【实战 01】心脏病二分类数据集
1. 获取数据集2. 数据集介绍3. 数据预处理4. 构建随机森林分类模型5. 预测测试集数据6. 构建混淆矩阵7. 计算查全率、召回率、调和平均值8. ROC曲线、AUC曲线
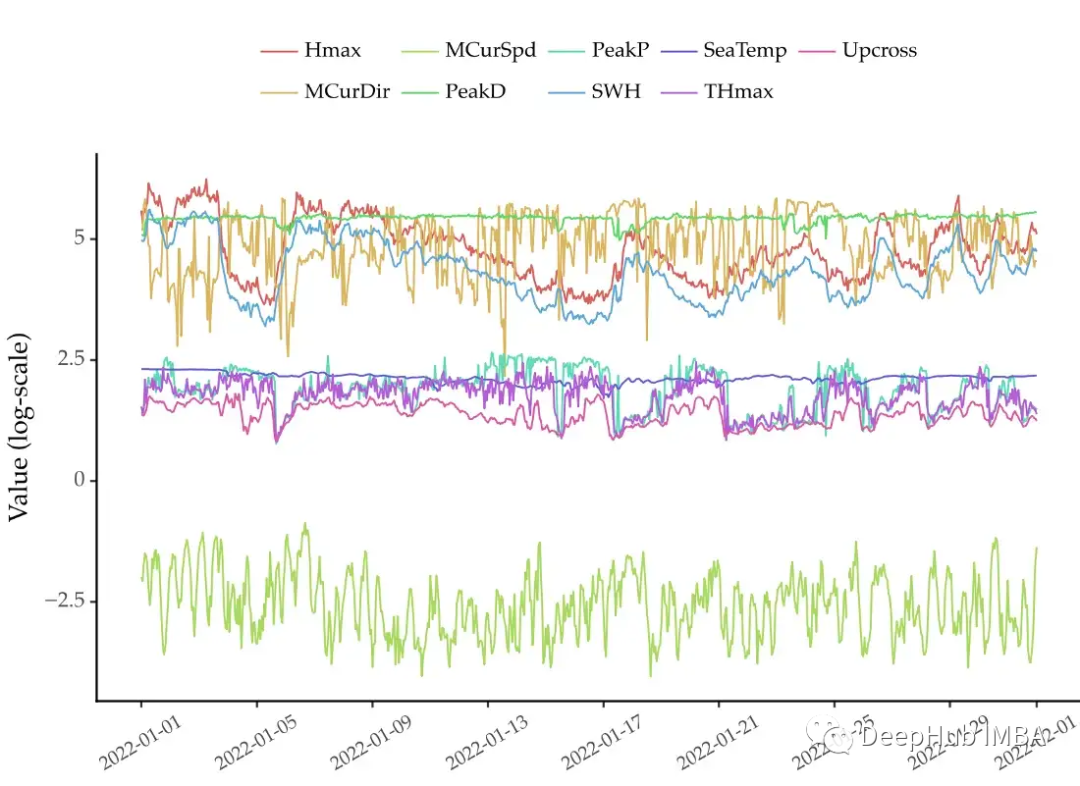
多元时间序列特征工程的指南
使用Python根据汇总统计信息添加新特性,本文将告诉你如何计算几个时间序列中的滚动统计信息。将这些信息添加到解释变量中通常会获得更好的预测性能。
LDA主题模型简介及Python实现
一、LDA主题模型简介LDA主题模型主要用于推测文档的主题分布,可以将文档集中每篇文档的主题以概率分布的形式给出根据主题进行主题聚类或文本分类。LDA主题模型不关心文档中单词的顺序,通常使用词袋特征(bag-of-word feature)来代表文档。词袋模型介绍可以参考这篇文章:文本向量化表示——
用强化学习玩《超级马里奥》
Pytorch的一个强化的学习教程( Train a Mario-playing RL Agent)使用超级玛丽游戏来学习双Q网络(强化学习的一种类型)

MSE = Bias² + Variance?什么是“好的”统计估计器
本文的目的并不是要证明这个公式,而是将他作为一个入口,让你了解统计学家如何以及为什么这样构建公式,以及我们如何判断是什么使某些估算器比其他估算器更好。
one-hot编码
one-hot编码,又称独热编码、一位有效编码。one hot在特征提取上属于词袋模型(bag of words)优缺点分析优点:- 一是解决了分类器不好处理离散数据的问题- 二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)缺点:- 它是一个词袋模型,不考虑词与词之间的顺序-

10个实用的数据可视化的图表总结
可视化是一种方便的观察数据的方式,可以一目了然地了解数据块。我们经常使用柱状图、直方图、饼图、箱图、热图、散点图、线状图等。这些典型的图对于数据可视化是必不可少的
使用Python进行交易策略和投资组合分析
我们将在本文中衡量交易策略的表现。并将开发一个简单的动量交易策略,它将使用四种资产类别:债券、股票和房地产。这些资产类别的相关性很低,这使得它们成为了极佳的风险平衡选择。
机器学习【期末复习总结】——知识点和算法例题(详细整理)
【电子科技大学、机器学习课程】(期末复习、知识点和算法例题、详细总结)
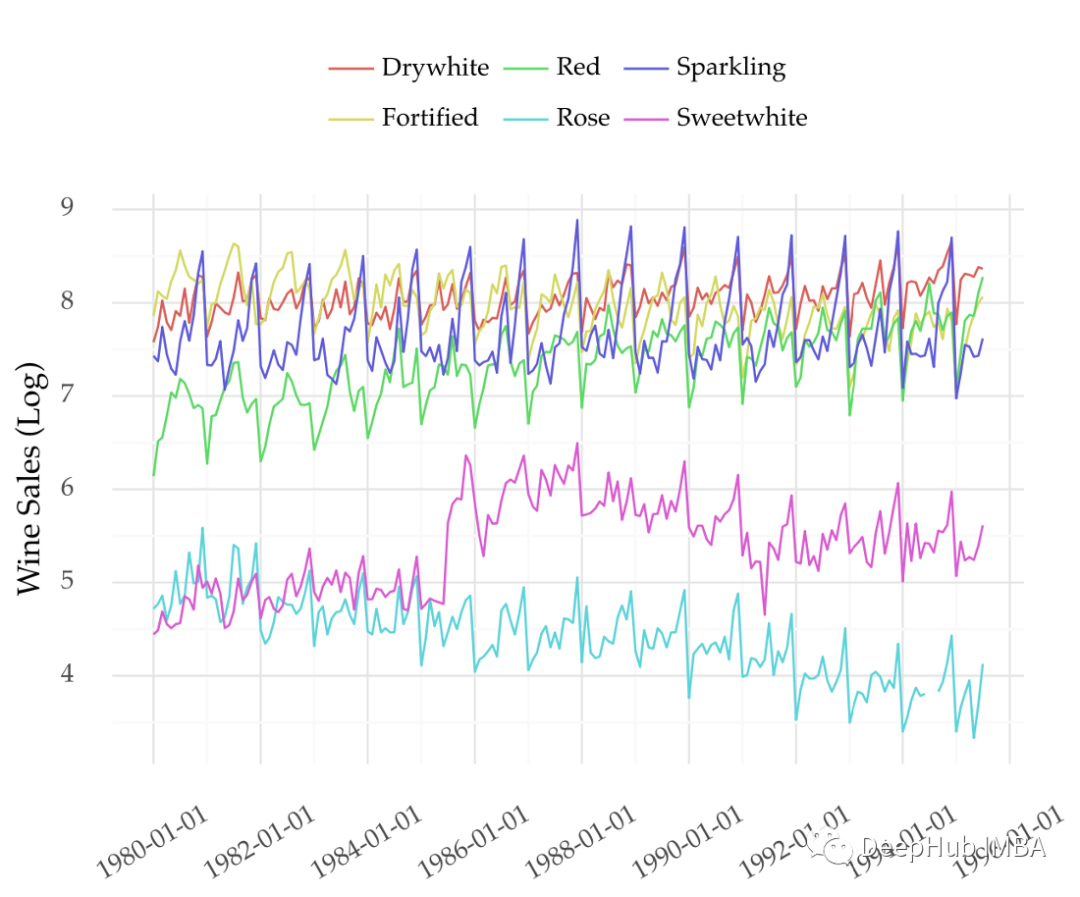
自回归滞后模型进行多变量时间序列预测
本文的主要内容如下:多变量时间序列包含两个或多个变量;ARDL 方法可用于多变量时间序列的监督学习;使用特征选择策略优化滞后数。如果要预测多个变量,可以使用 VAR 方法。
阿里云天池大赛赛题(机器学习)——天猫用户重复购买预测(完整代码)
阿里云天池大赛赛题(机器学习)——天猫用户重复购买预测 完整代码!
深度学习常见名词概念:Sota、Benchmark、Baseline、端到端模型、迁移学习等的定义
深度学习:Sota的定义sota实际上就是State of the arts 的缩写,指的是在某一个领域做的Performance最好的model,一般就是指在一些benchmark的数据集上跑分非常高的那些模型。
手把手调参最新 YOLOv7 模型 训练部分 - 最新版本(二)
YOLO科研Trick改进推荐 | 包括Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数
吴恩达 - 机器学习课程笔记(持续更新)
吴恩达机器学习
2022 CCF BDCI 返乡发展人群预测 [0.9117+]
返乡发展人群预测:基于中国联通的大数据能力,通过使用对联通的信令数据、通话数据、互联网行为等数据进行建模,对个人是否会返乡工作进行判断A榜的结果为0.91171720。
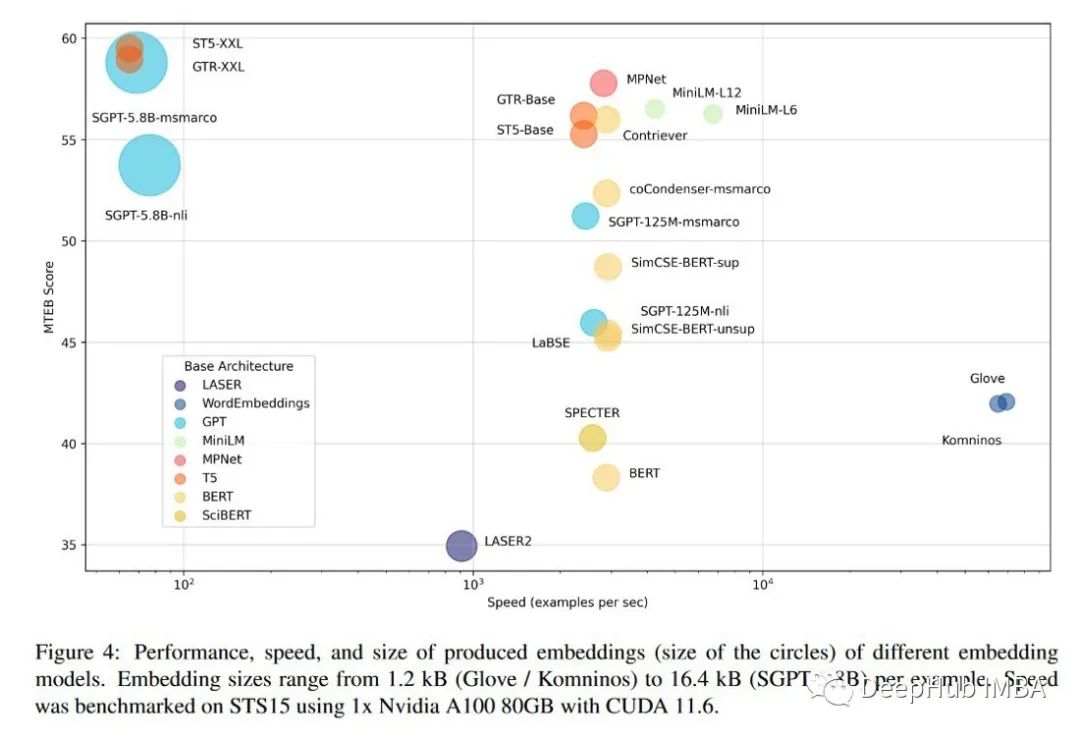
2022年11月10篇论文推荐
介绍10篇推荐的论文。这里将涵盖强化学习(RL)、扩散模型、自动驾驶、语言模型等主题。
特征选择技术总结
在本文中,我们将回顾特性选择技术并回答为什么它很重要以及如何使用python实现它。
NLP--社区检测算法(Community Detection)总结【原理】
社区检测(Community Detection)又被称为是社区发现,用于评估节点组如何聚类或分区,以及它们增强或分离的趋势。重点对图算法中的社区检测进行了整理总结。

可解释的AI:用LIME解释扑克游戏
可解释的AI(XAI)一直是人们研究的一个方向,在这篇文章中,我们将看到如何使用LIME来解释一个模型是如何学习扑克规则的。



