阿里云天池大赛赛题(机器学习)——天猫用户重复购买预测(完整代码)
阿里云天池大赛赛题(机器学习)——天猫用户重复购买预测 完整代码!
【机器学习】Logistic 分类回归算法 (二元分类 & 多元分类)
一、线性回归能用于分类吗?二、二元分类2.1假设函数2.1.1例子一2.1.2例子二2.2拟合logistic回归参数\thetaθ三、logistic代价函数3.1 y = 1的图像3.2 y = 0的图像四、 代价函数与梯度下降4.1 线性回归与logistic回归的梯度下降规则相同吗?五、高级
【机器学习】数据增强(Data Augmentation)
文章目录一、引言 - 背景二、为什么需要数据增强?三、什么是数据增强?定义分类四、有监督的数据增强1. 单样本数据增强(1)几何变换类(2)颜色变换类2. 多样本数据增强(1) SMOTE(2) SamplePairing(3) mixup五、无监督的数据增强1. GAN2.Conditional
常用的激活函数(Sigmoid、Tanh、ReLU等)
目录一、激活函数定义二、梯度消失与梯度爆炸 1.什么是梯度消失与梯度爆炸2.梯度消失的根本原因3.如何解决梯度消失与梯度爆炸问题 三、常用激活函数1.Sigmoid2.Tanh3.ReLU4.Leaky ReLU5.ELU6.softmax7.Swish 激活函数 (Activatio
人工智能--遗传算法求解TSP问题
文章目录前言一、遗传算法的概念遗传算法(Genetic Algorithm, GA):二、解决的问题对象三、 程序步骤1.针对TSP问题,确定编码2.针对TSP问题,适应度函数可定义为3.针对TSP问题,确定交叉规则对于采用整数编码表示的染色体,可以有以下交叉规则:(1)顺序交叉法(Order Cr
机器学习笔记 - 什么是高斯混合模型(GMM)?
高斯混合模型 (GMM) 是一种机器学习算法。它们用于根据概率分布将数据分类为不同的类别。高斯混合模型可用于许多不同的领域,包括金融、营销等等!这里要对高斯混合模型进行介绍以及真实世界的示例、它们的作用以及何时应该使用GMM。高斯混合模型 (GMM) 是一个概率概念,用于对真实世界的数据集进行建模。
用pointnet++分类自己的点云数据
这篇博客主要是针对于现有的热门的激光点云处理算法pointnet++如何分类自己的数据集展开的。在介绍基本的pointnet++算法的概念、基本步骤及思想、部分代码讲解之后,会介绍如何使用自己的数据集进行分类(涉及到详细的代码改进方法及步骤)以及打印利用自己数据集跑出的模型后的点云坐标。

PyTorch的Dataset 和TorchData API的比较
从版本1.11开始,PyTorch引入了TorchData库,它实现了一种不同的加载数据集的方法。

如何检测时间序列中的异方差(Heteroskedasticity)
异方差性影响时间序列建模。因此检测和处理这种情况非常重要。

15个节省时间的Jupyter技巧
Jupyter Notebooks使用非常简单并且对于任何面向python的任务都可以非常方便的使用。
变分自编码器VAE的数学原理
变分自编码器(VAE)是一种应用广泛的无监督学习方法,它的应用包括图像生成、表示学习和降维等。
机器学习进阶之 时域/时间卷积网络 TCN 概念+由来+原理+代码实现
TCN 从“阿巴阿巴”到“巴拉巴拉”TCN的概念(干嘛来的!能解决什么问题)TCN的父母(由来)TCN的原理介绍上代码!1、TCN(时域卷积网络、时间卷积网络)是干嘛的,能干嘛主要应用方向:时序预测、概率预测、时间预测、交通预测2、TCN的由来ps:在了解TCN之前需要先对CNN和RNN有一定的了解
OpenAI发布ChatGPT:程序员瞬间不淡定了
2月1日,OpenAI发布了针对对话场景优化的语言大模型ChatGPT。一经发布便受到科技圈的广泛关注,我第一时间体验了ChatGPT,给大家奉上最新鲜的体验报告。

Pandas中高效的选择和替换操作总结
在本文中,我们将重点介绍在DataFrame上经常执行的两个最常见的任务,有效地选择特定的和随机的行和列,以及使用replace()函数使用列表和字典替换一个或多个值。
一文读懂K-Means原理与Python实现
在本文中,你将学习到K-means算法的数学原理,作者会以尼日利亚音乐数据集为案例。带你了解了如何通过可视化的方式发现数据中潜在的特征。最后对训练好的K-means模型进行评估。

计算机视觉面试中一些热门话题整理
通常在机器学习面试中,问完常见基础知识的技术问题之后会有具体的项目问题的讨论,所以这里准备了一些项目相关的话题,以可以帮助你准备和通过计算机视觉相关的面试。
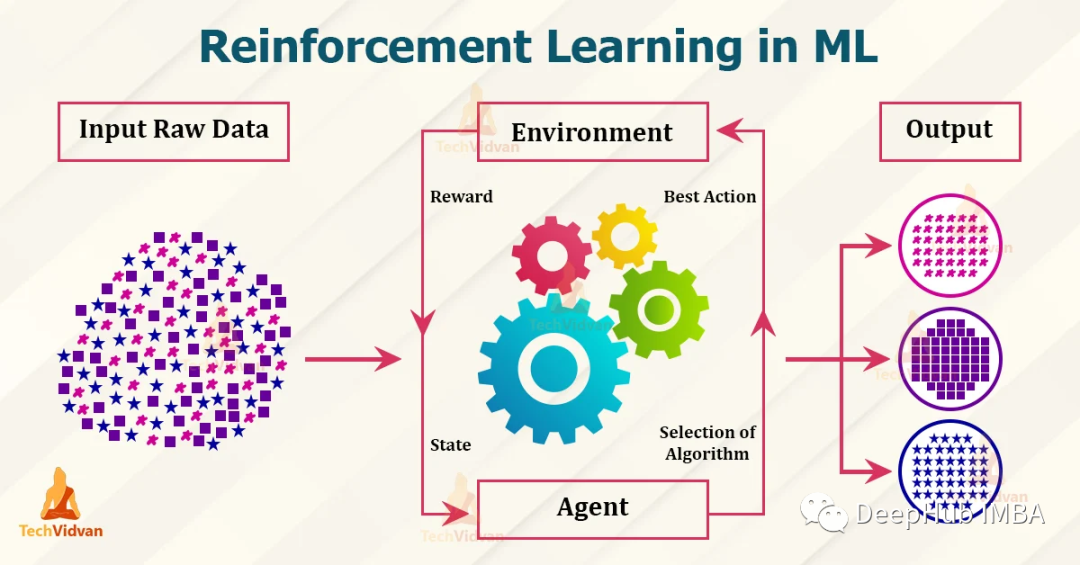
强化学习的基础知识和6种基本算法解释
本文将涉及强化学习的术语和基本组成部分,以及不同类型的强化学习(无模型、基于模型、在线学习和离线学习)。本文最后用算法来说明不同类型的强化学习。

Python中的魔法方法
python中的魔法方法是一些可以让你对类添加“魔法”的特殊方法,它们经常是两个下划线包围来命名的
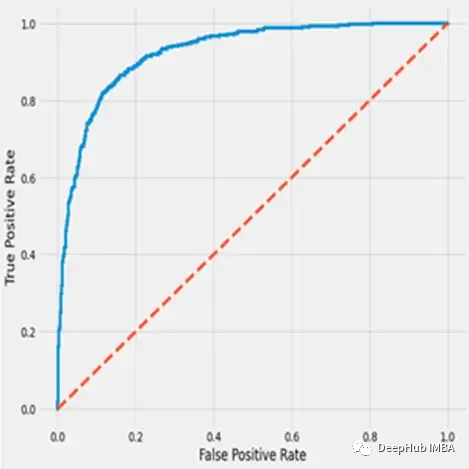
从另外一个角度解释AUC
AUC到底代表什么呢,我们从另外一个角度解释AUC
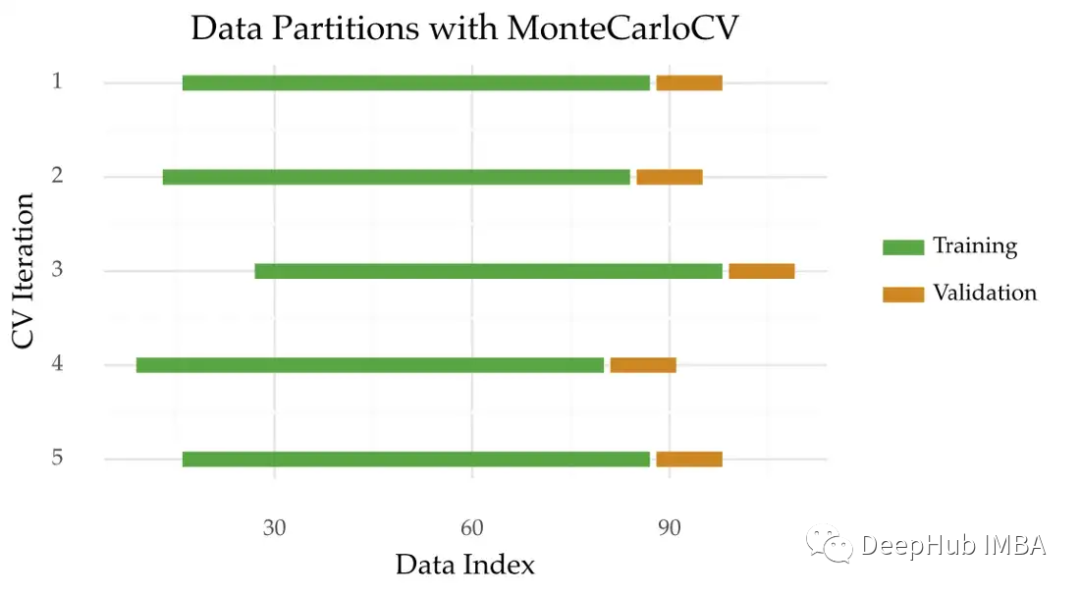
时间序列的蒙特卡罗交叉验证
交叉验证应用于时间序列需要注意是要防止泄漏和获得可靠的性能估计本文将介绍蒙特卡洛交叉验证。这是一种流行的TimeSeriesSplits方法的替代方法。



