
基于BILSTM时间序列预测 python程序
特色:1、单变量,多变量输入,自由切换
2、单步预测,多步预测,自动切换
3、基于Pytorch架构
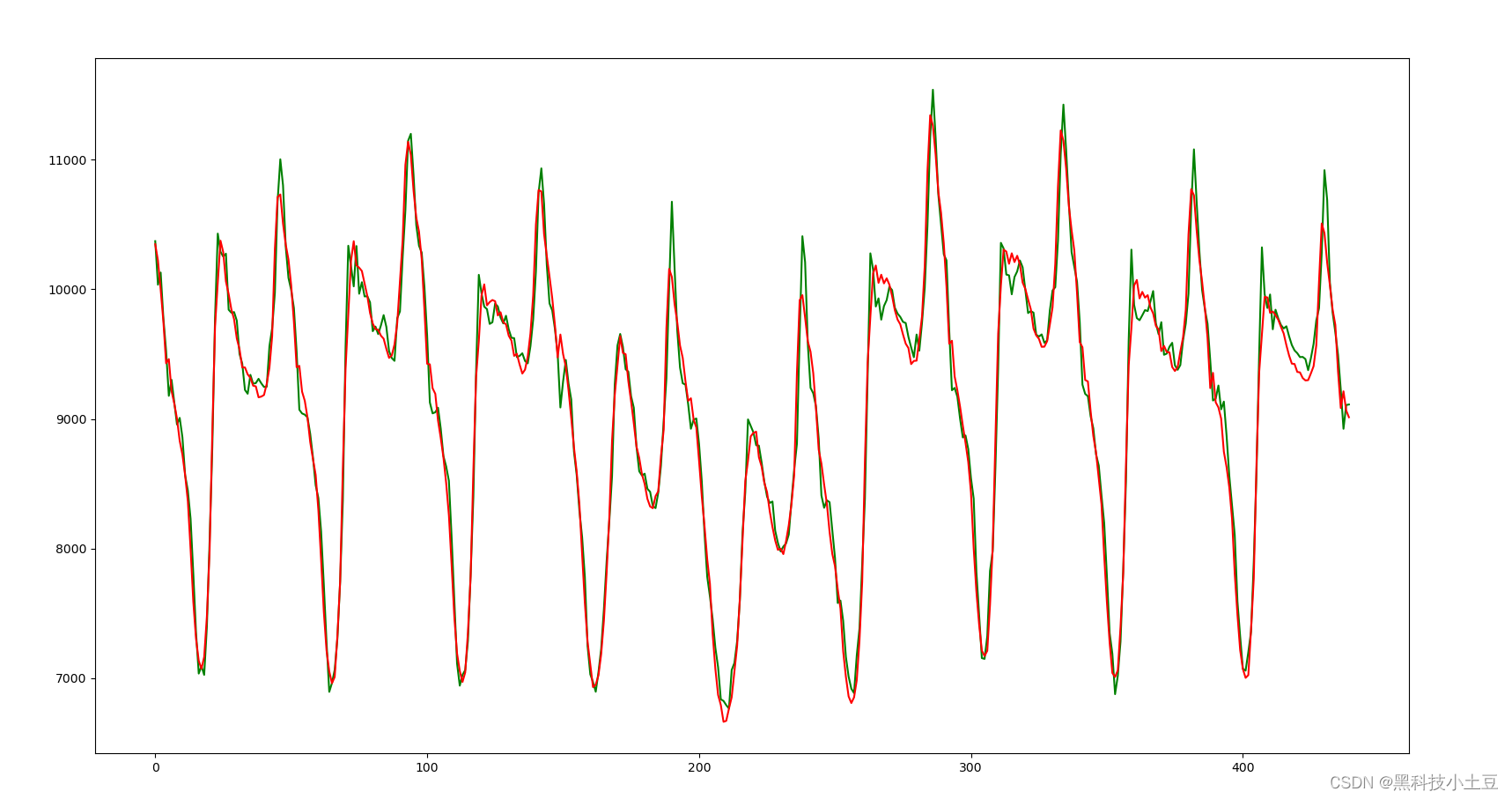
4、多个评估指标(MAE,MSE,R2,MAPE等)
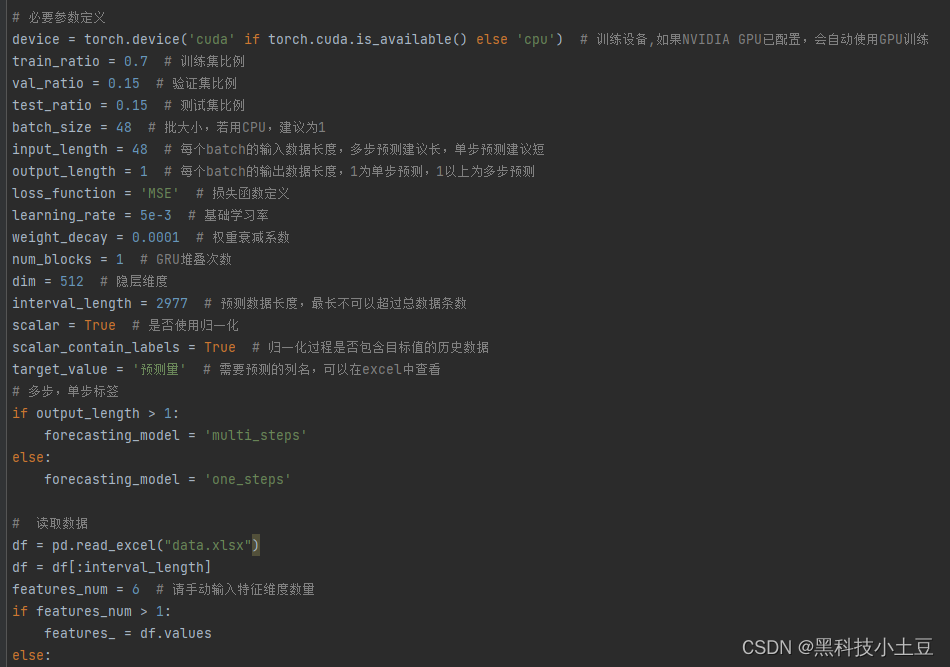
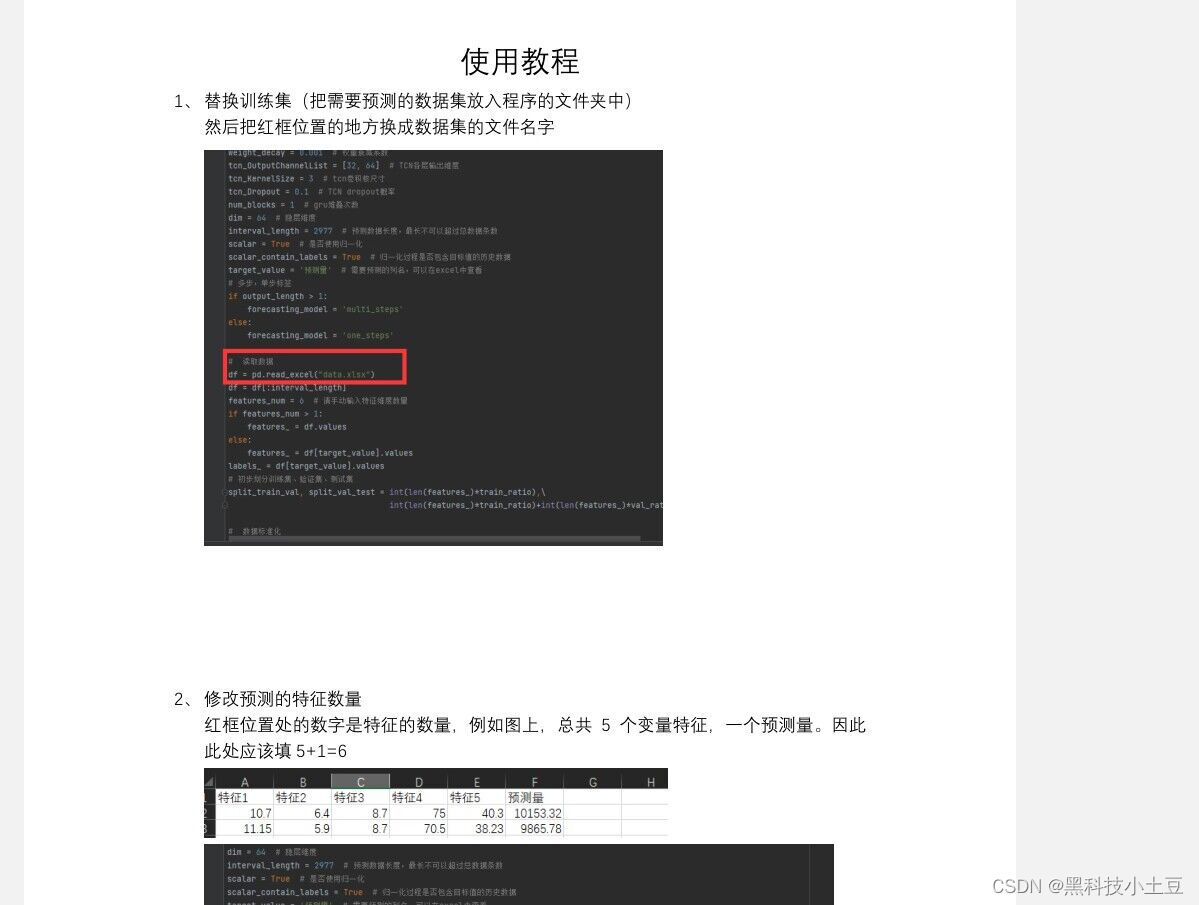
5、数据从excel文件中读取,更换简单
6、标准框架,数据分为训练集、验证集,测试集
全部完整的代码,保证可以运行的代码看这里。
http://t.csdn.cn/obJlChttp://t.csdn.cn/obJlC
!!!如果第一个链接打不开,请点击个人首页,查看我的个人介绍。
(搜索到的产品后,点头像,就能看到全部代码)
黑科技小土豆的博客_CSDN博客-深度学习,32单片机领域博主

BILSTM(Bidirectional Long Short-Term Memory)模型是对LSTM模型(Long Short-Term Memory)的改进,同样是双向循环神经网络。LSTM模型通过引入输入门、遗忘门和输出门等机制,有效地解决了长期依赖的问题,更适合处理时间序列数据。与LSTM模型不同的是,BILSTM模型通过前向和反向两个方向的LSTM隐含状态来寻找当前时刻的输出,从而更好地表示了时间序列数据的上下文信息。
在BILSTM模型中,前向和反向两个LSTM隐含状态通过拼接形成最终的输出,从而获得更全面的时间序列数据表示。相对于单向LSTM模型,BILSTM模型可以更有效地利用历史信息,从而提高序列数据的建模能力和预测性能。
BILSTM模型的优点包括:
- 通过引入输入门、遗忘门和输出门等机制,LSTM模型能够有效地解决长期依赖的问题,提高序列数据的建模能力和预测性能。
- 与单向LSTM模型相比,BILSTM模型能够更充分地利用历史信息,获得更全面的时间序列数据表示,并进而提高预测性能。 因此,BILSTM模型是一种适用于时间序列预测的有效模型,在文本分析、语音识别、情感分析等领域具有广泛的应用。
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, batch_size, device="cpu"):
super().__init__()
self.device = device
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=True)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_layers*2, batch_size, self.hidden_size).to(self.device)
c_0 = torch.randn(self.num_layers*2, batch_size, self.hidden_size).to(self.device)
output, (h,c) = self.lstm(input_seq, (h_0, c_0))
return output, h
本文转载自: https://blog.csdn.net/qq_41728700/article/details/129845034
版权归原作者 黑科技小土豆 所有, 如有侵权,请联系我们删除。
版权归原作者 黑科技小土豆 所有, 如有侵权,请联系我们删除。