连续型随机变量的分布(均匀分布、指数分布、正态分布)
连续型随机变量的分布(均匀分布、指数分布、正态分布)
机器学习 | sklearn库
本篇文章主要讲解对所给数据集进行机器学习之前的样本划分、数据预处理、数据降维等知识点与可视化和python实现
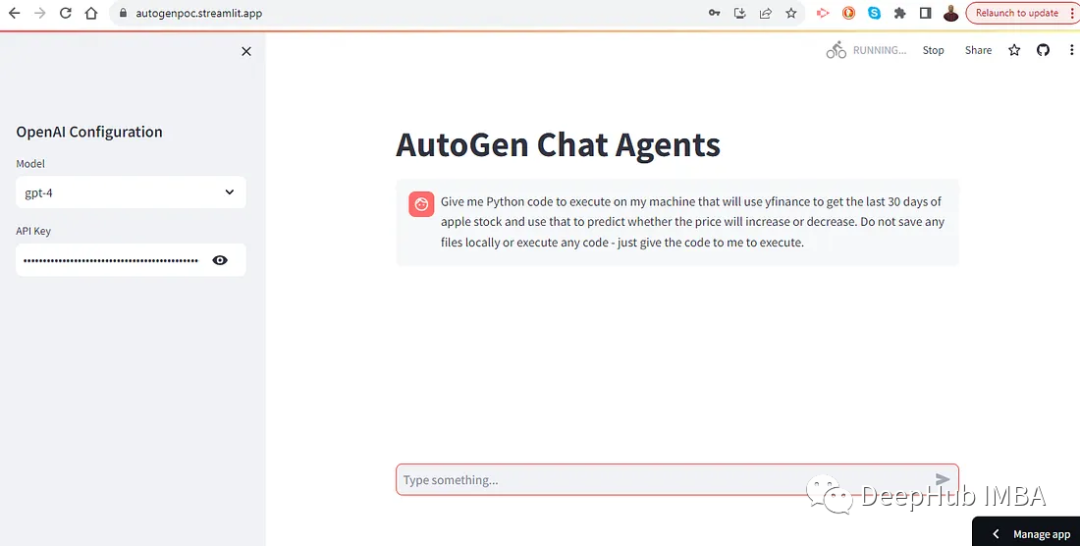
使用Streamlit创建AutoGen用户界面
我们来对AutoGen进行改造,使用Streamlit创建一个web界面,这样可以让我们更好的与其交互。
机器学习:10种方法解决模型过拟合
L1 正则化,通常也被称为Lasso 正则化(Least Absolute Shrinkage and Selection Operator),是通过在损失函数中添加 L1 范数(参数绝对值之和)惩罚项,来约束模型的参数。L1 正则化的目标是使模型参数趋向于稀疏,即让一些参数为零,从而实现特征选择和
相关滤波(一)KCF
相关滤波KCF
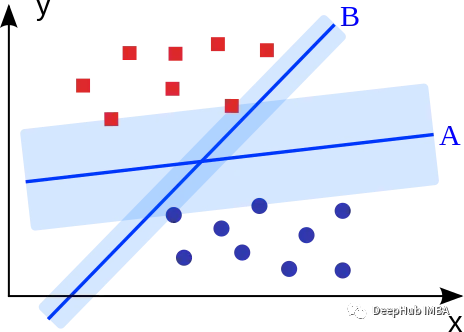
使用Python从零实现多分类SVM
本文将首先简要概述支持向量机及其训练和推理方程,然后将其转换为代码以开发支持向量机模型。之后然后将其扩展成多分类的场景,并通过使用Sci-kit Learn测试我们的模型来结束。
倾向得分匹配(PSM)的原理以及应用
该文章主要介绍倾向得分匹配(PSM, Propensity Score Matching)方法的原理以及实现。这是一种理论稍微复杂、但实现较为容易的分析方法,适合非算法同学的使用。可用于(基于观察数据的)AB实验、增量模型搭建等领域。文章主要分为四部分:前置知识(因果推断)介绍、倾向得分计算与匹配与
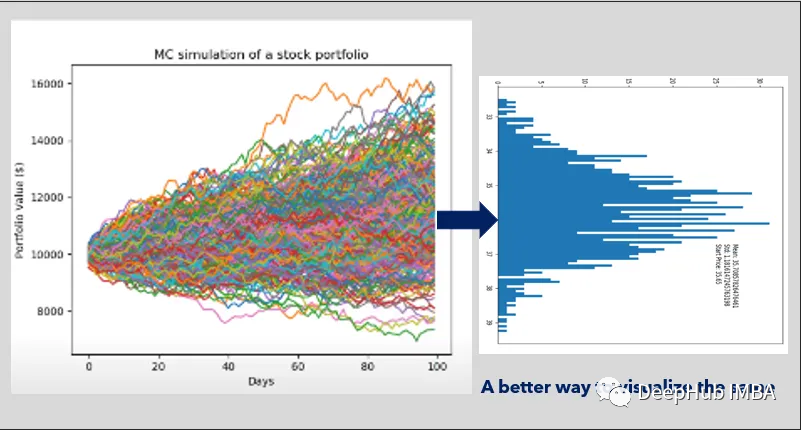
使用蒙特卡罗模拟的投资组合优化
在金融市场中,优化投资组合对于实现风险与回报之间的预期平衡至关重要。蒙特卡罗模拟提供了一个强大的工具来评估不同的资产配置策略及其在不确定市场条件下的潜在结果。
matlab系统辨识工具箱及其反向验证
时,通过对输入输出数据采集,通过数学迭代找到控制对象的近似模型。首先制作输入数据,在simulink中的输入数据需要是实数、整型、浮点数,且第一列为时间数据,因此结合原数据采样时间为0.08s,可得制作数据时间间隔为0.08s,数据量为1000,因此时间为0-0.08*1000s。在上述ARX模型中
【AI】了解人工智能、机器学习、神经网络、深度学习
【AI】了解人工智能、机器学习、神经网络、深度学习。
【AI机器学习入门与实战】训练模型、优化模型、部署模型
弄清楚在机器学习中训练模型、评估优化模型、部署模型上线到底该怎么做?
基于BILSTM时间序列预测 python程序
基于BILSTM时间序列预测 python程序
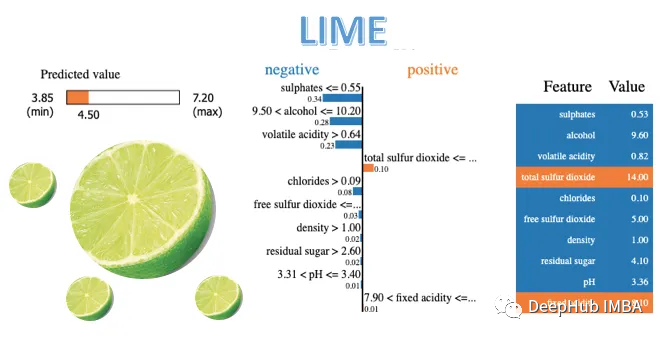
使用LIME解释各种机器学习模型代码示例
在本文中,我们将介绍LIME,并使用它来解释各种常见的模型。
支持向量机SVM(包括线性核、多项式核、高斯核)python手写实现+代码框架说明
支持向量机SVM(包括线性核、多项式核、高斯核)python手写实现+代码框架说明
Visual Studio 2022 程序员必须知道高效调试手段与技巧(上)
一名优秀的程序员是一名出色的侦探,每一次调试都是尝试破案的过程。所以当我们程序出现问题一点要调试这样才能搞懂问题出在哪里
Pytorch版Mask-RCNN图像分割实战(自定义数据集)
Mask R-CNN是一种广泛应用于目标检测和图像分割任务的深度学习模型,它是由Faster R-CNN(一种快速目标检测模型)和Mask R-CNN(一种实例分割模型)组成的。Mask R-CNN将Faster R-CNN中的RPN和RoI Pooling层替换成了RPN和RoI Align层,以

数据抽样技术全面概述
抽样是研究和数据收集中不可或缺的方法,能够从更大数据中获得有意义的见解并做出明智的决定的子集。不同的研究领域采用了不同的抽样技术,每种技术都有其独特的优点和局限性。
RANSAC算法(仅供学习使用)
RANSAC(Random Sample Consensus)算法是一种基于随机采样的迭代算法,用于估计一个数学模型参数。它最初由Fischler和Bolles于1981年提出,主要用于计算机视觉和计算机图形学中的模型拟合和参数估计问题。RANSAC算法的基本思想是通过随机采样一小部分数据来估计模型
【人工智能与机器学习】决策树ID3及其python实现
决策树ID3是一种经典的机器学习算法,用于解决分类问题。它通过在特征空间中构建树形结构来进行决策,并以信息增益作为划分标准。ID3算法的关键在于选择最佳的属性进行划分,以最大化信息增益。通过Python实现ID3算法,我们可以构建出一棵高效而准确的决策树模型,用于分类预测和决策分析。参考。
【Python气象处理绘图第七弹–泰勒图绘制】
在进行模式评估的过程中,常常需要评估模式的模拟性能,这通常由空间相关系数(CC),相对标准差(SD)及其中心化的均方根误差(RMSE)体现,这三者又常常可以由泰勒图具体体现。RMSE越接近0,CC和SD越接近1,模式模拟能力越好泰勒图23.泰勒图以上就是对于泰勒图的绘制。处理核心:数据预处理成一维数



