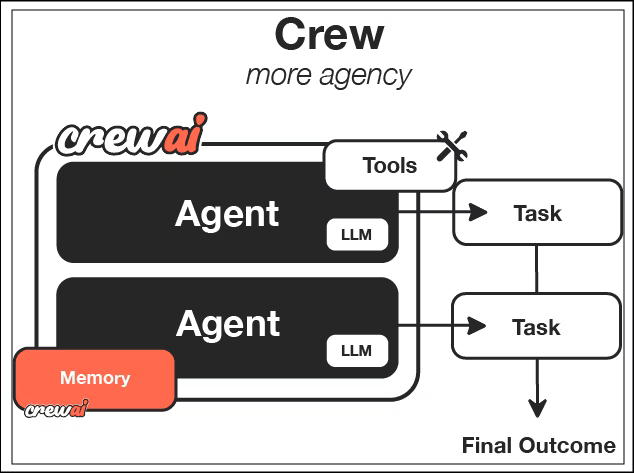
CrewAI 上手攻略:多 Agent 自动化处理复杂任务,让 AI 像员工一样分工协作
CrewAI是一个可以专门用来编排**自主 AI 智能体(Autonomous AI Agents)** 的Python 框架
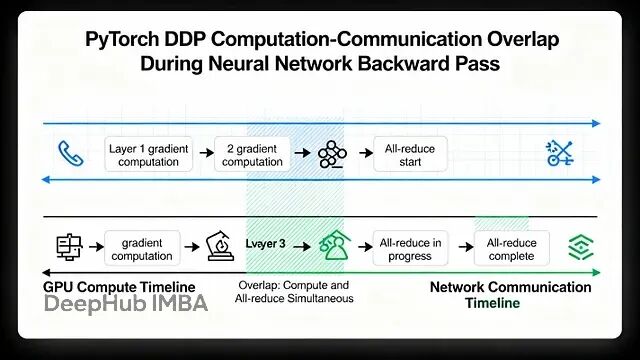
PyTorch 分布式训练底层原理与 DDP 实战指南
本文讲详细探讨Pytorch的数据并行(Data Parallelism)

谷歌Gemini 3 Pro发布:碾压GPT-5.1,AI大战进入三国杀时代
这是第一个突破1500大关的AI模型

LEANN:一个极简的本地向量数据库
LEANN嵌入式、轻量级的向量数据库

Pandas GroupBy 的 10 个实用技巧
本文将介绍10个实际工作中比较有用的技巧,文章的代码都是可以直接拿来用。

TOON:专为 LLM 设计的轻量级数据格式
这几天好像这个叫 TOON 的东西比较火,我们这篇文章来看看他到底是什么,又有什么作用。TOON 全称 Token-Oriented Object Notation,它主要解决的问题就是当你把JSON 输入给LLM 的时候,token 消耗太高了。

Python 3.14 实用技巧:10个让代码更清晰的小改进
Python 3.14 引入的改进大多数都很细微,但这些小变化会让代码写起来更流畅,运行也更稳定。本文整理了 10 个实用的特性改进,每个都配了代码示例。

Python 开发必备:tempfile 模块深度解析
Python 的 ``` tempfile ``` 模块提供了一套完整的解决方案,这些临时文件和目录在不需要的时候会自动清理掉。
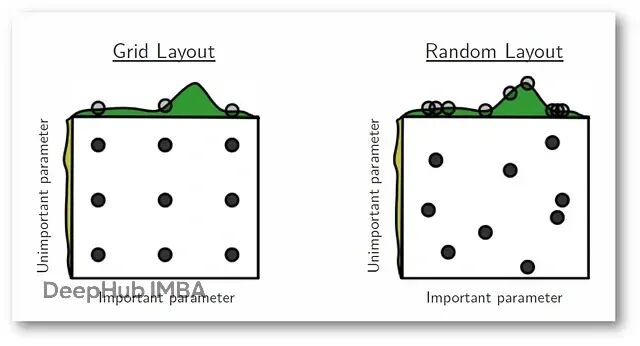
超参数调优:Grid Search 和 Random Search 的实战对比
这篇文章会把Grid Search和Random Search这两种最常用的超参数优化方法进行详细的解释。从理论到数学推导,从优缺点到实际场景,再用真实数据集跑一遍看效果。
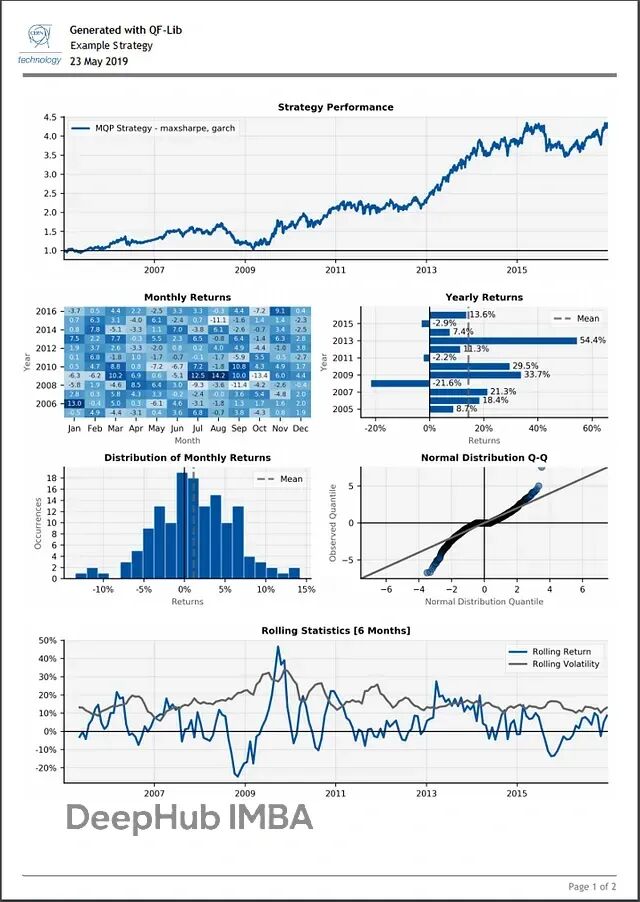
QF-Lib:用一个库搞定Python量化回测和策略开发
QF-Lib(Quantitative Finance Library)是个金融研究和回测工具包。从数据获取到策略模拟、风险评估,再到最后的报告生成,基本能在这一个工具里搞定。

HaluMem:揭示当前AI记忆系统的系统性缺陷,系统失效率超50%
ArXiv最近一篇名为"HaluMem: Evaluating Hallucinations in Memory Systems of Agents"的论文提供了一个非常最新可靠的诊断工具。
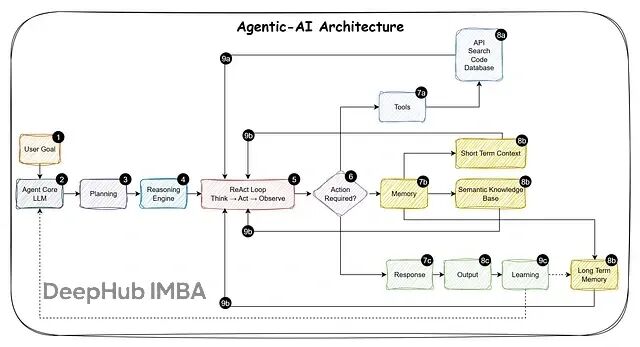
AI智能体落地:Agent-Assist vs 全自动化完整决策指南
这些智能体该完全自主运行,还是应该保持人类在关键决策环节?
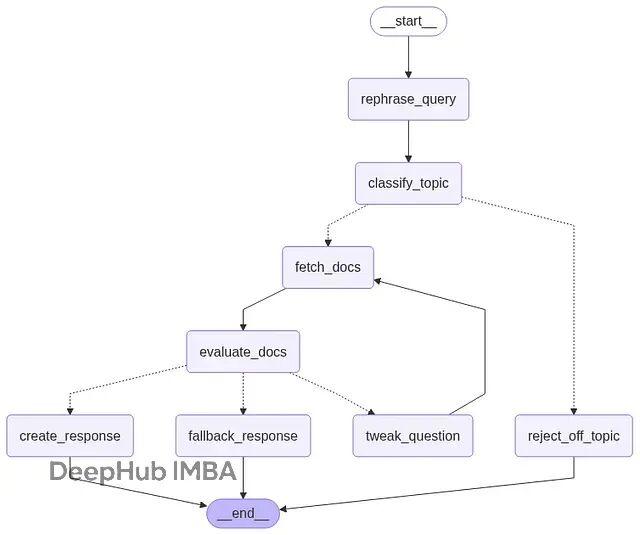
基于 LangGraph 的对话式 RAG 系统实现:多轮检索与自适应查询优化
这篇文章会展示怎么用 LangGraph 构建一个具备实用价值的 RAG 系统,包括能够处理后续追问、过滤无关请求、评估检索结果的质量,同时保持完整的对话记忆。
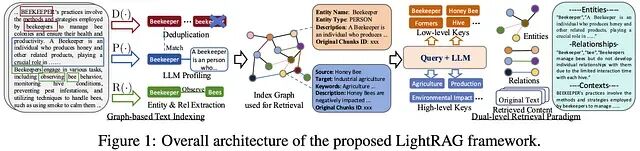
LightRAG 实战: 基于 Ollama 搭建带知识图谱的可控 RAG 系统
LightRAG 是一款开源、模块化的检索增强生成(RAG)框架,支持快速构建基于知识图谱与向量检索的混合搜索系统。它兼容多种LLM与嵌入模型,如Ollama、Gemini等,提供灵活配置和本地部署能力,助力高效、准确的问答系统开发。

TensorRT 和 ONNX Runtime 推理优化实战:10 个降低延迟的工程技巧
低延迟不靠黑科技就是一堆小优化叠起来:形状固定、减少拷贝、更好的 kernel、graph capture、运行时零意外。每个单拎出来可能只省几毫秒,但加起来用户就能感受到"快"。
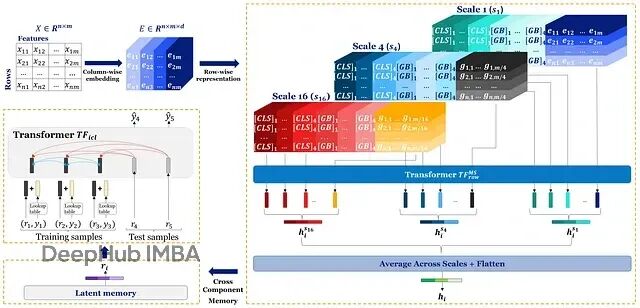
Orion-MSP:深度学习终于在表格数据上超越了XGBoost
Orion-MSP通过多尺度处理捕获不同粒度的特征交互;块稀疏attention把复杂度降到接近线性;Perceiver-style memory实现ICL-safe的双向信息共享。