
Deephub
更多文章请关注公众号:Deephub-IMBA
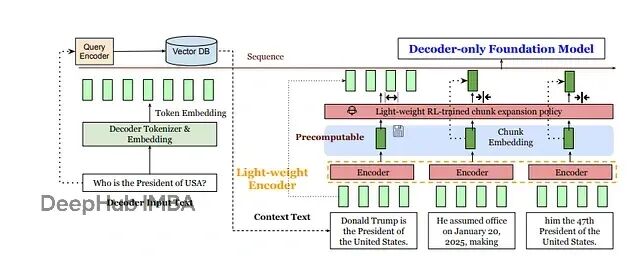
REFRAG技术详解:如何通过压缩让RAG处理速度提升30倍
meta提出了一个新的方案REFRAG:与其让LLM处理成千上万个token,不如先用轻量级编码器(比如RoBERTa)把每个固定大小的文本块压缩成单个向量,再投影到LLM的token嵌入空间。

RAG检索质量差?这5种分块策略帮你解决70%的问题
固定分块、递归分块、语义分块、结构化分块、延迟分块,每种方法在优化上下文理解和检索准确性上都有各自的价值。用对了方法,检索质量能提升一大截,幻觉问题也会少很多。
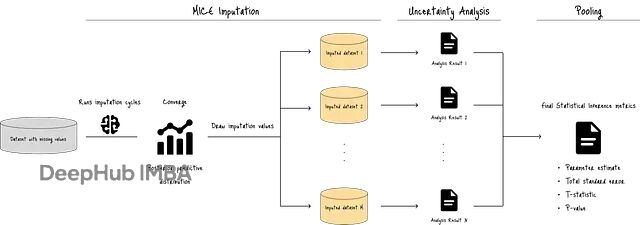
别再用均值填充了!MICE算法教你正确处理缺失数据
本文会通过PMM(Predictive Mean Matching)和线性回归等具体方法,拆解MICE的工作原理,同时对比标准回归插补作为参照。
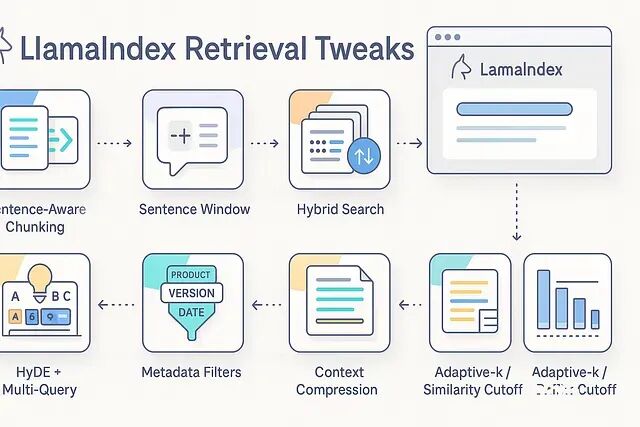
LlamaIndex检索调优实战:分块、HyDE、压缩等8个提效方法快速改善答案质量
分块策略、混合检索、重排序、HyDE、上下文压缩、元数据过滤、自适应k值——八个实用技巧快速改善检索质量
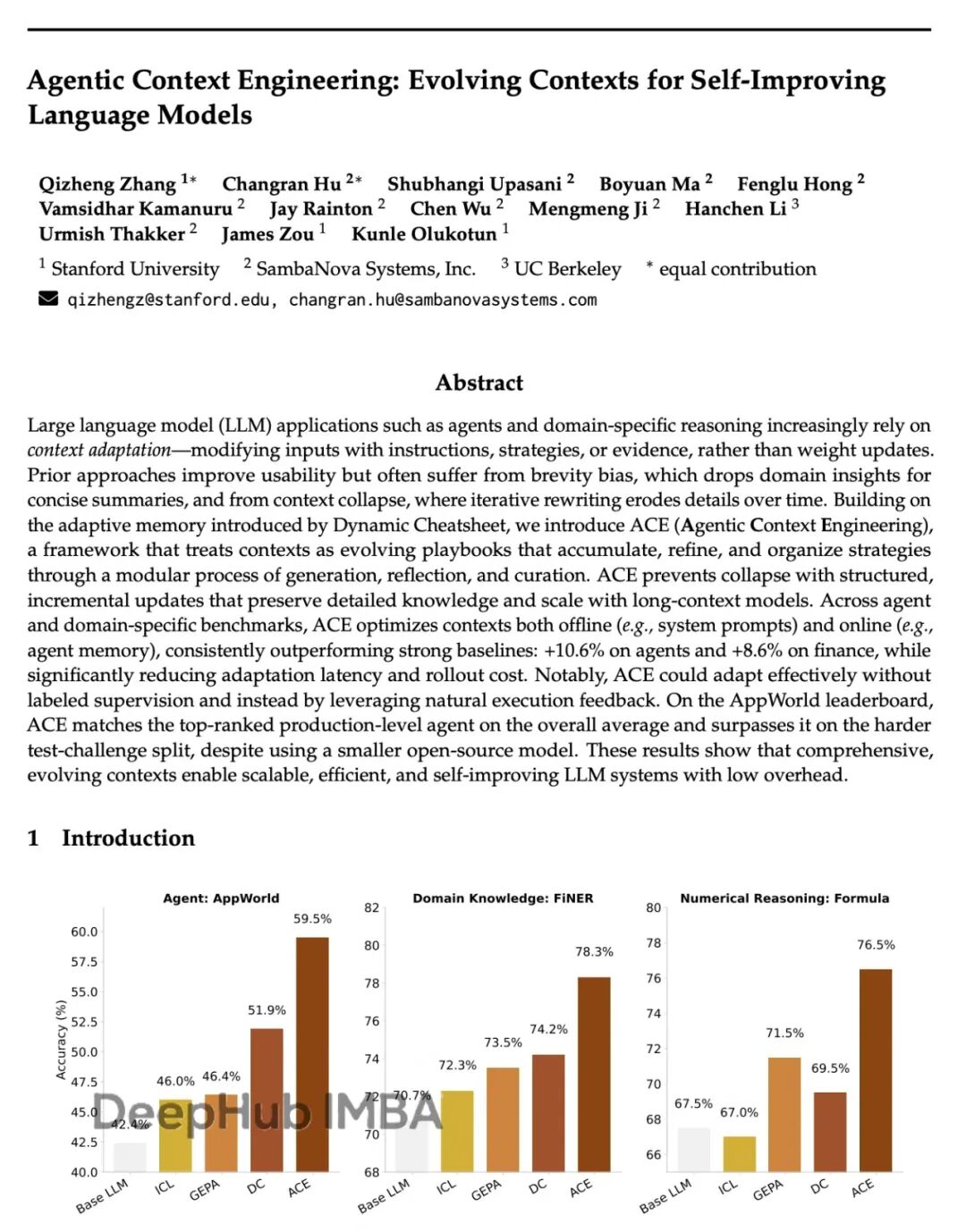
斯坦福ACE框架:让AI自己学会写prompt,性能提升17%成本降87%
Agentic Context Engineering (ACE)。核心思路:不碰模型参数,专注优化输入的上下文。让模型自己生成prompt,反思效果,再迭代改进。

氛围编程陷阱:为什么AI生成代码正在制造大量"伪开发者"
这是一篇再国外讨论非常火的帖子,我觉得不错所以把它翻译成了中文。

12 种 Pandas 测试技巧,让数据处理少踩坑
下面这 12 个策略是实际项目里反复使用的测试方法,能让数据处理代码变得比较靠谱。

mmBERT:307M参数覆盖1800+语言,3万亿tokens训练
mmBERT是一个纯编码器架构的语言模型,在1800多种语言、3万亿tokens的文本上完成了预训练。
vLLM 吞吐量优化实战:10个KV-Cache调优方法让tokens/sec翻倍
十个经过实战检验的 vLLM KV-cache 优化方法 —— 量化、分块预填充、前缀重用、滑动窗口、ROPE 缩放、后端选择等等 —— 提升 tokens/sec。

vLLM推理加速指南:7个技巧让QPS提升30-60%
下面这些是我在实际项目里反复用到的几个调优手段,有代码、有数据、也有一些踩坑经验。
打造自主学习的AI Agent:强化学习+LangGraph代码示例
本文会从RL的数学基础讲起,然后深入到知识图谱的多跳推理,最后在LangGraph框架里搭建一个RL驱动的智能系统。
向量存储vs知识图谱:LLM记忆系统技术选型
要让LLM准确提取历史信息、理解过往对话并建立信息关联,需要相当复杂的系统架构。
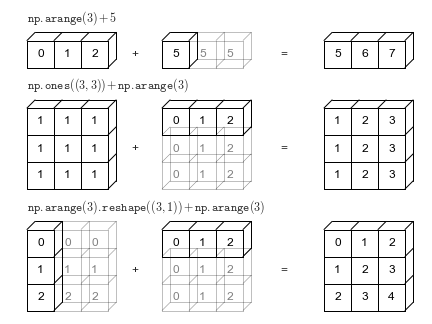
NumPy广播:12个技巧替代循环,让数组计算快40倍
广播是NumPy里最让人恍然大悟的特性。掌握后能去掉大量循环,让代码意图更清晰,同时获得向量化带来的性能提升——而且不需要引入什么复杂工具。

Google开源Tunix:JAX生态的LLM微调方案来了
**Tunix(Tune-in-JAX)**是一个**用于LLM后训练的JAX原生库**,旨在通过JAX的速度和可扩展性简化监督微调、强化学习和蒸馏,可以与Flax NNX无缝集成。
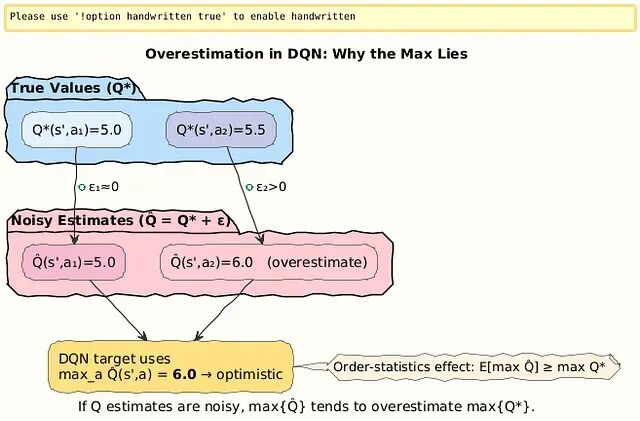
从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
DQN的过估计源于max操作符偏好噪声中的高值。Double DQN把动作选择(在线网络θ)和价值评估(目标网络θ^−)分开处理,
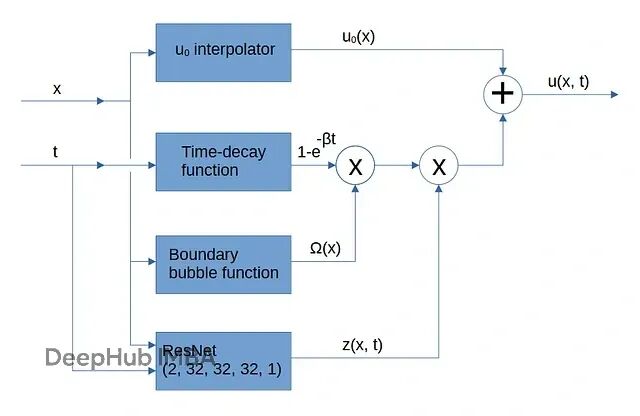
PINN训练新思路:把初始条件和边界约束嵌入网络架构,解决多目标优化难题
PINNs出了名的难训练。主要原因之一就是这个**多目标优化**问题。优化器很容易找到投机取巧的路径
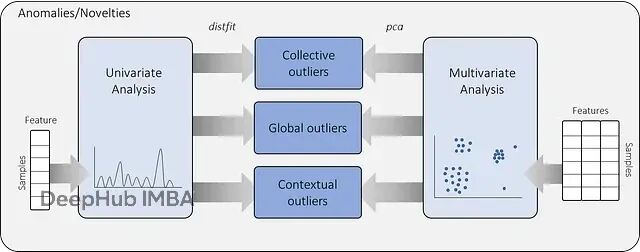
Python离群值检测实战:使用distfit库实现基于分布拟合的异常检测
本文会先讲清楚异常检测的核心概念,分析anomaly和novelty的区别,然后通过实际案例演示如何用概率密度拟合方法构建单变量数据集的无监督异常检测模型。所有代码基于distfit库实现。
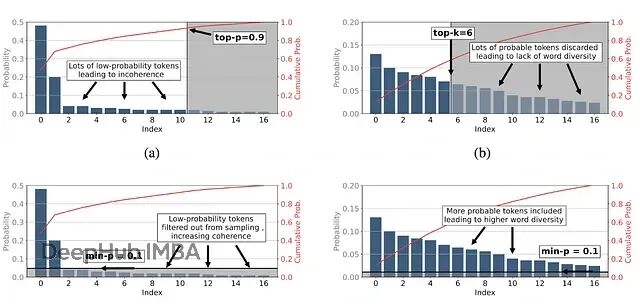
Min-p采样:通过动态调整截断阈值让大模型文本生成兼顾创造力与逻辑性
Min-p 采样的出现为大语言模型文本生成领域带来了新的思路。它通过动态调整采样阈值,让模型能够在不同的上下文中灵活地平衡创造性与连贯性
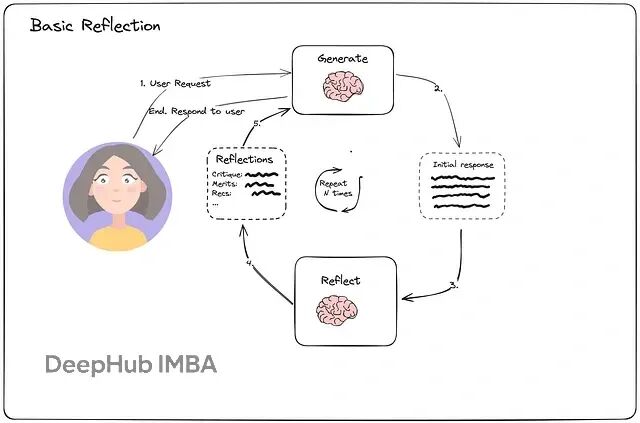
从零构建能自我优化的AI Agent:Reflection和Reflexion机制对比详解与实现
本文重点讨论Reflection和Reflexion,并用LangChain与LangGraph来实现完整的工作流程。
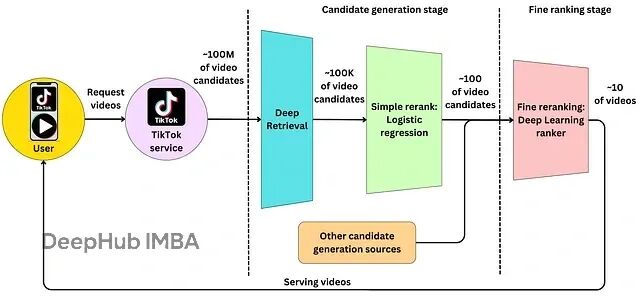
从零构建短视频推荐系统:双塔算法架构解析与代码实现
本文将从技术角度剖析:双塔架构的工作原理、为何在短视频场景下表现卓越,以及如何构建一套类似的推荐系统。