
Deephub
更多文章请关注公众号:Deephub-IMBA
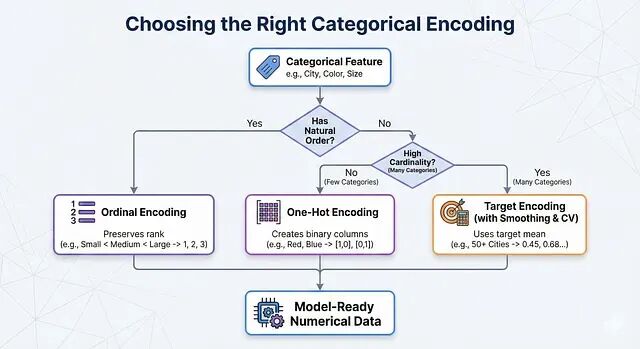
机器学习特征工程:分类变量的数值化处理方法
实际操作中可以这样判断:特征有天然顺序就用 Ordinal Encoding;没有顺序、类别数量也不多就用 One-Hot Encoding;类别太多就上 Target Encoding,记得配合 Smoothing 和交叉验证。
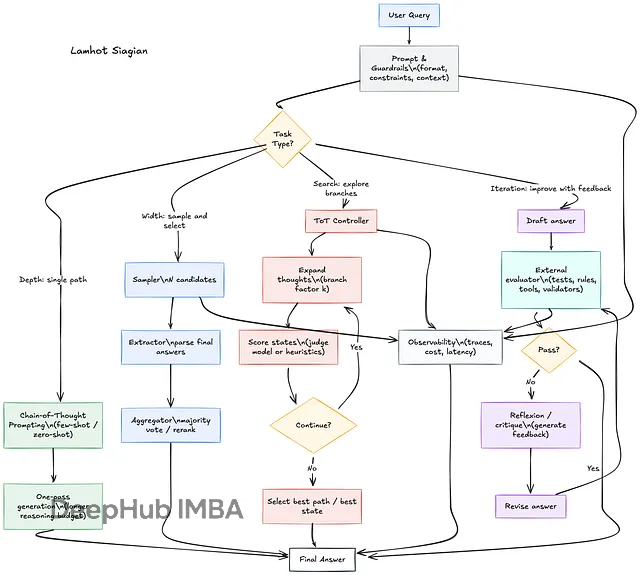
LLM推理时计算技术详解:四种提升大模型推理能力的方法
本文要讲四种主流的推理时计算技术:深度方向的Chain-of-Thought,宽度方向的Self-Consistency,搜索方向的Tree-of-Thoughts,以及迭代方向的Reflexion/Self-Refine。
分类数据 EDA 实战:如何发现隐藏的层次结构
这篇文章讲的是如何在 EDA 阶段把这些隐藏结构找出来,用实际的步骤、真实的案例,外加可以直接复用的 Python 代码。
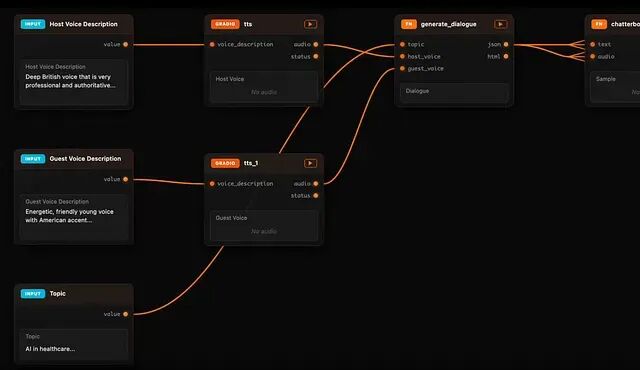
Daggr:介于 Gradio 和 ComfyUI 之间的 AI 工作流可视化方案
Daggr 是一个代码优先的 Python 库,可将 AI 工作流转换为可视化图,支持对 Gradio 管道进行检查、重跑和调试。
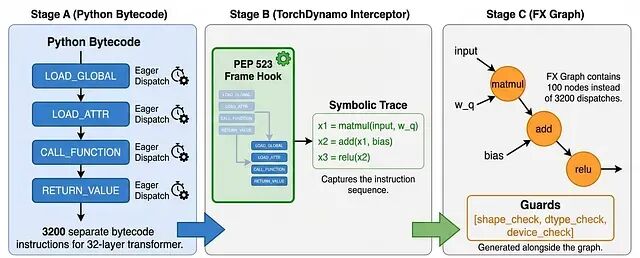
torch.compile 加速原理:kernel 融合与缓冲区复用
torch.compile 的价值在于:它把原本需要手写 CUDA 或 Triton 才能实现的优化,封装成了一行代码的事情。
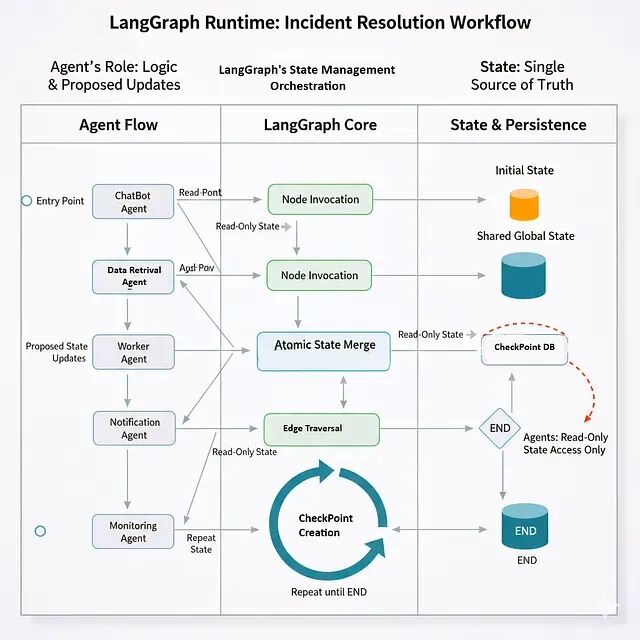
LangGraph 入门:用图结构构建你的第一个多智能体工作流
LangGraph 里每个工作流都是一个 StateGraph——本质上是有向图。节点就是智能体,或者说处理状态的函数;边是智能体之间的转换;状态则是在整个图中流动的共享数据结构。

让 AI 智能体学会自我进化:Agent Lightning 实战入门
本文将介绍 Agent Lightning 的核心架构和使用方法,并通过一个开源的"自修复 SQL 智能体"项目演示完整的训练流程。
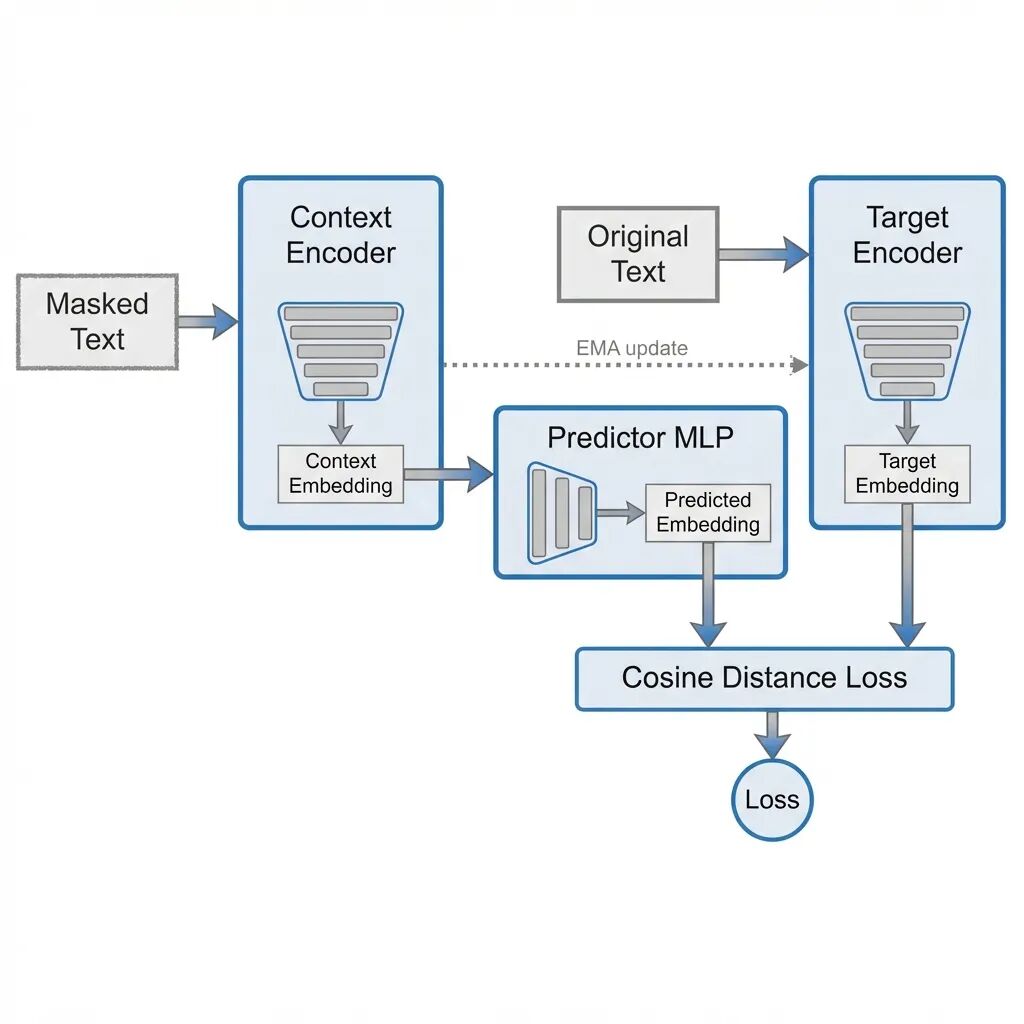
用 PyTorch 实现 LLM-JEPA:不预测 token,预测嵌入
这篇文章从头实现 LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures。
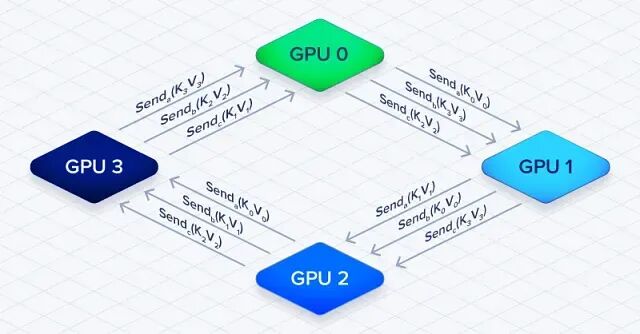
大模型如何训练百万 Token 上下文:上下文并行与 Ring Attention
上下文并行本质上是拿通信开销换内存空间,把输入序列切到多张 GPU 上,突破训练时的内存限制
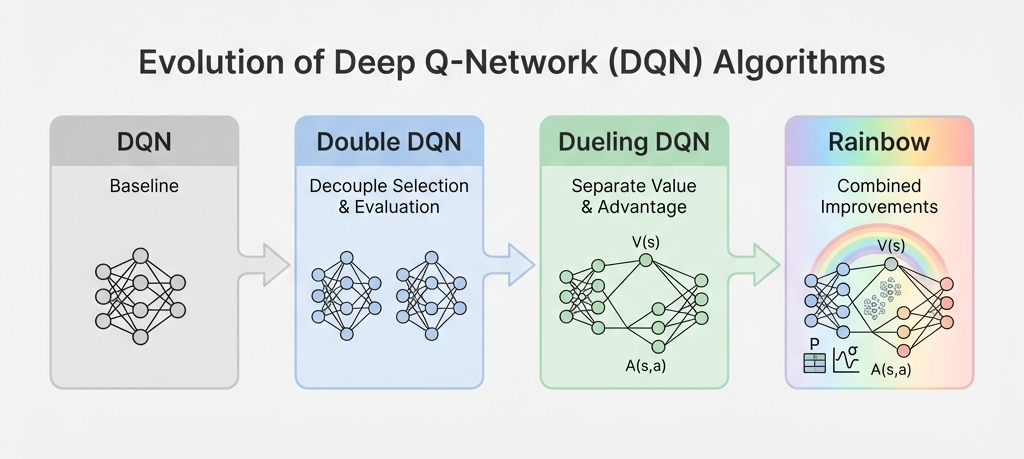
让 Q 值估计更准确:从 DQN 到 Double DQN 的改进方案
这篇文章要内容包括:DQN 为什么会过估计、Double DQN 怎么把动作选择和评估拆开、Dueling DQN 怎么分离状态值和动作优势、优先经验回放如何让采样更聪明,
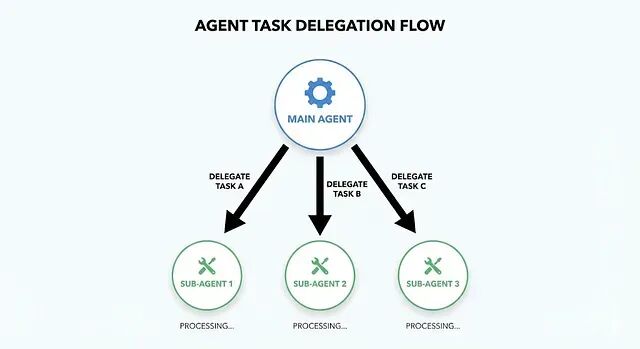
Claude Code子代理实战:10个即用模板分享
简单的说子代理就是给AI指定一个专门的角色。
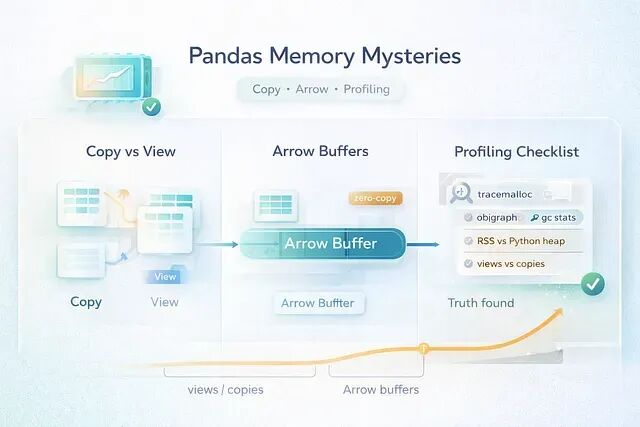
pandas 3.0 内存调试指南:学会区分真假内存泄漏
在pandas 3.0 之后这类情况更多了,因为Copy-on-Write 改变了数据共享的方式,Arrow 支持的 dtype 让内存行为变得更难预测。
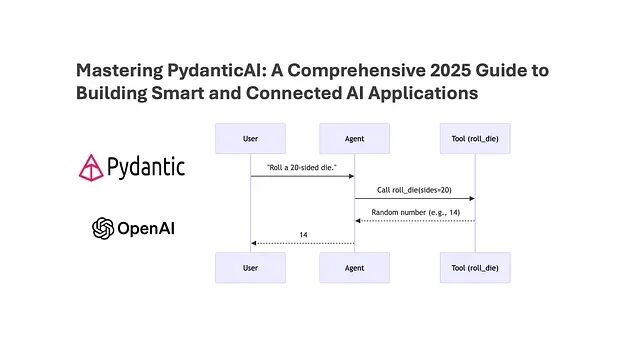
用 PydanticAI 让 LLM 输出变成可信赖的 Python 对象
本文会介绍 PydanticAI 的核心概念,解释为什么类型化响应对 agent 系统如此重要并给出与 CrewAI 集成的实际代码示例。
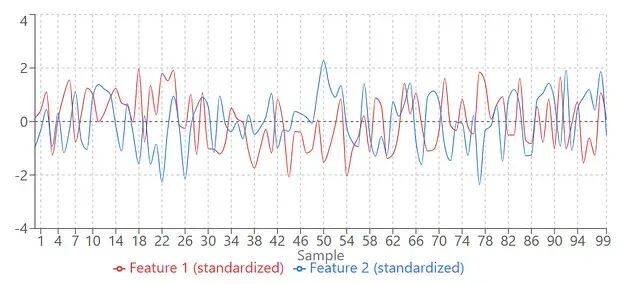
为什么标准化要用均值0和方差1?
为什么标准化要把均值设为0、方差设为1?
知识图谱的可验证性:断言图谱的设计原理
本文会介绍自动化知识图谱生成的核心难题:生成式模型为什么搞不定结构化提取,判别式方案能提供什么样的替代选择,生产级知识图谱的质量标准又是什么。
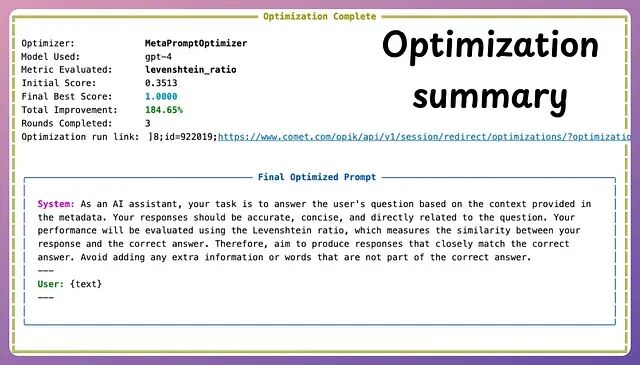
OPIK:一个开源的自动提示词优化框架
本文介绍如何用OPIK的MetaPromptOptimizer实现自动提示词优化,通过几轮迭代将大模型在复杂推理任务上的准确率从34%提升至97%。详解环境搭建、代码实现及优缺点,展示如何让LLM自我改进提示词,大幅提升效率与性能,推动提示工程迈向自动化。
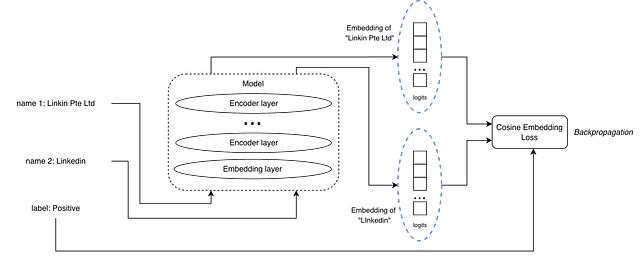
RAG 检索模型如何学习:三种损失函数的机制解析
本文将介绍我实验过的三种方法:Pairwise cosine embedding loss(成对余弦嵌入损失)、Triplet margin loss(三元组边距损失)、InfoNCE loss。
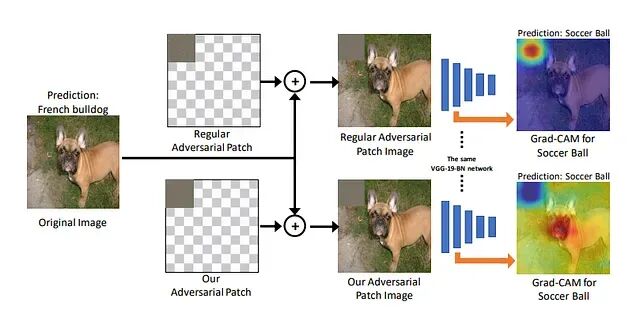
对抗样本:20行Python代码让95%准确率的图像分类器彻底失效
本文会用FGSM(快速梯度符号法)演示如何制作对抗样本,并解释神经网络为何如此脆弱。
使用 tsfresh 和 AutoML 进行时间序列特征工程
本文将介绍多步时间序列预测的构建方式、auto-sklearn 如何扩展用于时间序列、tsfresh 的工作原理和使用方法

用提示工程让大模型自己检查自己:CoVe方法有效减少幻觉
Chain-of-Verification(CoVe)的思路是既然模型会在生成时犯错,那就让它生成完之后再检查一遍自己的输出,把能发现的错误纠正掉,然后再给用户看。