阵列信号处理——线性约束最小方差准则(LCMV)波束形成算法
阵列信号处理——线性约束最小方差准则(LCMV)波束形成算法
ChatGPT作者John Schulman:我们成功的秘密武器
除了OpenAI,外界可能很少有人知道ChatGPT模型成功的真正原因,实际上,OpenAI也会对ChatGPT拥有的巨大影响力感到不可思议。这种困惑和惊喜就像工程师们解bug时获得的意外成功:We don't know why, but it works.一种普遍的看法是,ChatGPT没有任何革
机器学习10—多元线性回归模型
在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。这时采用一元回归分析预测法进行
模型调优:验证集的作用(就是为了调整超参数)
注意这里的表现,是指在验证集上的表现。好比训练轮数(epochs),在同样的训练集上,训练3轮和训练10轮,结果肯定是不一样的模型。一般训练几个 epoch 就跑一次验证看看效果,如果发现训练3轮效果更好,那么就应该丢弃掉训练6轮、10轮的潜在模型,只用训练3轮的结果。所以必须从训练样本中取出一部分
机器学习中常用的分类算法总结
我们都知道,不发生的概率是极大的,对于分类器而言,如果分类器不加思考,对每一个测试样例的类别都划分为0,达到99%的正确率,但是,问题来了,如果真的发生地震时,这个分类器毫无察觉,那带来的后果将是巨大的。4)例如True positives(TP)的实际类标=1*1=1为正例,False posit
人工智能-10种机器学习常见算法
机器学习是目前行业的一个创新且重要的领域。今天,给大家介绍机器学习中的10种常见的算法,希望可以帮助大家适应机器学习的世界。1、线性回归线性回归(Linear Regression)是目前机器学习算法中最流行的一种,线性回归算法就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过
gma 教程 | 气候气象 | 计算标准化降水指数(SPI)
【基于 Excel 降水和蒸散数据计算 SPI】【基于 GTiff 栅格降水和蒸散数据计算 SPI】
Softmax分类器及交叉熵损失(通俗易懂)
简单的说,softmax函数会将输出结果缩小到0到1的一个值,并且所有值相加为1,cross-entropy一般再softmax函数求得结果后再用,
深度学习:根据 loss曲线,对模型调参
深度学习模型调参笔记train loss 下降,val loss下降,说明网络仍在学习; 奈斯,继续训练train loss 下降,val loss上升,说明网络开始过拟合了;赶紧停止,然后数据增强、正则train loss 不变,val loss不变,说明学习遇到瓶颈;调小学习率或批量数目trai
GAN(生成对抗网络)Matlab代码详解
这篇博客主要是对GAN网络的代码进行一个详细的讲解:首先是预定义:clear; clc; %%%clc是清除当前command区域的命令,表示清空,看着舒服些 。而clear用于清空环境变量。两者是不同的。%%%装载数据集train_x=load('Normalization_wbc.txt');%
深度学习:交叉验证(Cross Validation)
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。好处:处理简单,只需随机把原始数据分为两组即可坏处:但没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的
Win7 64 位 Vcode Python安装与环境配置
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言 一、pandas是什么? 二、使用步骤 1.引入库 2.读入数据 总结前言提示:这里可以添加本文要记录的大概内容:例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器
周志华《机器学习》第三章课后习题
目录3.1 试析在什么情形下式(3.2) 中不必考虑偏置项 b.3.2、试证明,对于参数w,对率回归的目标函数(3.18)是非凸的,但其对数似然函数(3.27)是凸的. 3.3、编程实现对率回归,并给出西瓜数据集3.0α上的结果.3.4 选择两个 UCI 数据集,比较 10 折交叉验证法和留一法所估
GPT4来了,多模态模型上线
如此火的GPT-4是源于支持多模态,那到底什么是多模态呢?什么是模态?模态是一种社会性、文化性的资源,是物质媒体经过时间塑造而形成的意义潜势。从社会符号学的角度上对模态的认知可以是声音、文字和图像等。人类通过眼睛、耳朵、触觉等各种感觉器官接触世界,每种信息的来源或形式都可以称之为模态。同时,模态也可
计算机视觉方面的三大顶级会议:ICCV,CVPR,ECCV(统称ICE)
ICCV/CVPR/ECCV
深度学习从入门到精通——基于深度学习的地震数据去噪处理
传统机器学习SVM,boosting,bahhing,knn深度学习CNN(典型),GAN地震应用方向叠前地震数据随机噪声去除,实现噪声分离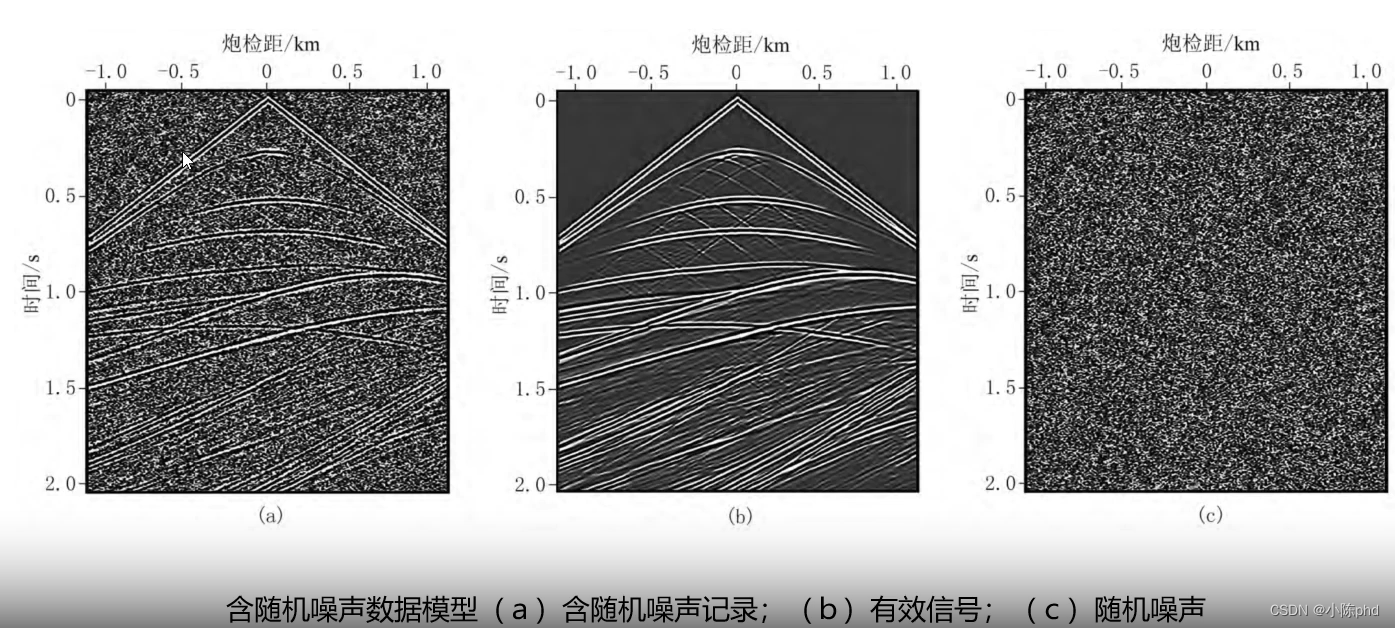面波去噪面波作
自己动手做chatGPT:向量的概念和相关操作
介绍深度学习算法中最基本单元向量,为开发chatGPT模型大小基础
在 AI 上训练 AI:ChatGPT 上训练另一种机器学习模型
在 AI 上训练 AI:ChatGPT 上训练另一种机器学习模型
MATLAB环境下基于振动信号的轴承状态监测和故障诊断
基于现代信号处理的轴承状态监测和故障诊断。本文主要讲解如何从滚动轴承的振动信号中提取特征、进行状态监测和故障诊断。
LDA(线性判别分析(普通法))详解 —— matlab
前言正题1.LDA的思想2. 瑞利商(Rayleigh quotient)与广义瑞利商(genralized Rayleigh quotient)3. 二类LDA原理4.多类LDA原理5.LDA算法流程二类LDA matlab举例:1.读取数据集2.分离数据集3.求解w4.输出降维后的数据集



