机器学习期末复习题题库-单项选择题
1.属于监督学习的机器学习算法是:贝叶斯分类器2.属于无监督学习的机器学习算法是:层次聚类3.二项式分布的共轭分布是:Beta分布4.多项式分布的共轭分布是:Dirichlet分布5.朴素贝叶斯分类器的特点是:假设样本各维属性独立6.下列方法没有考虑先验分布的是:最大似然估计7.对于正态密度的贝叶斯
基于MATLAB的语音去噪处理系统
一.滤波器的简述在MATLAB环境下IIR数字滤波器和FIR数字滤波器的设计方 法即实现办法,并进行图形用户界面设计,以显示所介绍迷你滤波器的设计特性。 在无线脉冲响应(IIR)数字滤波器设计中,先进行模拟滤波器的设计,然后进行模拟数字滤波器转换,即采取脉冲响应不变法及双线性Z变更法设计数字滤波器

NeurIPS 2022-10大主题、50篇论文总结
2672篇主要论文,63场研讨会,7场受邀演讲,包括语言模型、脑启发研究、扩散模型、图神经网络……NeurIPS包含了世界级的AI研究见解,本文将对NeurIPS 2022做一个全面的总结。
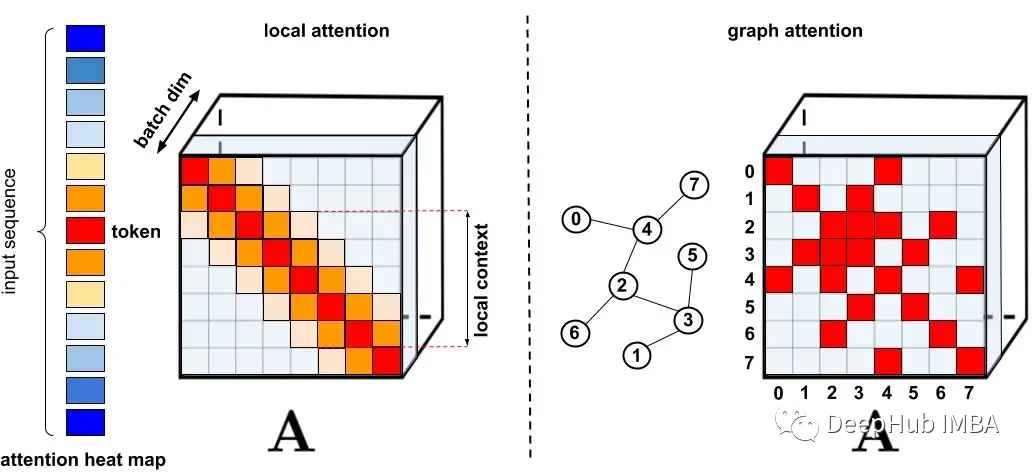
论文推荐:Rethinking Attention with Performers
重新思考的注意力机制,Performers是由谷歌,剑桥大学,DeepMind,和艾伦图灵研究所发布在2021 ICLR的论文已经超过500次引用
机器学习课后练习题(期末复习题目附答案)
此为第一章绪论部分一. 单选题1. 移动运营商对客户的流失进行预测,可以使用下面哪种机器学习方法比较合适( )A. 一元线性回归分析B. 关联方法C. 聚类算法D. 多层前馈网络正确答案: A2. 下面哪种说法有关机器学习的认识是错误的?( )A. 高质量的数据、算力和算法对一个机器学习项目是必不可
python h5py(h5文件) 文件内容读取
原文链接: python h5py(h5文件) 文件内容读取 ...
基于SARIMA、XGBoost和CNN-LSTM的时间序列预测对比
本文将讨论通过使用假设测试、特征工程、时间序列建模方法等从数据集中获得有形价值的技术。我还将解决不同时间序列模型的数据泄漏和数据准备等问题,并且对常见的三种时间序列预测进行对比测试。
SARScape中用sentinel-1数据做SBAS-InSAR完整流程(2/2)
SARScape中用sentinel-1数据做SBAS-InSAR完整流程(2/2)
人工智能与机器学习
主要介绍了人工智能与机器学习的概念,机器学习的流程,机器学习分类等。
图像数据的特征工程
总结了常用的图像特征工程,裁剪,灰度化,RGB通道选择,强度阈值,边缘检测和颜色过滤器
【一起啃西瓜书】机器学习-期末复习(不挂科)
【机器学习-期末复习爆肝2w字笔记整理分享】《机器学习》致力于研究如何通过计算的手段,利用经验来改善系统自身的性能,从而在计算机上从数据(经验)中产生“模型”,用于对新的情况给出判断(利用此模型预测未来的一种方法)。分为三类:监督学习、元监督学习、强化学习。

Waymo数据集介绍(部分下载,仅用于学习)
waymo提供了两种数据集,motion与perception两种其中motion在是鸟瞰图,官网中有介绍,主要用于轨迹预测之类的任务perception主要用于目标检测跟踪之类的任务,是第一视角,有相机和雷达信息,并且在github上有公开的读取数据方法,另外,在读取perception数据时需要
为机器学习模型设置最佳阈值:0.5是二元分类的最佳阈值吗
在本文中,我将展示如何从二元分类器中选择最佳阈值。
人工智能内容生成元年—AI绘画原理解析
AIGC元年达到了学术-商业共振,本文介绍现有AI绘画、AI作画背后的相应基本原理、应用、以及论文参考文献。
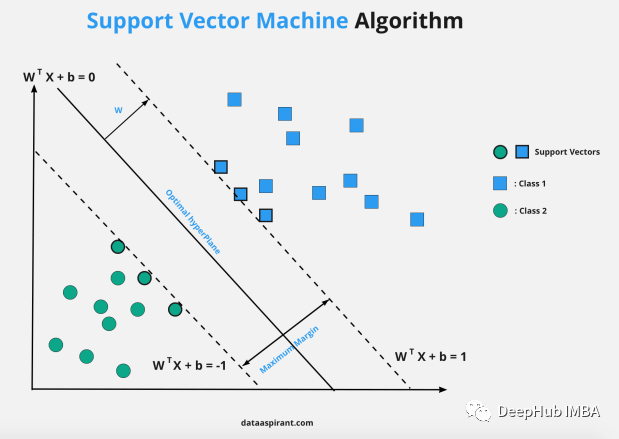
支持向量机核技巧:10个常用的核函数总结
支持向量机是一种监督学习技术,主要用于分类,也可用于回归。它的关键概念是算法搜索最佳的可用于基于标记数据(训练数据)对新数据点进行分类的超平面。
【实战 01】心脏病二分类数据集
1. 获取数据集2. 数据集介绍3. 数据预处理4. 构建随机森林分类模型5. 预测测试集数据6. 构建混淆矩阵7. 计算查全率、召回率、调和平均值8. ROC曲线、AUC曲线
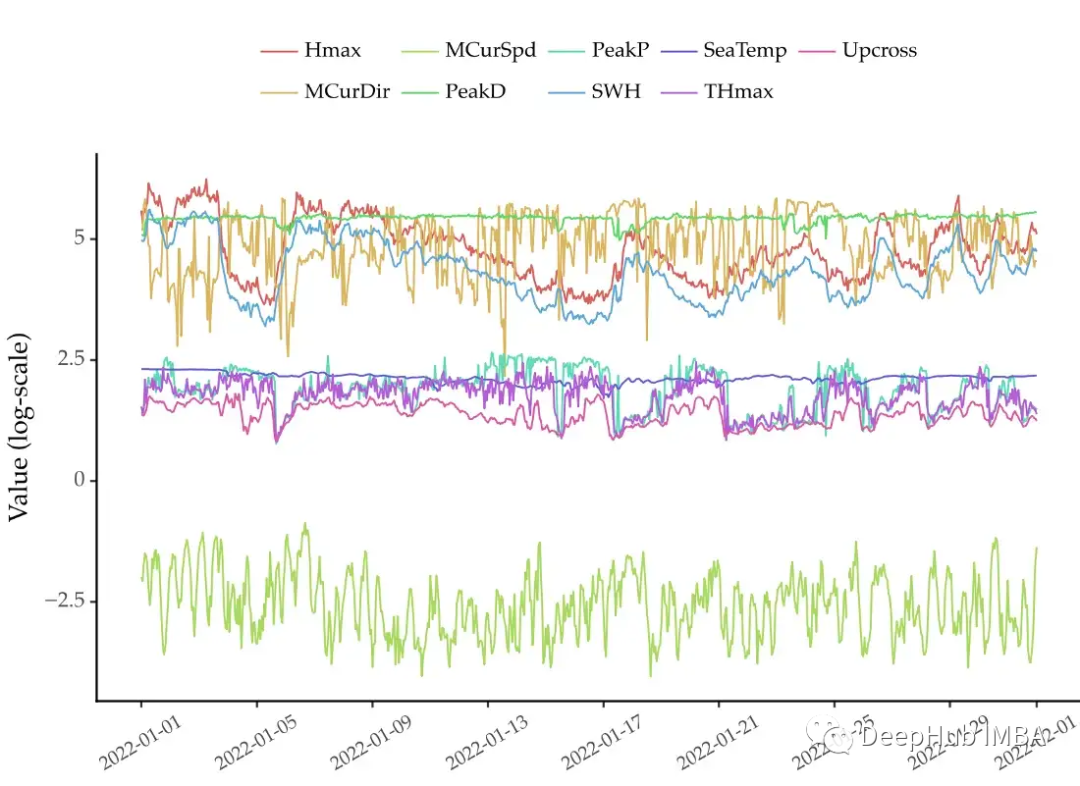
多元时间序列特征工程的指南
使用Python根据汇总统计信息添加新特性,本文将告诉你如何计算几个时间序列中的滚动统计信息。将这些信息添加到解释变量中通常会获得更好的预测性能。
LDA主题模型简介及Python实现
一、LDA主题模型简介LDA主题模型主要用于推测文档的主题分布,可以将文档集中每篇文档的主题以概率分布的形式给出根据主题进行主题聚类或文本分类。LDA主题模型不关心文档中单词的顺序,通常使用词袋特征(bag-of-word feature)来代表文档。词袋模型介绍可以参考这篇文章:文本向量化表示——
用强化学习玩《超级马里奥》
Pytorch的一个强化的学习教程( Train a Mario-playing RL Agent)使用超级玛丽游戏来学习双Q网络(强化学习的一种类型)



