单位冲激函数与单位阶跃函数
本节主要介绍另外两个基本信号,在连续时间和离散时间情况下的单位阶跃和单位冲激函数,在信号与系统的分析中很重要。
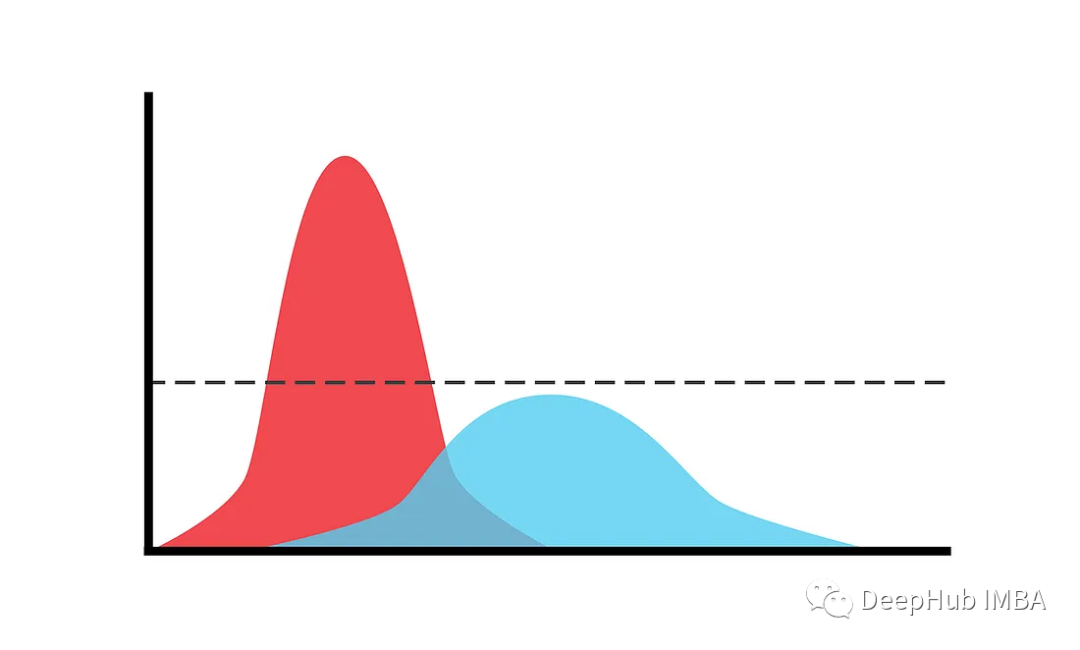
高斯混合模型:GMM和期望最大化算法的理论和代码实现
高斯混合模型(gmm)是将数据表示为高斯(正态)分布的混合的统计模型。这些模型可用于识别数据集中的组,并捕获数据分布的复杂、多模态结构。
【古诗生成AI实战】之五——加载模型进行古诗生成
这部分是项目中非常激动人心的一环,因为我们将看到我们的模型如何利用先前学习的知识来创造出新的古诗文本。这是一个重要的里程碑,因为训练好的模型是我们进行文本生成的基础。* 生成文本:从初始文本(例如“天”)开始,逐字生成新的文本,直到达到指定长度(如32个字符)。在这部分内容中,我们将探讨如何使用预训
机器学习可解释性一(LIME)
对于机器学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常,我们可以认为机器学习的可解释性刻画了“人类对模型决策或预测结果的理解程度”,即用户可以更容易地理解解释性较高的模型做出的决策和预测。从哲学的角度来说,为了理解何为机器学习的可解释性,我
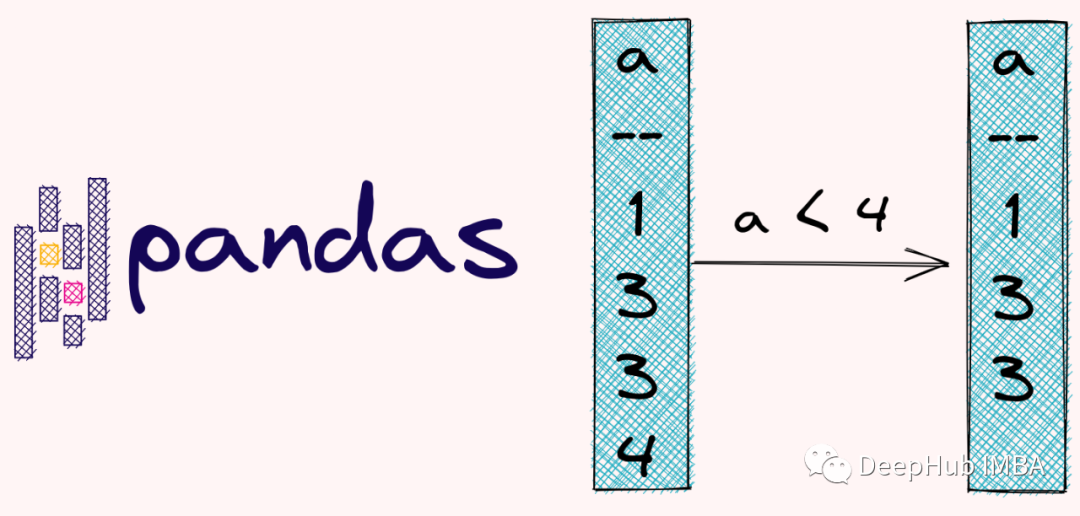
Pandas中选择和过滤数据的终极指南
本文将介绍使用pandas进行数据选择和过滤的基本技术和函数。无论是需要提取特定的行或列,还是需要应用条件过滤,pandas都可以满足需求。
[log_softmax]——深度学习中的一种激活函数
具体来说,在模型训练过程中,[log_softmax]可以被当作是损失函数的一部分,用于计算预测值与真实值之间的距离。在深度学习中,我们需要将神经网络的输出转化为预测结果,而由于输出值并非总是代表着概率,因此我们需要使用激活函数将其转化为概率值。总结来说,[log_softmax]是深度学习中非常重
人工智能 - 图像分类:发展历史、技术全解与实战
在本文中,我们深入探讨了图像分类技术的发展历程、核心技术、实际代码实现以及通过MNIST和CIFAR-10数据集的案例实战。文章不仅提供了技术细节和实际操作的指南,还展望了图像分类技术未来的发展趋势和挑战。
深入探讨机器学习中的过拟合现象及其解决方法
真正喜欢的人和事都值得我们去坚持。

使用Accelerate库在多GPU上进行LLM推理
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
机器学习卷积神经网络YOLOv5工地安全检测佩戴安全帽检测和识别含佩戴安全帽
安全帽是作业场所作业时头部防护所用的头部防护用品,它对使用者的头部在受坠落物或小型飞溅物体等其他因素引起的伤害起到防护作用。近年来,因不佩戴安全帽、不规范佩戴安全帽等原因导致的安全生产事故屡禁不止,事故发生背后的影响是巨大的,不仅为家人带来巨大的伤痛,也为企业的利益带来巨大的损失。而如何使员工规范佩
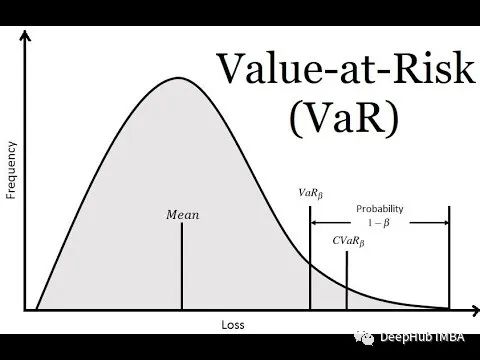
三种常用的风险价值(VaR)计算方法总结
风险价值(VaR)是金融领域广泛使用的风险度量,它量化了在特定时间范围内和给定置信度水平下投资或投资组合的潜在损失。
安装下载Anaconda + Pycharm + Pytorch
1.直接在浏览器中打开Anaconda官网。 2.进入官网页面后点击下载。 3.找到并点击安装包进行下载。4.下一步。 5.同意。6.选择Just me,点下一步。 7.选择安装路径,最好不要装在C盘。我的是装在了D盘。点下一步。 8.把下图的这两个选项都勾选了,第一个是自动添加环境变量到电脑中。之
MNIST数据集ubyte格式数据解析
MNIST数据集格式解析
使用skforecast进行时间序列预测
在本文中,将介绍skforecast并演示了如何使用它在时间序列数据上生成预测。skforecast库的一个有价值的特性是它能够使用没有日期时间索引的数据进行训练和预测。
多模态技术综述
多模态机器学习是对计算机算法的研究,通过使用多模态数据集来学习和提高性能。多模式深度学习是一个机器学习子领域,旨在训练人工智能模型来处理和找到不同类型的数据(模式)之间的关系,通常是图像、视频、音频和文本。通过组合不同的模式,深度学习模型可以更普遍地理解其环境,因为一些线索只存在于某些模式中。想象一
详细介绍BFGS算法
在minimize函数中,我们指定了初始点theta0、使用BFGS算法求解(method='BFGS')、使用线性回归模型的梯度(jac=linear_regression_grad)以及一些其他的参数选项(options={'disp': True})。在minimize函数中,我们指定了初始点
基于SVM的车牌识别算法
使用Python实现基于SVM的车牌识别算法,调用Opencv库实现
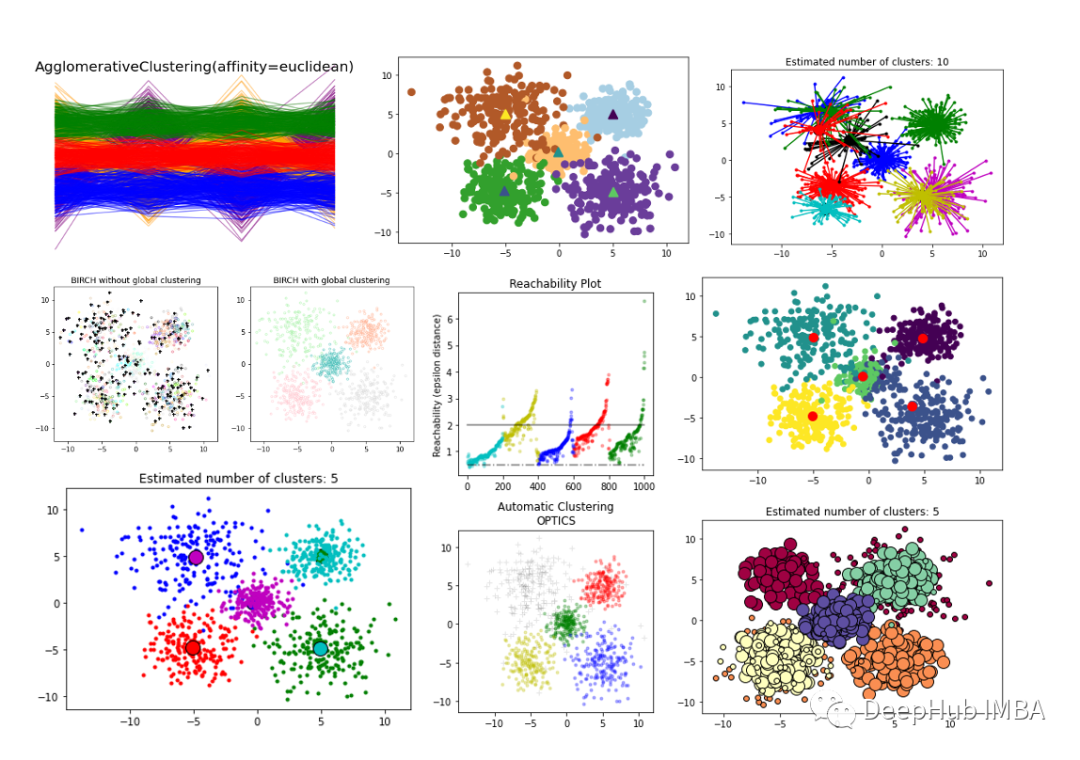
6个常用的聚类评价指标
评估聚类结果的有效性,即聚类评估或验证,对于聚类应用程序的成功至关重要。
Azure Machine Learning - Azure AI 搜索中的矢量搜索
矢量搜索是一种信息检索方法,它使用内容的数字表示形式来执行搜索方案。 由于内容是数字而不是纯文本,因此搜索引擎会匹配与查询最相似的矢量,而不需要匹配确切的字词。本文简要介绍了 Azure AI 搜索中的矢量支持。 其中还解释了与其他 Azure 服务的集成,以及与矢量搜索开发相关的术语和概念
人工智能中的文本分类:技术突破与实战指导
在本文中,我们全面探讨了文本分类技术的发展历程、基本原理、关键技术、深度学习的应用,以及从RNN到Transformer的技术演进。文章详细介绍了各种模型的原理和实战应用,旨在提供对文本分类技术深入理解的全面视角。



