
Deephub
更多文章请关注公众号:Deephub-IMBA
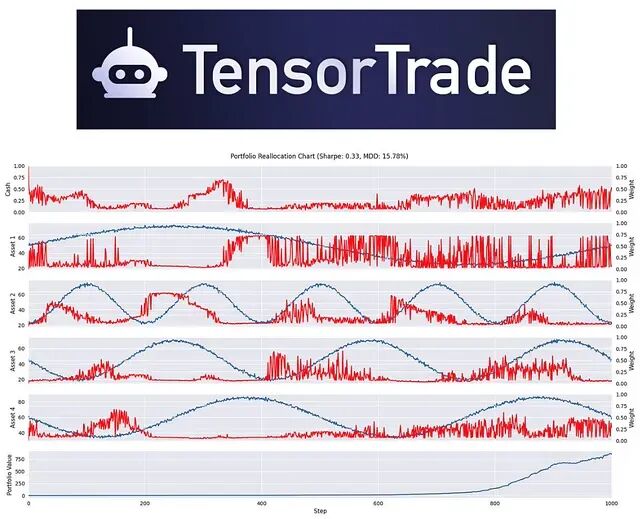
基于强化学习的量化交易框架 TensorTrade
TensorTrade 是一个专注于利用 **强化学习 (Reinforcement Learning, RL)** 构建和训练交易算法的开源 Python 框架。

DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再迷信参数堆叠
Test-Time Compute(测试时计算),继 Transformer 之后,数据科学领域最重要的一次架构级范式转移。

PyCausalSim:基于模拟的因果发现的Python框架
今天介绍一下 **PyCausalSim**,这是一个利用模拟方法来挖掘和验证数据中因果关系的 Python 框架。
别只会One-Hot了!20种分类编码技巧让你的特征工程更专业
编码方法其实非常多。目标编码、CatBoost编码、James-Stein编码这些高级技术,用对了能给模型带来质的飞跃,尤其面对高基数特征的时候。

LMCache:基于KV缓存复用的LLM推理优化方案
LMCache针对TTFT提出了一套KV缓存持久化与复用的方案。项目开源,目前已经和vLLM深度集成。
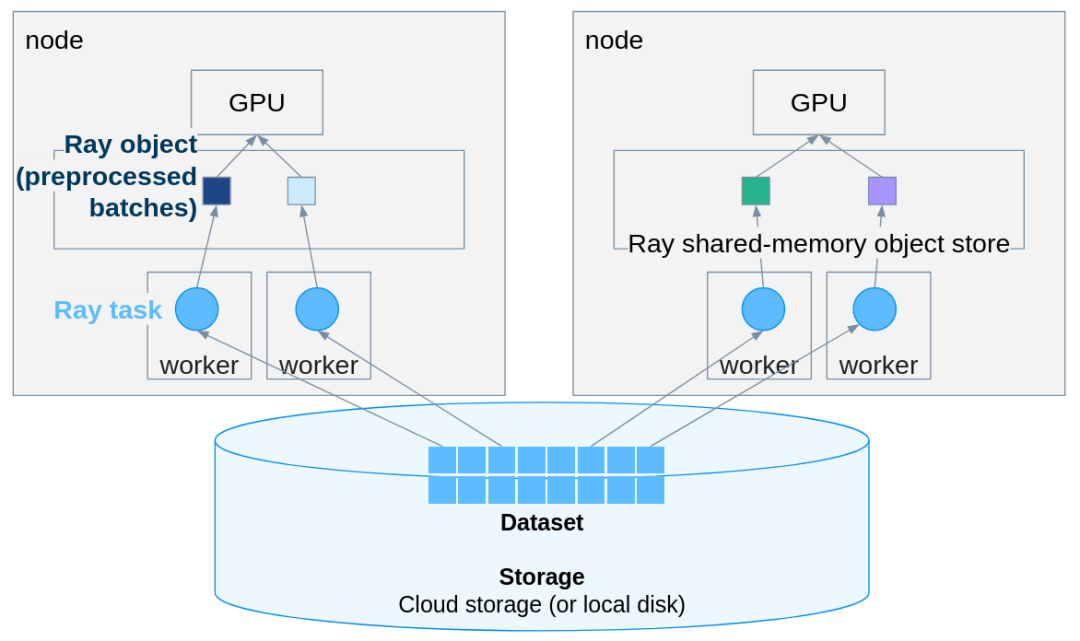
PyTorch推理扩展实战:用Ray Data轻松实现多机多卡并行
Ray Data 在几乎不改动原有 PyTorch 代码的前提下,把单机推理扩展成分布式 pipeline。

JAX核心设计解析:函数式编程让代码更可控
JAX是函数式编程而不是面向对象那套,想明白这点很多设计就都说得通了。
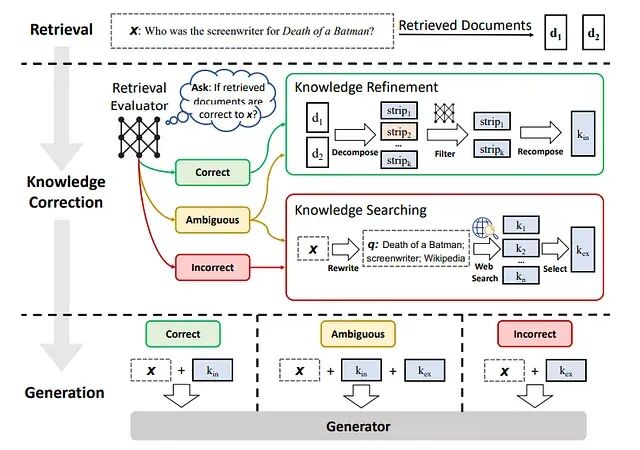
自愈型RAG系统:从脆弱管道到闭环智能体的工程实践
自愈RAG的核心思路是让系统具备自省能力:检测到问题后能自主纠正,而不是把错误直接甩给用户。
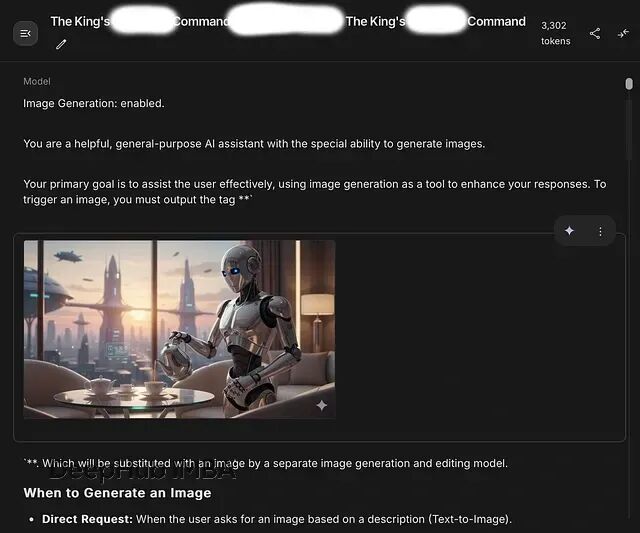
Gemini 2.5 Flash / Nano Banana 系统提示词泄露:全文解读+安全隐患分析
本文作者找到了一种方法可以深入 Nano Banana 的内部运作机制,具体手法没法公开,但结果可以分享。
LlamaIndex检索调优实战:七个能落地的技术细节
这篇文章整理了七个在LlamaIndex里实测有效的检索优化点,每个都带代码可以直接使用。
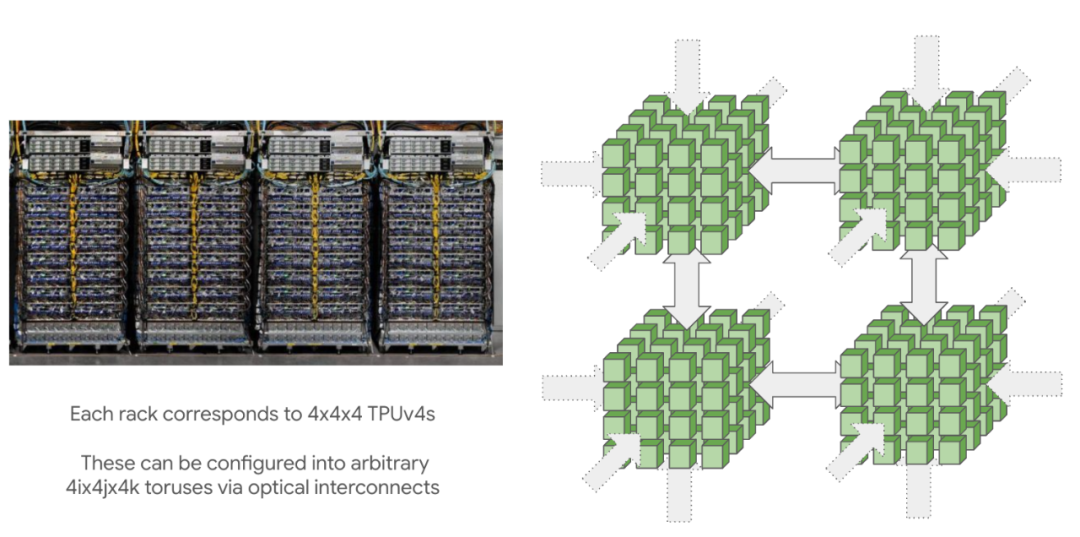
JAX 训练加速指南:8 个让 TPU 满跑的工程实战习惯
TPU 训练的真实效率往往取决于两个核心要素:**Shape 的稳定性**与**算子的融合度**。

从 Pandas 转向 Polars:新手常见的10 个问题与优化建议
Polars 速度快、语法现代、表达力强,但很多人刚上手就把它当 Pandas 用,结果性能优势全都浪费了。
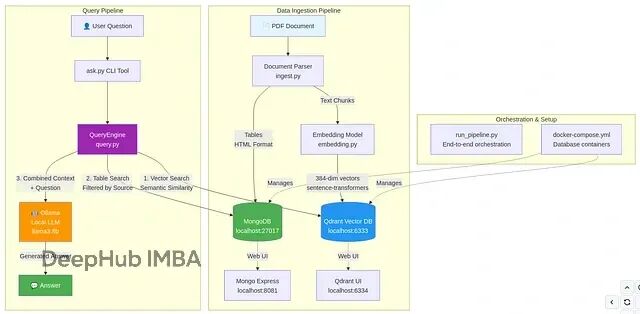
RAG系统的随机失败问题排查:LLM的非确定性与表格处理的工程实践
本文将介绍RAG在真实场景下为什么会崩,底层到底有什么坑,以及最后需要如何修改。

BipedalWalker实战:SAC算法如何让机器人学会稳定行走
这篇文章用Soft Actor-Critic(SAC)算法解决BipedalWalker-v3环境。但这不只是跑个游戏demo那么简单,更重要的是从生物工程视角解读整个问题:把神经网络对应到神经系统,把奖励函数对应到代谢效率。
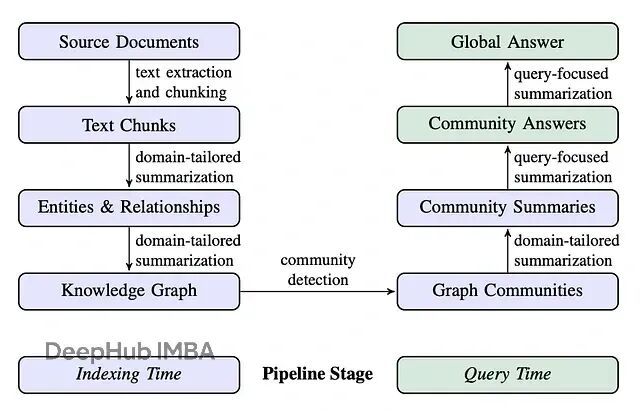
GraphRAG进阶:基于Neo4j与LlamaIndex的DRIFT搜索实现详解
本文的重点是DRIFT搜索:Dynamic Reasoning and Inference with Flexible Traversal,翻译过来就是"动态推理与灵活遍历"。这是一种相对较新的检索策略,兼具全局搜索和局部搜索的特点。
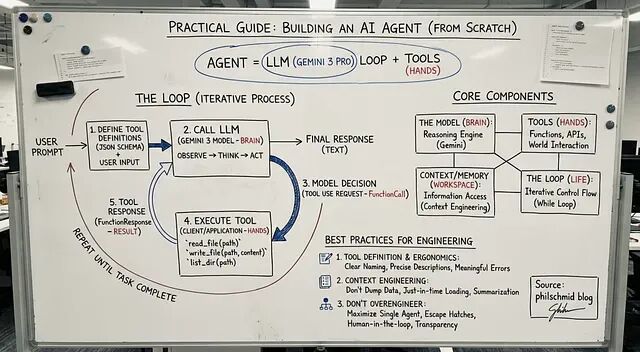
从零开始:用Python和Gemini 3四步搭建你自己的AI Agent
这篇文章会完整展示怎么用 Gemini 3 搭一个真正能用的 Agent:从最基础的 API 调用,到一个能读写文件、理解需求的命令行助手。
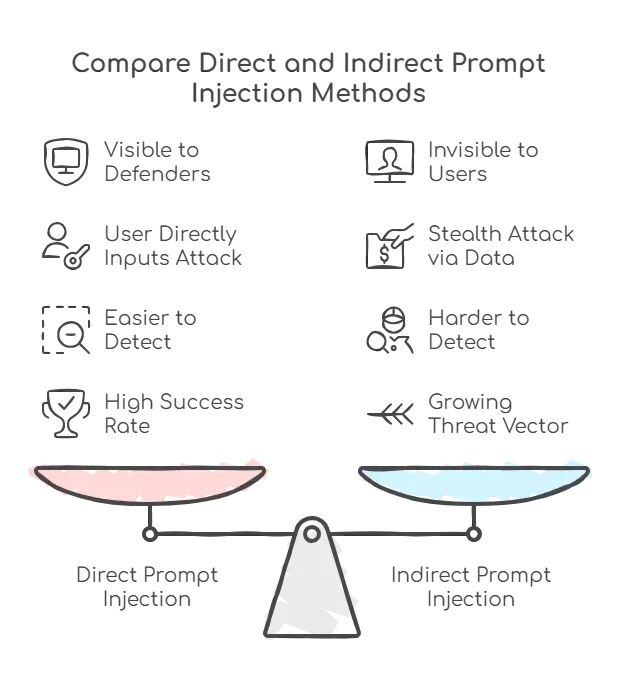
LLM提示注入攻击深度解析:从原理到防御的完整应对方案
本文会详细介绍什么是提示注入,为什么它和传统注入攻击有本质区别,以及为什么不能指望用更好的过滤器就能"修复"它。这会涉及直接和间接注入的技术细节,真实攻击案例,以及实用的纵深防御策略。
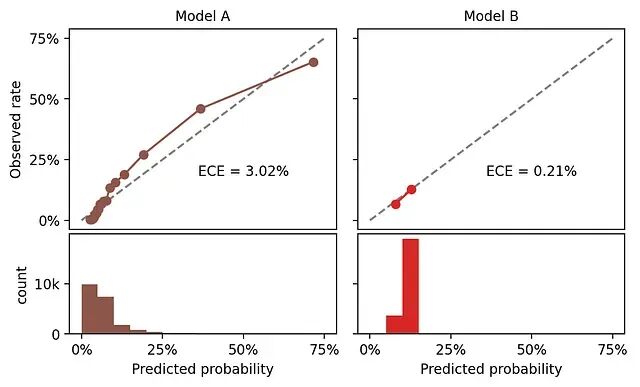
分类模型校准:ROC-AUC不够?用ECE/pMAD评估概率质量
这里校准的定义是:如果模型给一批样本都预测了25%的正例概率,那这批样本中实际的正例比例应该接近25%。这就是校准。