RuntimeWarning: divide by zero encountered in log错误解决
最近在学习《机器学习实战》这本书时,朴素贝叶斯那里遇到了这样的问题。然后运行时出现了下面的问题:虽然不影响最终的结果,但是警告看起来让人不舒服。我们排查原因,是存在数字太小的原因,溢出,计算过程中出现-inf,再做其他运算,结果还是-inf。比如我们展示一下结果:结果如下:探索原因当概率很小时,取对
机器学习实验二 K折交叉验证找最佳K值并可视化分析
一、实验目的:(1)K折交叉验证是一种常用的模型评估方法,它可以在有限的数据下充分利用数据集,提高模型精度和泛化能力。K折交叉验证将数据集分成K个互不重叠的子集,每次选取其中一个子集作为测试集,剩余K-1个子集作为训练集,然后计算模型在测试集上的误差,重复该过程K次,最终得到K个误差值的平均数作为模
Py的mglearn库:Python机器学习工具之mglearn库使用指南
mglearn是一个开源的Python库,旨在支持学习和理解机器学习算法。mglearn库包含了一些已经成为机器学习标准工具的数据集和代码,也提供了一些独特的可视化方法,以帮助理解学习模型的工作原理。mglearn是Python中一款非常有用的机器学习库,它提供了一些有用的可视化工具,可用于更好地理
大数据常用算法和分析模型
黏性分析是在留存分析的基础上,对一些用户指标进行深化,除了一些常用的留存指标外,黏性分析能够从更多维度了解产品或者某功能黏住用户的能力情况,更全面地了解用户如何使用产品,新增什么样的功能可以提升用户留存下来的欲望,不同用户群体之间存在什么样的差异,不同用户对新增的功能有何看法。用户分析模型是基础的分
AI人工智能简史
人工智能发展至今,经历了几个起伏。从早期的理论发展,到后来的低谷期,再到近年来的蓬勃发展,人工智能取得了巨大进步。神经网络带来的深度学习浪潮,使机器翻译、图像识别等一个个难题落地生根,AlphaGo的诞生标志着人工智能在博弈游戏领域获胜,GPT-3等语言模型的到来使人工智能在自然语言处理领域大放异彩
Stable Diffusion Web UI的原理与使用
StableDiffusion是基于扩散模型的应用,那就先来讲一讲什么是扩散模型。我们知道在扩散模型出现之前,比较火的是GAN(对抗生成网络),GAN由生成器和判别器组成,两者相互博弈训练,最终产生较理想的输出。但是GAN也有缺点,首先生成器和判别器不断进化的中间N个步骤完全是黑盒,无法调试。其次还
802.1x协议详解,802协议工作原理/认证过程、MAB认证、EAP报文格式
802.1x协议是基于端口的「访问控制和认证协议」,工作在数据链路层,用来限制未授权的用户/设备通过接入端口访问LAN/WLAN。
【深度学习】GPT系列模型:语言理解能力的革新
大力出奇迹的语言模型!
随机变量的分布函数
分布函数 密度函数
RSE和RMSE
是对应的预测值,n是总观测数。RMSE越小,说明预测模型的精度越高。在统计学中,RSE和RMSE分别代表相对标准误差和均方根误差。是样本观测值的平均值。RSE越小,说明样本估计值的精度越高。其中,s是样本观测值与平均值之间的标准偏差,
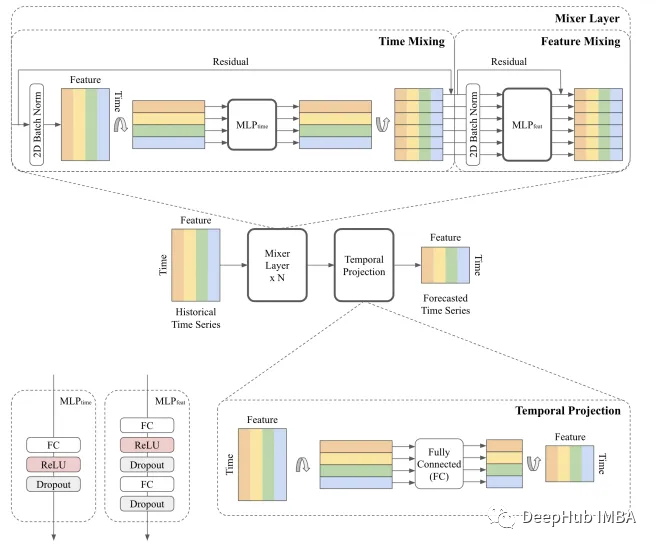
TSMixer:谷歌发布的用于时间序列预测的全新全mlp架构
这是谷歌在9月最近发布的一种新的架构 TSMixer: An all-MLP architecture for time series forecasting
隐函数的求导
有隐函数就有显函数,我们首先要了解显函数的定义:隐函数:例如:对于有些隐函数,我们可以显化:但是有些隐函数,我们并不能显示化这个隐函数,我们就不能显示化对于这个函数,我们发现以下特征:当x趋近于正无穷时,y也趋近于正无穷。当x趋近于负无穷时,y也趋近于负无穷。假设我们把这里的x当作1,然后再对y进行
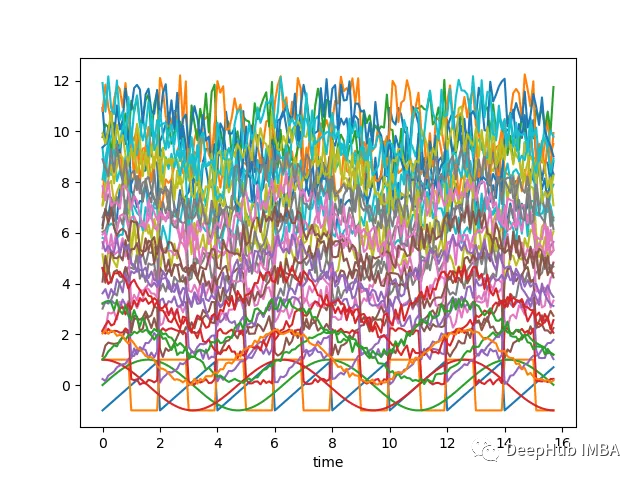
使用轮廓分数提升时间序列聚类的表现
我们将使用轮廓分数和一些距离指标来执行时间序列聚类实验,并且进行可视化
【课堂笔记】运筹学第二章:对偶问题
单位第iii种资源在最优方案中做出贡献的估价做法:通过求导得到每一种资源带来的利润的提升是多少所有问题一定能找到对偶问题,但是其对偶问题不一定有意义.原问题对偶问题收益最大化代价最小化方程的个数,即种类的个数决策变量数价值系数对偶问题右端的项向量,即约束资源的约束价值系数与前面内容有所重复,即BCB
有 AI,无障碍,AIoT 设备为视障人群提供便利
据世界卫生组织统计,全球共有 2.85 亿视障人群,其中 3,900 万人彻底失明。随着全球老龄化程度加剧,这一数字在未来将会不断升高。虽然视障群体不断扩大,但是相应的无障碍设施却相对落后。针对视障人群的辅助设备则存在价格昂贵、操作复杂等问题,难以满足他们的日常需求。为此,广东技术师范大学和武汉科技
Adam原理
深度学习中Adam优化方法的计算公式
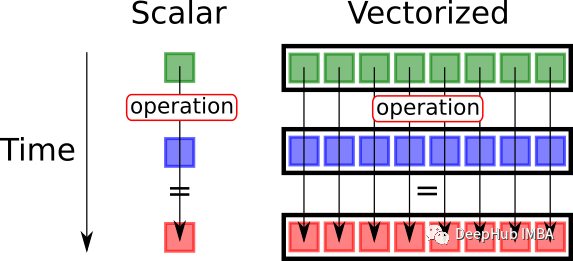
向量化操作简介和Pandas、Numpy示例
在本文中,我们将探讨什么是向量化,以及它如何简化数据分析任务。
深度学习在通信领域中的应用
深度学习在通信领域中的应用深度学习作为人工智能领域的一个热门技术,一直在探索新的应用领域。近年来,深度学习在通信领域中的应用也逐渐受到关注。通信领域需要面对各种挑战和问题,例如信道估计、信号检测、通信系统优化等等。这些问题的解决,可以大大提升通信系统的性能和效率。本文将重点介绍深度学习在通信领域中的
【人工智能】GPT-4 的使用成本,竟然是GPT-3.5的50倍之多 —— 大语言模型(LLM)开发者必须知道的数字
这篇文章的作者来自开源人工智能框架Ray的开发公司Anyscale。主要贡献者是Google前首席工程师Waleed Kadous。他也曾担任Uber CTO办公室工程战略负责人。其中一位华人合作者是Google前员工Huaiwei Sun。他来自江苏昆山,本科毕业于上海交通大学工业设计专业。期间,
Origin曲线拟合教程
利用origin进行线性拟合的一些分析教程



