处理不平衡数据的方法小结(算法层面)
不平衡数据处理的阶段性小总结
大数据机器学习-梯度下降:从技术到实战的全面指南
梯度下降(Gradient Descent)是一种在机器学习和深度学习中广泛应用的优化算法。该算法的核心思想非常直观:找到一个函数的局部最小值(或最大值)通过不断地沿着该函数的梯度(gradient)方向更新参数。简单地说,梯度下降是一个用于找到函数最小值的迭代算法。在机器学习中,这个“函数”通常是
python机器学习数据建模与分析——数据预测与预测建模
机器学习的预测建模在多个领域都具有重要的应用价值,包括个性化推荐、商品搜索、自动驾驶、人脸识别等。本篇文章将带领大家了解什么是预测建模
pinokio让你在本地轻松跑多种AI模型的神奇浏览器
就像一个网络浏览器,Pinokio本身不会做任何事情,但随着人们围绕它构建和分享应用、工作流和API,它将变得越来越有用。订阅我们的中文简报,深入解析最新的技术突破、实际应用案例和未来的趋势。Pinokio是一个浏览器,可以让您自动且轻松地安装、运行和自动化任何AI应用和模型。再也不需要打开终端。但
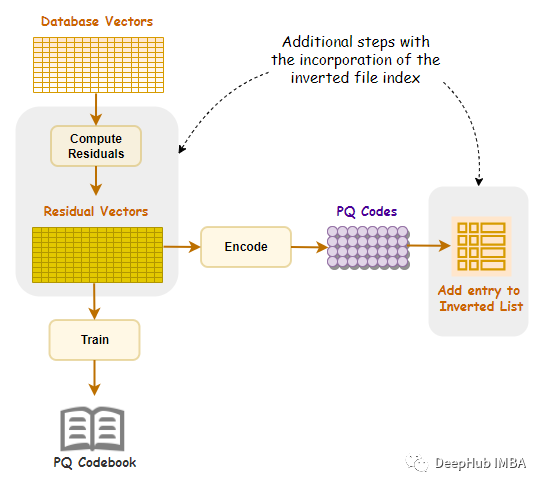
高维向量压缩方法IVFPQ :通过创建索引加速矢量搜索
IVFPQ 是一种用于数据检索的索引方法,它结合了倒排索引(Inverted File)和乘积量化(Product Quantization)的技术。
在Linux系统下部署Llama2(MetaAI)大模型教程
在Linux系统下部署Llama2(MetaAI)大模型教程。1、本文选择部署的模型是Llama2-chat-13B-Chinese-50W。2、由于大部分笔记本电脑无法满足大模型Llama2的部署条件,因此可以选用autodl平台(算力云)作为部署平台。
机器学习实验 - 朴素贝叶斯分类器
西南交通大学 机器学习实验2 朴素贝叶斯分类器(1)了解朴素贝叶斯与半朴素贝叶斯的区别与联系,掌握高斯分布、多项式分布和伯努利分布的朴素贝叶斯计算方法。(2)编程实现朴素贝叶斯分类器,基于多分类数据集,使用朴素贝叶斯分类器实现多分类预测,通过精确率、召回率和F1值度量模型性能。
NeurIPS 2023|AI Agents先行者CAMEL:第一个基于大模型的多智能体框架
AI Agents是当下大模型领域备受关注的话题,用户可以引入多个扮演不同角色的LLM Agents参与到实际的任务中,Agents之间会进行竞争和协作等多种形式的动态交互,进而产生惊人的群体智能效果。本文介绍了来自KAUST研究团队的大模型心智交互CAMEL框架(“骆驼”),CAMEL框架是最早基
【Python】人工智能-机器学习——不调库手撕贝叶斯分类问题
怎么用python手撕一个贝叶斯分类?要求不调用其他核心库如tf,sk等,只用numpy、pandas库?这篇文章会告诉你答案!!

2023年12月 论文推荐
12月已经过了一半了,还有2周就是2024年了,我们来推荐下这两周我发现的一些好的论文,另外再推荐2篇很好的英文文章。
大数据机器学习深度解读ROC曲线:技术解析与实战应用
本文全面探讨了ROC曲线(Receiver Operating Characteristic Curve)的重要性和应用,从其历史背景、数学基础到Python实现以及关键评价指标。文章旨在提供一个深刻而全面的视角,以帮助大家更好地理解和应用ROC曲线在模型评估中的作用。
大数据机器学习深度解读决策树算法:技术全解与案例实战
在决策树中,每个内部节点代表一个特征上的测试,每个分支代表测试的结果,而每个叶节点代表最终的决策结果。决策树的构建始于根节点,包含整个训练集,通过分裂成子节点的过程,逐渐学习数据中的规律。想象一下,我们面前有一篮水果,目的是区分苹果和橘子。一棵决策树可能首先询问:“这个水果的颜色是红色吗?”如果答案
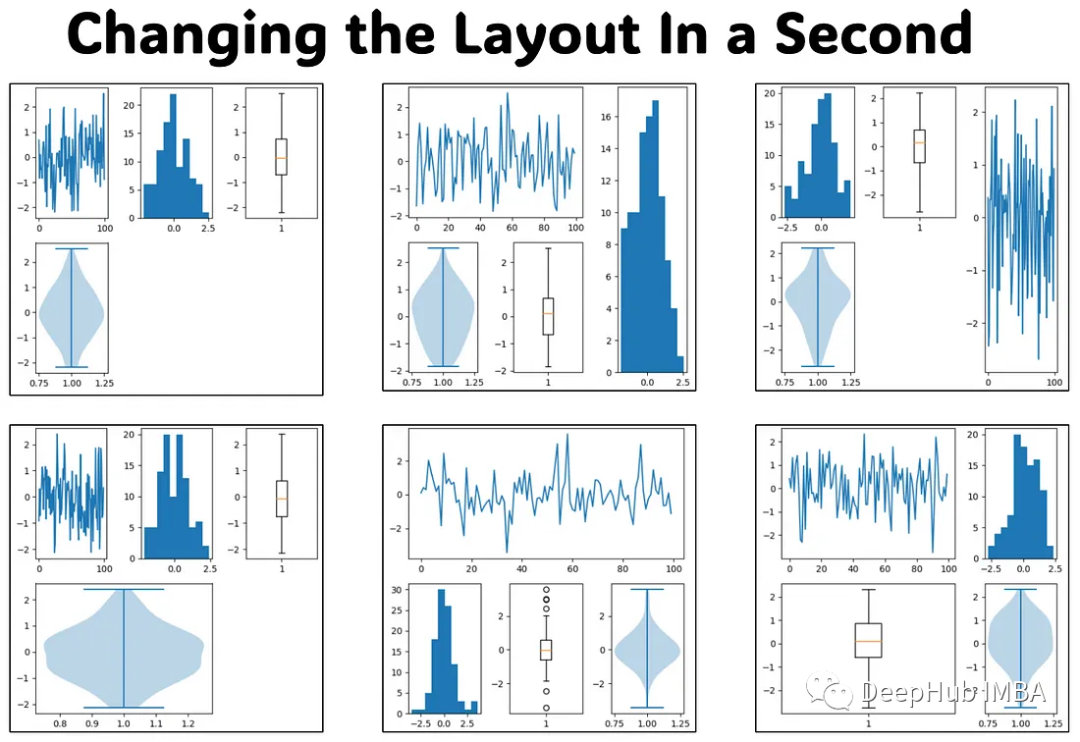
使用subplot_mosaic创建复杂的子图布局
在本文中,我将介绍matplotlib一个非常有价值的用于管理子图的函数——subplot_mosaic()。如果你想处理多个图的,那么subplot_mosaic()将成为最佳解决方案。我们将用四个不同的图实现不同的布局。
从零在单机上搭建k8s ,kubeflow1.7机器学习平台(国内环境)
折腾了好几天,写下这篇博客记录,希望能帮助需要的人。
信号与系统_微总结
信号与系统内容的微总结
Azure Machine Learning - 使用自己的数据与 Azure OpenAI 模型对话
在本文中,可以将自己的数据与 Azure OpenAI 模型配合使用。 对数据使用 Azure OpenAI 模型可以提供功能强大的对话 AI 平台,从而实现更快、更准确的通信。
机器学习与人工智能:一场革命性的变革
人工智能,因此,1956年也就成为了人工智能元年。达特茅斯会议-人工智能的起点人工智能、机器学习与深度学习的关系机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来。
机器学习多分类器有哪些
多类支持向量机的另一种改进方法——二次共轭损失函数的支持向量机分类器(Quadratic Conjugate Loss Function Support Vector Machine Multi-Classifier,QCLF-SVM-MC)多类支持向量机分类器的一种改进方法——总损失函数的支持向量
深度学习模型组件系列二:最常用的特征提取器
深度学习模型组件的特折提取器
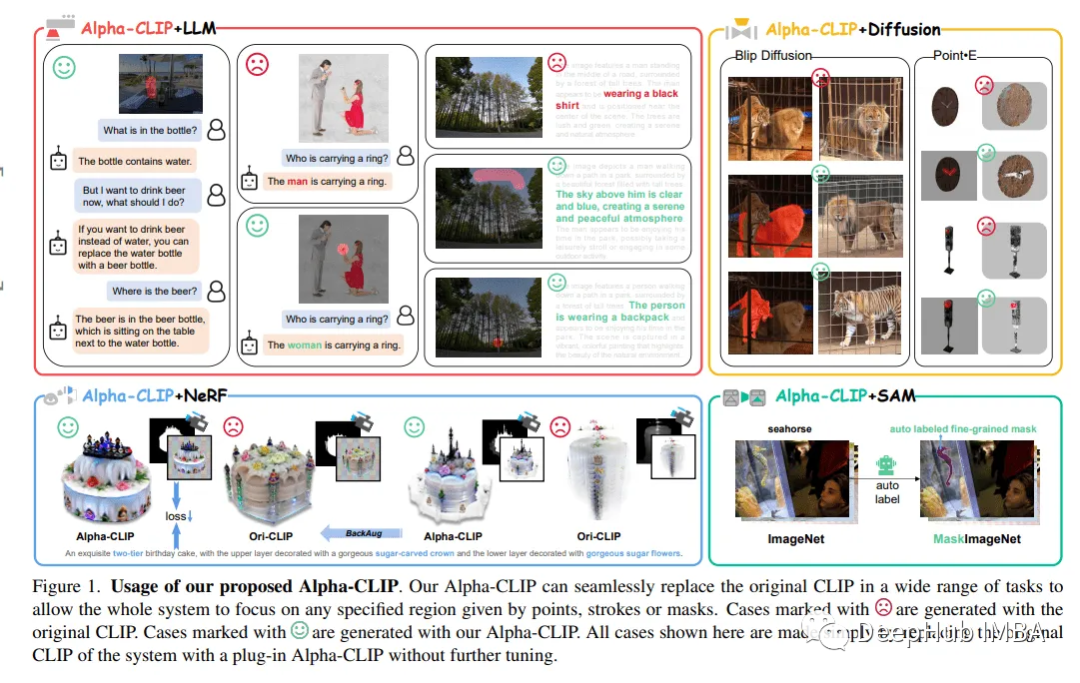
CLIP的升级版Alpha-CLIP:区域感知创新与精细控制
Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。



