机器学习(一)Spark机器学习基础
走到水果摊旁,挑了个色泽青绿、敲起来声音浊响的青绿西瓜,一边期待着西瓜皮薄肉厚瓤甜的爽落感,一边愉快地想着,明天学习Python机器学习一定要狠下功夫,基础概念搞得清清楚楚,案例作业也是信手拈来,我们的学习效果一定差不了。最大的一个区别就是它现在真的是深入到我们生活的每一个角落,打开你的手机看看,淘
Azure Machine Learning - 聊天机器人构建
本文介绍如何部署和运行聊天应用示例。 此示例使用 Python、Azure OpenAI 服务和 Azure AI 搜索中的检索扩充生成(RAG)实现聊天应用,以获取虚构公司员工福利的解答。
个人用户免费,亚马逊正式推出 AI 编程服务 CodeWhisperer
Copilot 服务每月费用为 10 美元(IT之家备注:当前约 69 元人民币),每年费用为 100 美元。CodeWhisperer 经过数十亿行代码的培训并由机器学习提供支持,无论您是学生、新开发人员还是经验丰富的专业人士,CodeWhisperer 都将帮助您提高工作效率。CodeWhisp
Spark基础入门
sparkcore sparksql sparkstreaming structedstreming
神经网络卷积反卷积及池化计算公式、特征图通道数(维度)变化实例
神经网络卷积反卷积及池化计算公式、特征图通道数(维度)变化实例
提高代码效率的6个Python内存优化技巧
有许多方法可以显著优化Python程序的内存使用,这些方法可能在实际应用中并没有人注意,所以本文将重点介绍Python的内置机制,掌握它们将大大提高Python编程技能。
【古诗生成AI实战】之四——模型包装器与模型的训练
中存储的正是这些词的概率。为了生成文本,我们提取每个位置上概率最高的词的索引,然后根据这些索引在词典中查找对应的词。此外,为了提高配置的灵活性和可维护性,我们将所有的配置项(如批量大小、数据集地址、训练周期数、学习率等)抽取出来,统一放置在一个名为。为此,我们采取了进一步的措施:在模型外面再套上一个
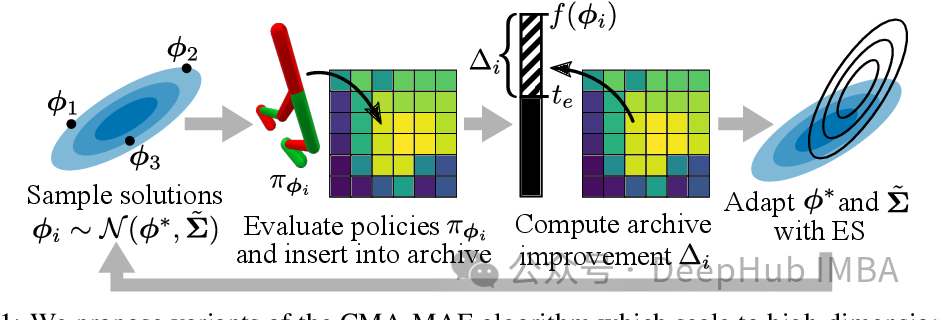
基于协方差矩阵自适应演化策略(CMA-ES)的高效特征选择
特征选择是指从原始特征集中选择一部分特征,以提高模型性能、减少计算开销或改善模型的解释性。
点云从入门到精通技术详解100篇-基于多传感器融合的紧耦合 SLAM 算法
减小到原来的二分之一,那么计算新的旋转矩阵是较为困难的。基于视觉的方法易受光线、天气变化的影响,这使得图像的特征发生变化,影响。了视觉特征的提取,导致难以解决在不同季节、不同天气条件下的建图问题。自身坐标的点云数据,并通过相邻帧之间的配准来估算位姿。传感器数据进行姿态的估计会存在较大的误差。位姿约束
AI:117-基于机器学习的环境污染影响评估
基于机器学习的环境污染影响评估随着全球工业化和城市化的加速发展,环境污染问题日益凸显,对人类生存和健康造成了严重威胁。为了更有效地监测和评估环境污染的影响,人工智能(AI)技术在环境科学领域展现出了巨大的潜力。本文将探讨基于机器学习的环境污染影响评估方法,并提供相应的代码实例。环境污染包括空气、水、
山东大学机器学习期末2022
本来是不想写的,因为不想回忆起考试时啥也不会的伤痛,没想到最后给分老师海底捞,心情好了一些,还是一块写完。
带你完全读懂正则化(看这一篇就够了)
想要了解什么是正则化 ,只需要看这一篇就够了
Boosting三巨头:XGBoost、LightGBM和CatBoost(发展、原理、区别和联系,附代码和案例)
机器学习中,提高模型精度是研究的重点之一,而模型融合技术中,Boosting算法是一种常用的方法。在Boosting算法中,XGBoost、LightGBM和CatBoost是三个最为流行的框架。它们在实际使用中有各自的优势和适用场景,下面将会介绍它们的区别与联系。
Spark GraphX:图计算框架初探
GraphX基于Spark的RDD(弹性分布式数据集)实现,能够自动地进行数据的分区和并行化,从而在大规模图数据上实现高效的计算。GraphX作为Apache Spark中的图计算框架,为大规模图数据的处理和分析提供了高效、可扩展的解决方案。未来随着图数据规模的不断增长和图计算技术的不断发展,Gra
c#联合Halcon进行几何定位
1: 首先配置在winfom引用程序中引用两个halcon应用程序的库:分别是halcon.dll和halcondotnet.dll,而后把这两个库放在你的应用程序输出路径下面,然后在下边的图片中取消首选32位的勾选。2:点击图片列表载入可以选择多幅图片并且在右上角的listbox控件中显示多幅图片
自动驾驶芯片指标AI算力TOPS和CPU算力DMIPS
DMIPS(Dhrystone Million Instructions Per Second,每秒处理的百万级的机器语言指令数),描述的是CPU的运算能力。GPU (Graphics Processing Unit):图形处理器,有大量的并行处理单元(如Nvidia RTX 4090有16384核
ChatGPT的工作原理(纯干货,万字长文)
ChatGPT 能够自动生成一些读起来表面上甚至像人写的文字的东西,这非常了不起,而且出乎意料。但它是如何做到的?为什么它能发挥作用?我在这里的目的是大致介绍一下 ChatGPT 内部的情况,然后探讨一下为什么它能很好地生成我们认为是有意义的文本。我首先要说明一下,我将把重点放在正在发生的事情的大的
世界各国当日数据探索性分析
在上一部分中,我们已经通过网络爬虫获取了国内外疫情数据,接下来我们将对世界各国当日数据进行探索性分析。在当日(2020年11月16日),全球疫情发展势头强劲,且在不同国家和不同地区中,疫情发展情况和爆发时间截然不同。为了对这种复杂多变的全球疫情形势做出直观的展示,在本部分的分析过程中,我们对各国现存
Azure AI 内容安全Content Safety Studio实战
Azure AI Content Safety 检测应用程序和服务中用户生成和 AI 生成的有害内容。 Azure AI 内容安全包括文本和图像 API,可用于检测有害材料。 交互式 Content Safety Studio,可用于查看、浏览和试用用于检测不同形式的有害内容的示例代码。

挑战Transformer的新架构Mamba解析以及Pytorch复现
今天我们来详细研究这篇论文“Mamba:具有选择性状态空间的线性时间序列建模”



