ID3 决策树的原理、构造及可视化(附完整源代码)
【2022.10】ID3 决策树的原理、构造及可视化(附完整源代码)
Azure Machine Learning - 使用 Azure OpenAI 服务生成图像
在浏览器/Python中使用 Azure OpenAI 生成图像,图像生成 API 根据文本提示创建图像。
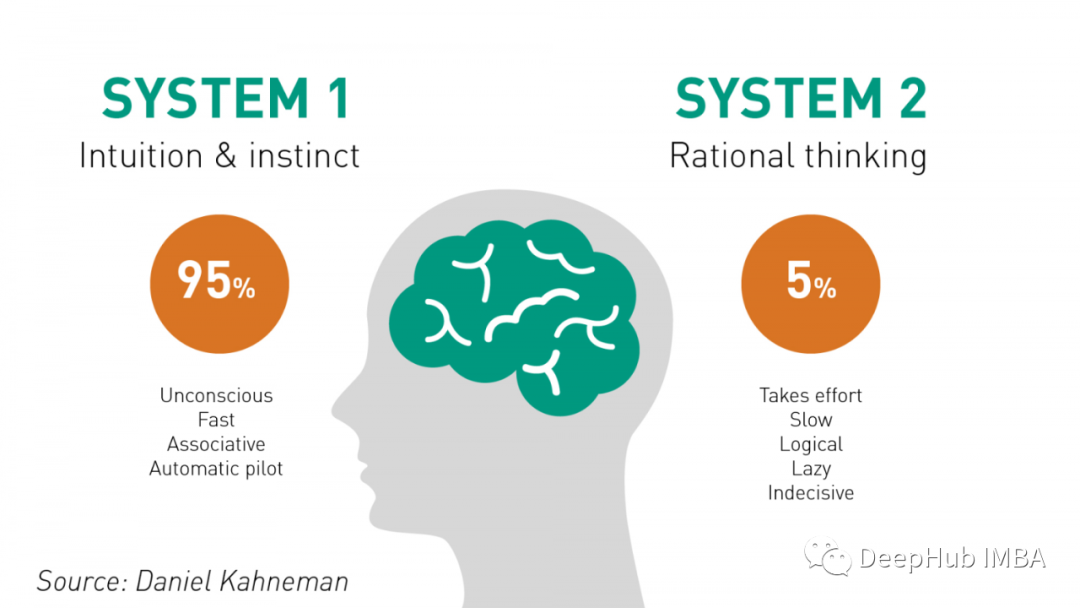
System 2 Attention:可以提高不同LLM问题的推理能力
S2A是LLM推理方法发展的一个重要里程碑。该方法与人类推理非常相似,避免了干扰。我们应该期待S2A在最近几个月成为推理研究的重要基线。
机器学习:ROC曲线
本篇博客从概念、原理、应用和与AUC值相关的知识点四个方面介绍了ROC曲线的基本知识,并给出了Python实现的示例。尽管ROC曲线不能完全衡量分类器的性能,但是它仍然是一个非常重要的评估指标,可以帮助我们选择更好的分类器模型,提高机器学习的效果和准确率。
【机器学习】Spark ML 对数据特征进行 One-Hot 编码
在机器学习中,一般需要对非数值型的特征进行编码处理,将其转化为数值型的特征。其中,One-Hot 编码是一种常见的特征编码方式。One-Hot 编码是将一个离散特征的每个取值映射为一个唯一的整数编号,并将该编号表示成一个二进制向量的形式。具体来说,对于一个有kkk个不同取值的离散特征,其 One-H
【文本生成评价指标】 ROUGE原理及代码示例py
代码演示了如何使用 Python 中的 rouge 库来计算生成文本和参考文本之间的 ROUGE 指标,以评估文本生成算法的质量。
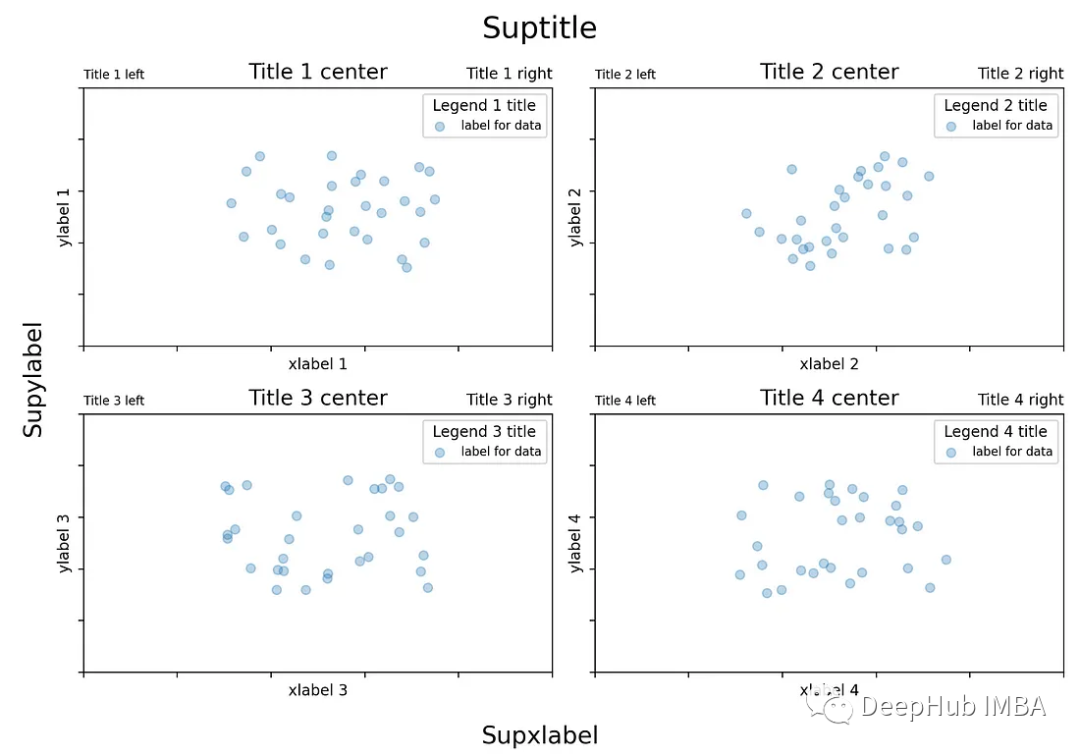
Matplotlib中的titles(标题)、labels(标签)和legends(图例)
本文讨论Python的Matplotlib绘图库中可用的不同标记选项。
2023年5个自动化EDA库推荐
YData Profiling执行起来很简单,UI很直观,给了我所有的信息,这是开始EDA过程的一个很好的切入点。D-Tale不仅是EDA过程的一个很好的起点,而且可以用来轻松地预处理数据,最主要是不需要编写任何代码,这使得它非常节省时间,并且任何人都可以轻松访问。SweetViz的UI有点过时,但
语义分割之RandLANet深度解读
语义分割任务是计算机视觉里的一个比较基础的任务,其相比于物体检测任务主要有以下几个优点:输出的结果是稠密的,是针对于所有像素点的K分类问题,物体检测任务只输出前景类物体的信息忽略了背景点的信息在自动驾驶任务中可以实现可行驶区域的识别,大部分区域都是以背景的形式存在,而这些背景同样是非行驶区域可以输出
梯度消失与梯度爆炸产生、原理和解决方案
本文章总结了梯度消失与梯度爆炸产生、原理和解决方案。
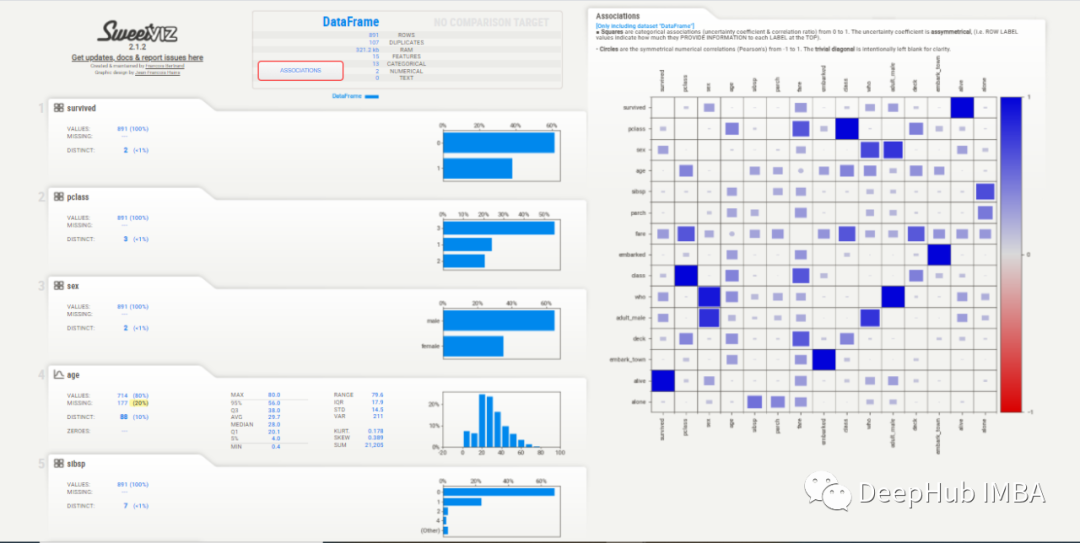
2023年5个自动化EDA库推荐
EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。
中科大2023春季【高级人工智能】试题回顾
记得不是很清楚了,但是可以大概回忆一下(0-o)题型还是填空+判断+简答+计算考了信息熵公式,搜索问题的五要素,hingeloss公式,SVM优化目标函数,约束求解问题的(X,D,C)的含义。无限集合有k个球,球的分布是什么样子的时候熵最大。迭代深度优先搜搜的时空复杂度。决策树通过什么防止过拟合。(
ADMM算法系列1:线性等式或不等式约束下可分离凸优化问题的ADMM扩展
推导过程也很简单就是在原始ADMM算法的基础上去掉常数项演变而来,它的收敛性证明便遵循了上面所阐述的收敛性路线图,即先找到它的变分不等式然后凑出收敛性证明的预测校正框架即可。在此基础上,可以设计一系列具体的基于ADMM的算法,这些算法在预测校正结构中具有可证明的收敛性。这里就和前文对应了,主要是想说
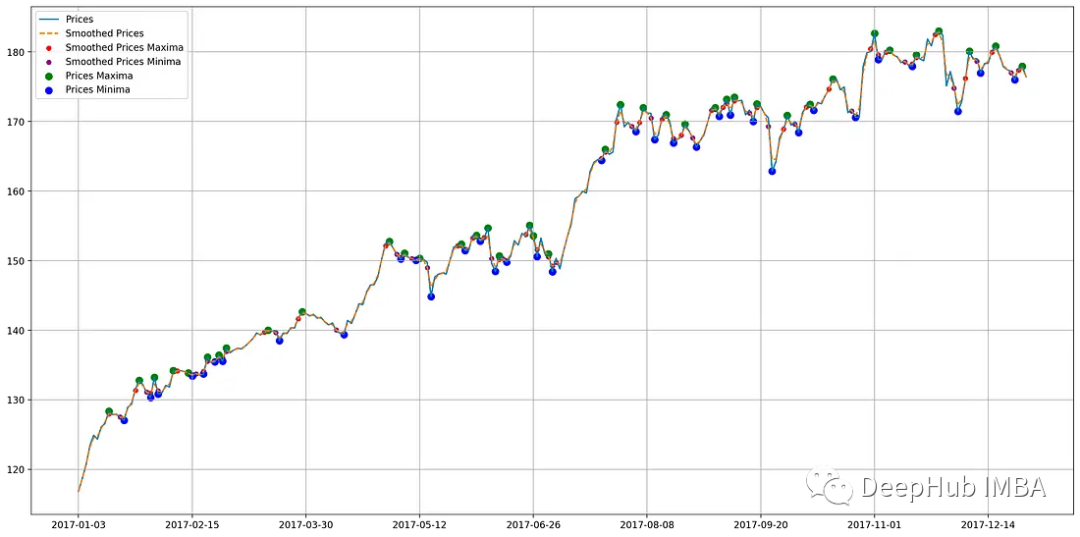
使用Python代码识别股票价格图表模式
在股票市场交易的动态环境中,技术和金融的融合催生了分析市场趋势和预测未来价格走势的先进方法。本文将使用Python进行股票模式识别。
机器学习|优化算法 | 评估方法|分类模型性能评价指标 | 正则化
机器学习|正则化|评估方法|分类模型性能评价指标|吴恩达学习笔记(哔哩哔哩视频and课堂PPT笔记梳理)
人工智能 - 人脸识别:发展历史、技术全解与实战
本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。
【论文学习】机器学习模型安全与隐私研究综述
机器学习在以及面临的安全和隐私威胁,呈现出多样性、隐蔽性和动态演化的特点。应用领域:计算机视觉、自然语言处理、语音识别等应用场景:自动驾驶、人脸识别、智慧医疗等。

4个解决特定的任务的Pandas高效代码
在本文中,我将分享4个在一行代码中完成的Pandas操作。这些操作可以有效地解决特定的任务,并以一种好的方式给出结果。
【PyTorch】第六节:乳腺癌的预测(二分类问题)
上一个实验我们讲解了线性问题的求解步骤,本实验我们以乳腺癌的预测为实例,详细的阐述如何利用 PyTorch 求解一个非线性问题。
Azure 机器学习 - 使用 Visual Studio Code训练图像分类 TensorFlow 模型
了解如何使用 TensorFlow 和 Azure 机器学习 Visual Studio Code 扩展训练图像分类模型来识别手写数字。



