
今年可以说是分割算法爆发的一年,首先Vit通过引入transform将ADE20K mIOU精度第一次刷到50%,超过了之前HRnet+OCR效果,然后再是Swin屠榜各大视觉任务,在分类,语义分割和实例分割都做到了SOTA,斩获ICCV2021的bset paper,然后Segformer有凭借对transform再次深层次优化,在拿到更高精度的基础之上还大大提升了模型的实时性。
代码:https://github.com/NVlabs/SegFormer
论文:https://arxiv.org/abs/2105.15203
一般的语义分割算法,endoer一般会输出高分辨率的粗粒度特征和低分辨率的细粒度特征,好处是像素分类更准以及边缘更精细。
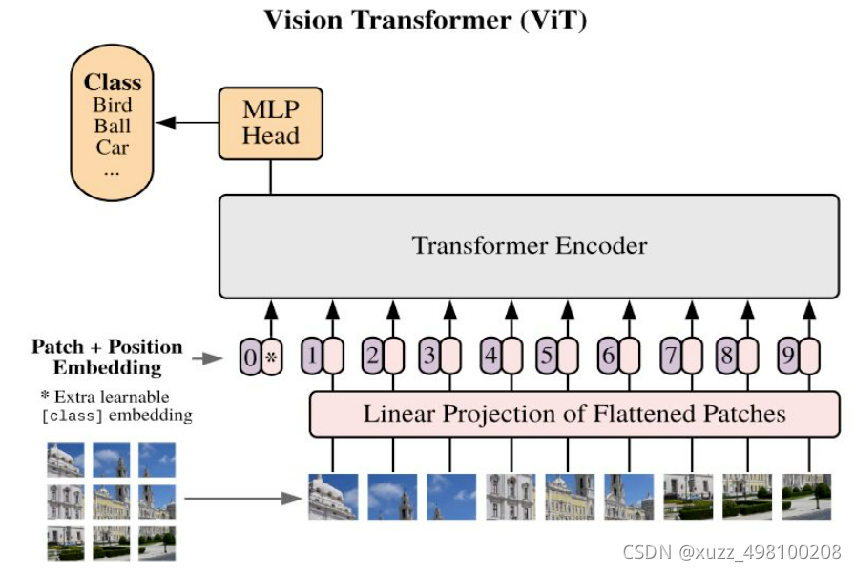
Vit是最早将transform引入语义分割的一批算法。在ADE20K等公开数据集上相比之前基于CNN的一票分割算法在精度层面有着明显优势,但是也还有很多缺点:
1.ViT-large 参数和计算量非常大,有300M+参数
2.ViT的结构不太适合做语义分割,只能输出固定分辨率的feature map, 比如1/16, 过低分辨率对轮廓要求比较精细的场景太不友好
3.ViT的柱状结构n2复杂度,对显存的负担非常大
4.位置编码, 但是语义分割在测试的时候往往图片的分辨率不是固定的,这时要么对positional embedding做双线性插值,这会损害性能, 要么滑窗,这样效率很低而且很不灵活
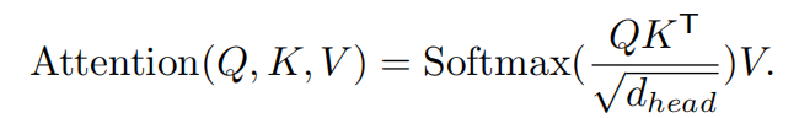
改进:提出了
Efficient Self-Attention:
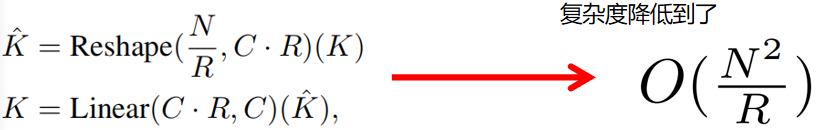
这里直接上代码:
这是segformer的self attention实现:
EfficientMultiheadAttention(MultiheadAttention)
注意这里的qkv计算实际上是继承的pytorch的
nn.MultiheadAttention计算
defforward(self, x, hw_shape, identity=None):
x_q = x
if self.sr_ratio >1:
x_kv = nlc_to_nchw(x, hw_shape)
x_kv = self.sr(x_kv)
x_kv = nchw_to_nlc(x_kv)
x_kv = self.norm(x_kv)else:
x_kv = x
if identity isNone:
identity = x_q
out = self.attn(query=x_q, key=x_kv, value=x_kv, need_weights=False)[0]return identity + self.dropout_layer(self.proj_drop(out))
可以看到作者提出来的Efficient Self-Attention本质其实是增加了一个sr_ratio超参,通过sr_ratio来控制KV参数矩阵的尺寸,具体实现是这样的:
self.sr_ratio = sr_ratio
if sr_ratio >1:
self.sr = Conv2d(
in_channels=embed_dims,
out_channels=embed_dims,
kernel_size=sr_ratio,
stride=sr_ratio)
Overlapped Patch Merging
这种直接分割方式不能保证这些patch的局部连续性
优化:
作者设置了超参S
将切割后的小图按照一定步长(S)
合并,通过控制小图大小/padding大小/步长产生没有Overlap时的大小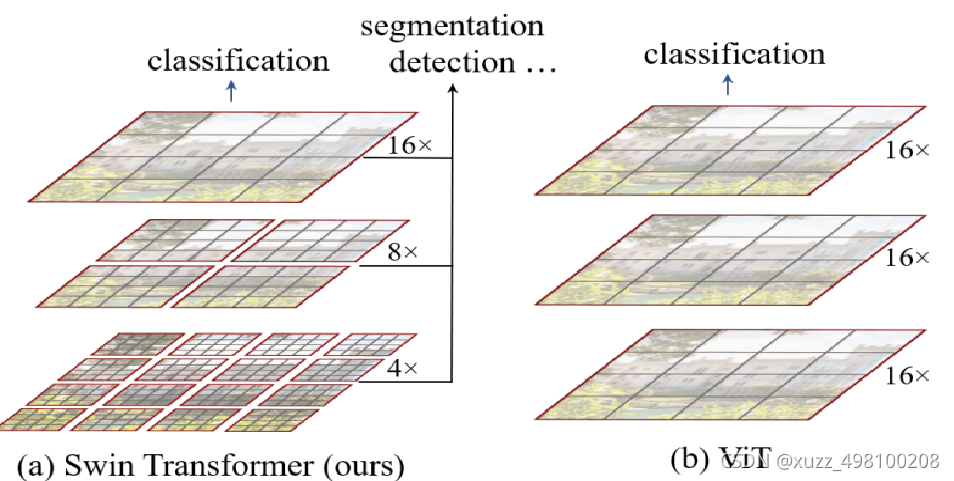
Mix-FFN
ViT使用位置编码(PE)来介绍位置信息。然而,PE的分辨率是固定的。因此,当测试分辨率不同于训练率时,位置代码需要进行插值,这通常会导致精度下降。作者认为,位置编码实际上并不是语义分割的必要条件,Segform引入了Mix-FFN,它通过直接在前馈网络(FFN)中使用3×3Conv传递位置信息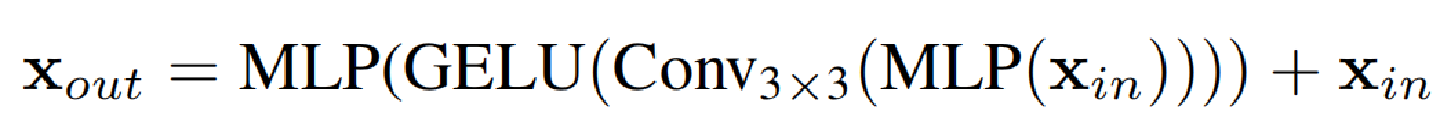
classMixFFN(BaseModule):def__init__(self,
embed_dims,
feedforward_channels,
act_cfg=dict(type='GELU'),
ffn_drop=0.,
dropout_layer=None,
init_cfg=None):super(MixFFN, self).__init__(init_cfg)
self.embed_dims = embed_dims
self.feedforward_channels = feedforward_channels
self.act_cfg = act_cfg
self.activate = build_activation_layer(act_cfg)
in_channels = embed_dims
fc1 = Conv2d(
in_channels=in_channels,
out_channels=feedforward_channels,
kernel_size=1,
stride=1,
bias=True)# 3x3 depth wise conv to provide positional encode information
pe_conv = Conv2d(
in_channels=feedforward_channels,
out_channels=feedforward_channels,
kernel_size=3,
stride=1,
padding=(3-1)//2,
bias=True,
groups=feedforward_channels)
fc2 = Conv2d(
in_channels=feedforward_channels,
out_channels=in_channels,
kernel_size=1,
stride=1,
bias=True)
drop = nn.Dropout(ffn_drop)
layers =[fc1, pe_conv, self.activate, drop, fc2, drop]
self.layers = Sequential(*layers)
self.dropout_layer = build_dropout(
dropout_layer)if dropout_layer else torch.nn.Identity()defforward(self, x, hw_shape, identity=None):
out = nlc_to_nchw(x, hw_shape)
out = self.layers(out)
out = nchw_to_nlc(out)if identity isNone:
identity = x
return identity + self.dropout_layer(out)
上面代码本质上就是利用3X3的conv学习位置信息
这里注意一下,在transform算法中,激活函数不再是我们所熟悉的Relu,而是Gelu,这个也不是说随便就换上去的。
在神经网络的建模过程中,模型很重要的性质就是非线性,同时为了模型泛化能力,需要加入随机正则,例如dropout(随机置一些输出为0,其实也是一种变相的随机非线性激活), 而随机正则与非线性激活是分开的两个事情, 而其实模型的输入是由非线性激活与随机正则两者共同决定的。
GELUs正是在激活中引入了随机正则的思想,是一种对神经元输入的概率描述,直观上更符合自然的认识,同时实验效果要比Relus与ELUs都要好。
GELU也会为inputs乘以0或者1,但不同于以上的或有明确值或随机,GELU所加的0-1mask的值是随机的,同时是依赖于inputs的分布的。可以理解为:GELU的权值取决于当前的输入input有多大的概率大于其余的inputs
因为神经元的输入趋向于正态分布,这么设定使得当输入x减小的时候,输入会有一个更高的概率被dropout掉,这样的激活变换就会随机依赖于输入了。
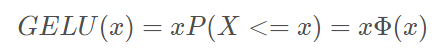
论文也给了一种近似表示: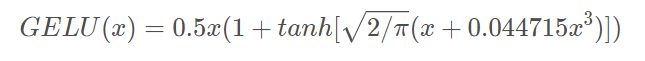
bert源码:
defgelu(input_tensor):
cdf =0.5*(1.0+ tf.erf(input_tensor / tf.sqrt(2.0)))return input_tesnsor*cdf
在transform中确实采用GELU效果会更理想一些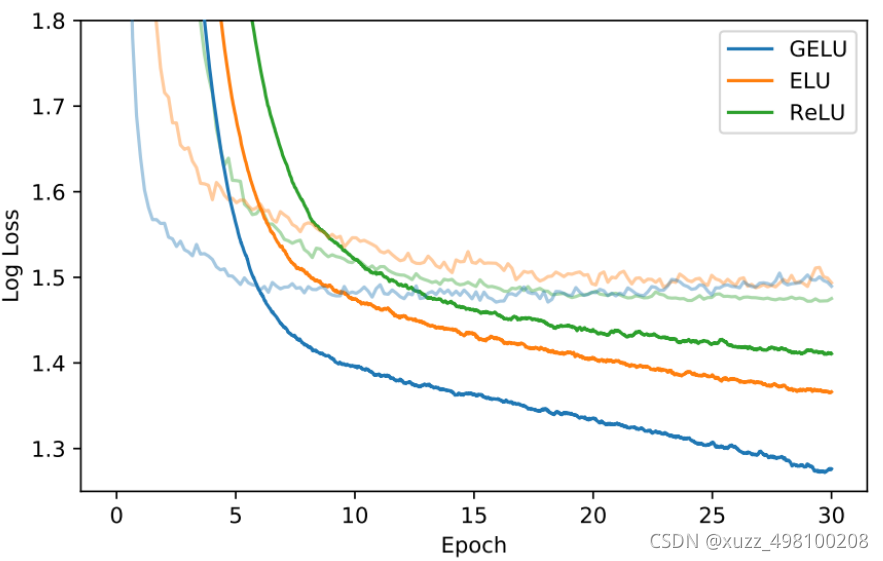
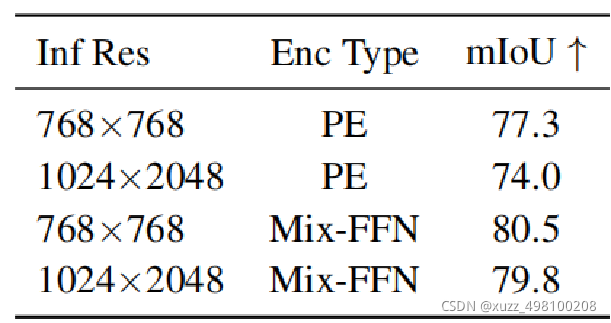
差不多4个点左右的提升
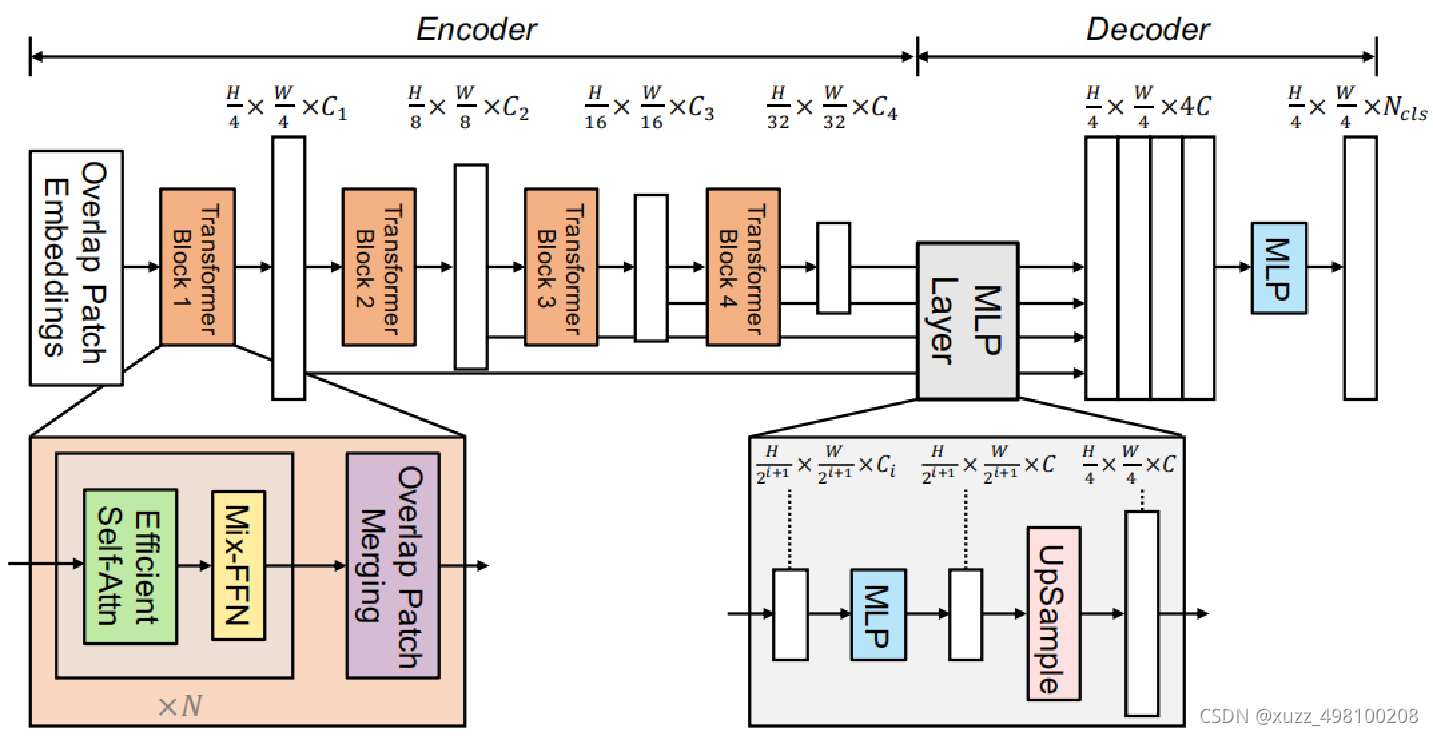
encoder总结: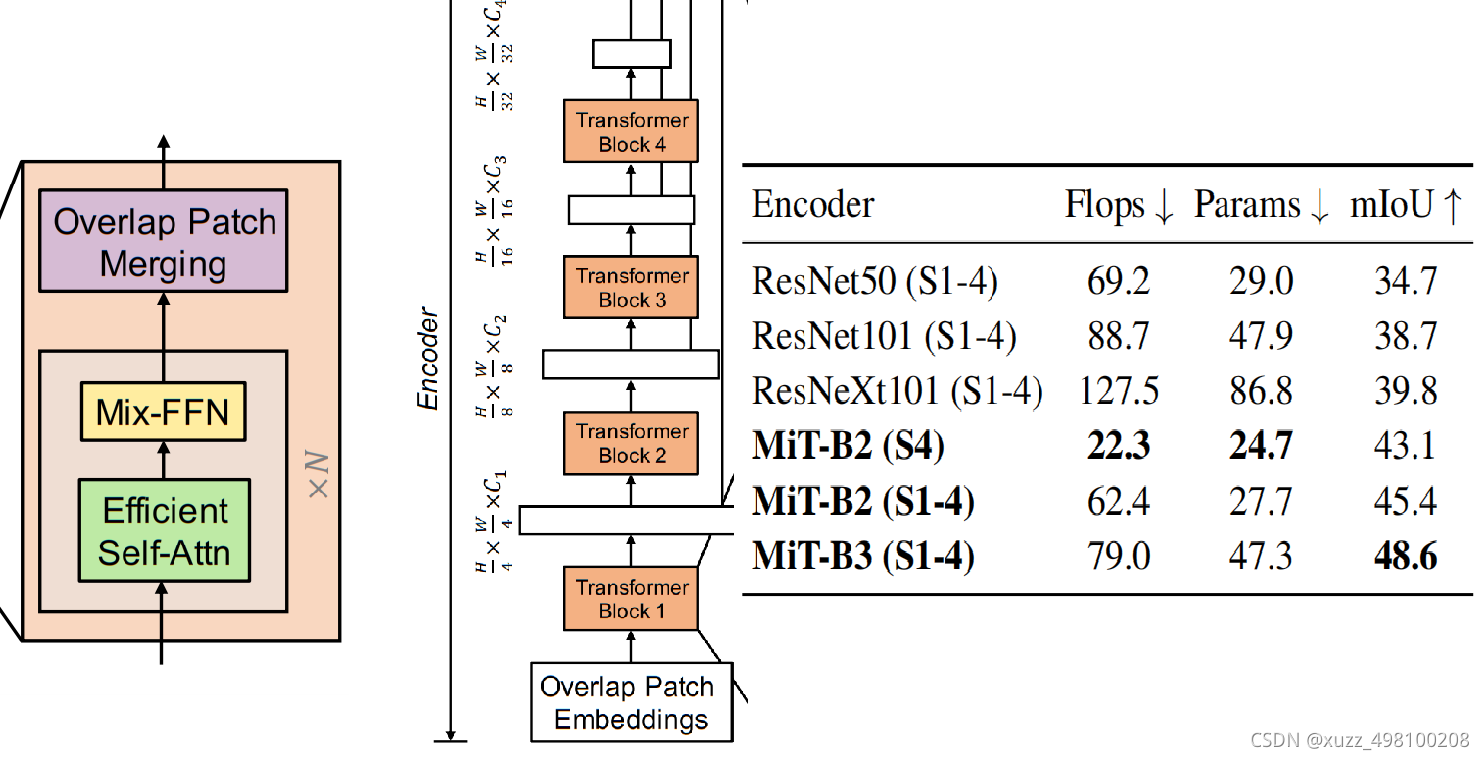
过去三年语义分割从Deeplab系列到PSPNet到DANet等等都是在研究如何设计
更好的decoder(encoder一般通过backbone提取)decoder越来越重越来越复杂
对于语义分割来说最重要的问题就是如何增大感受野,。首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野,比如ASPP里利用了不同大小的空洞卷积来实现这一目的。
但是对于Transformer encoder来说,由于 self-attention存在,有效感受野变得非常大,因此decoder 不需要更多操作来提高感受野(作者试了一堆分割头,基本没有提升),下面是deeplab和segformer有效感受野可视化的对比(有效感受野:
Understanding the Effective Receptive Field in Deep Convolutional Neural Networks)
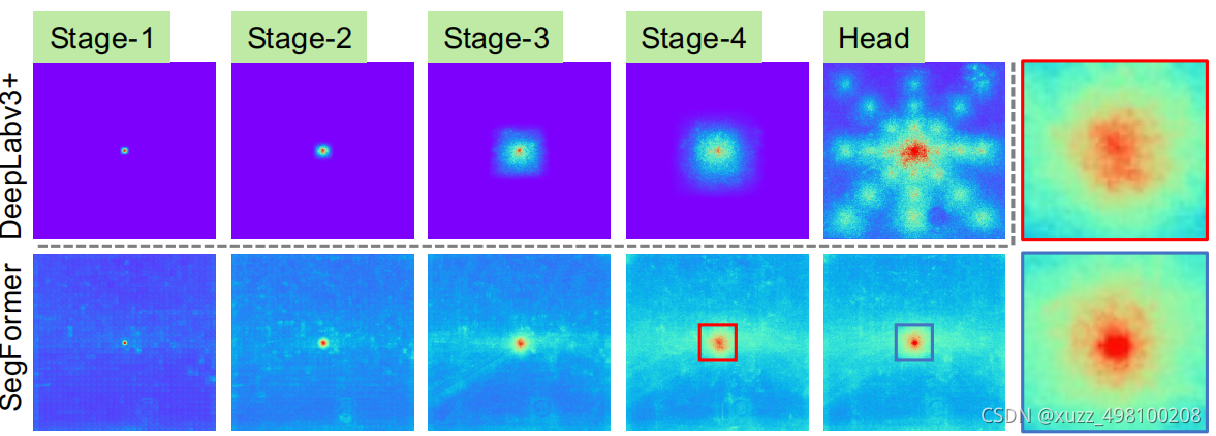
由于自注意力机制的存在,segformer encoder阶段感受野就足够大了
,所以decoder不需要很重的head
首先对不同层的Feature分别过一个linear层确保他们的channel维度一样,其次都上采样到1/4分辨率并concat起来,再用一个linear层融合,最后一个linear层预测结果。整个decoder只有四部分一共6个linear层
没有dilate conv
没有3x3 conv.
所以参数非常少
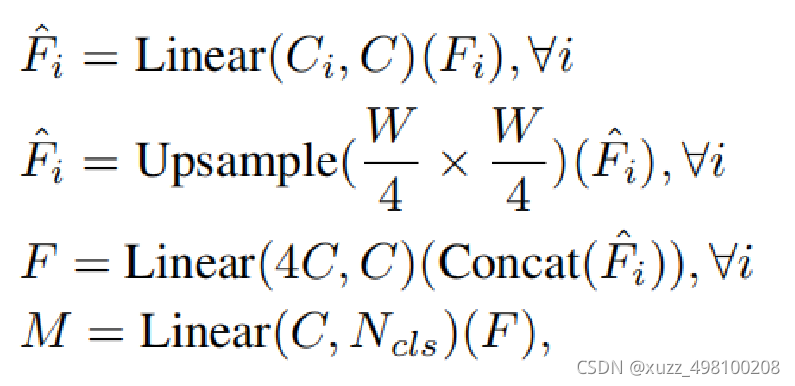
classSegformerHead(BaseDecodeHead):def__init__(self, interpolate_mode='bilinear',**kwargs):super().__init__(input_transform='multiple_select',**kwargs)
self.interpolate_mode = interpolate_mode
num_inputs =len(self.in_channels)assert num_inputs ==len(self.in_index)
self.convs = nn.ModuleList()for i inrange(num_inputs):
self.convs.append(
ConvModule(
in_channels=self.in_channels[i],
out_channels=self.channels,
kernel_size=1,
stride=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
self.fusion_conv = ConvModule(
in_channels=self.channels * num_inputs,
out_channels=self.channels,
kernel_size=1,
norm_cfg=self.norm_cfg)defforward(self, inputs):# Receive 4 stage backbone feature map: 1/4, 1/8, 1/16, 1/32
inputs = self._transform_inputs(inputs)
outs =[]for idx inrange(len(inputs)):
x = inputs[idx]
conv = self.convs[idx]
outs.append(
resize(input=conv(x),
size=inputs[0].shape[2:],
mode=self.interpolate_mode,
align_corners=self.align_corners))
out = self.fusion_conv(torch.cat(outs, dim=1))
out = self.cls_seg(out)return out
上图为Segformer的分割头部分,可以看出整个结构非常简洁
损失函数层面没有改进,依然还是最经典的交叉熵损失函数。
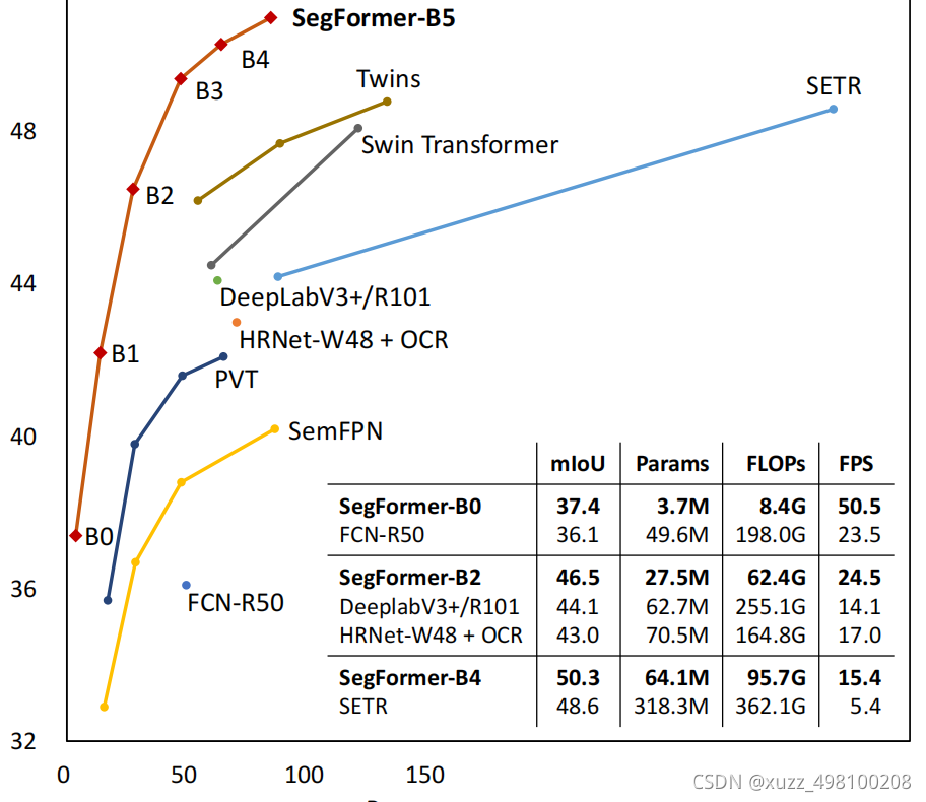
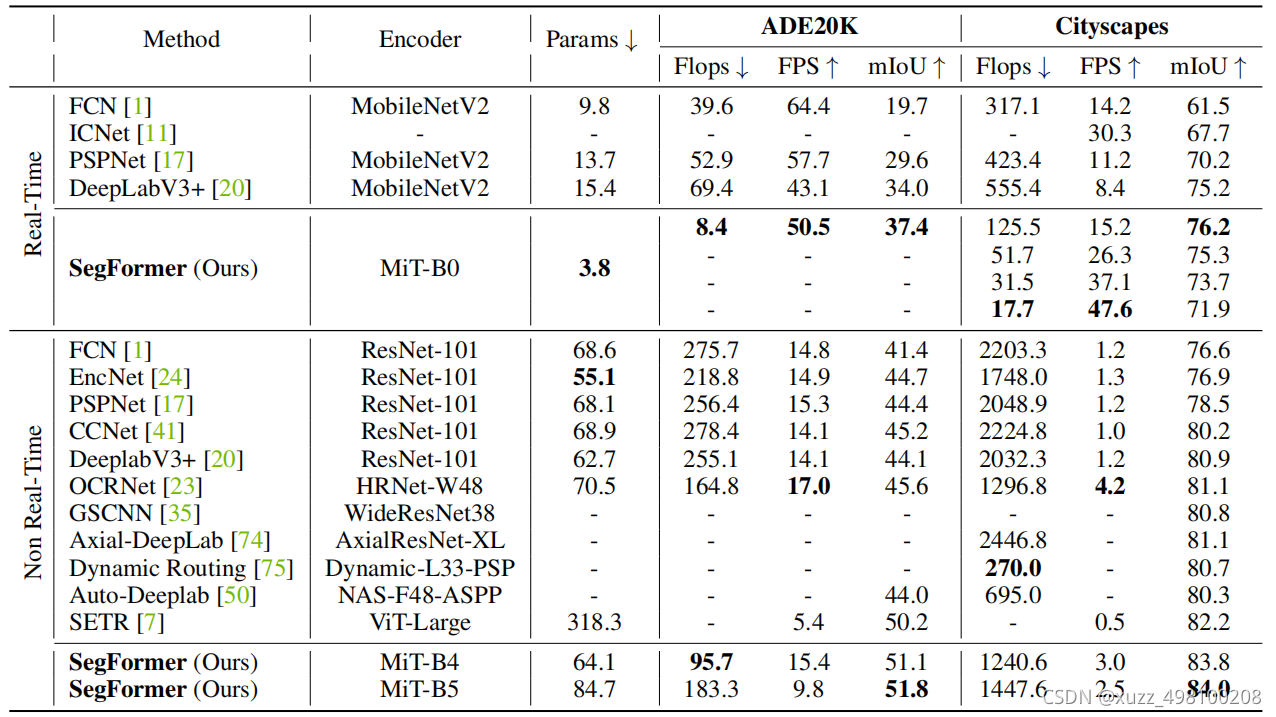
实验结果:
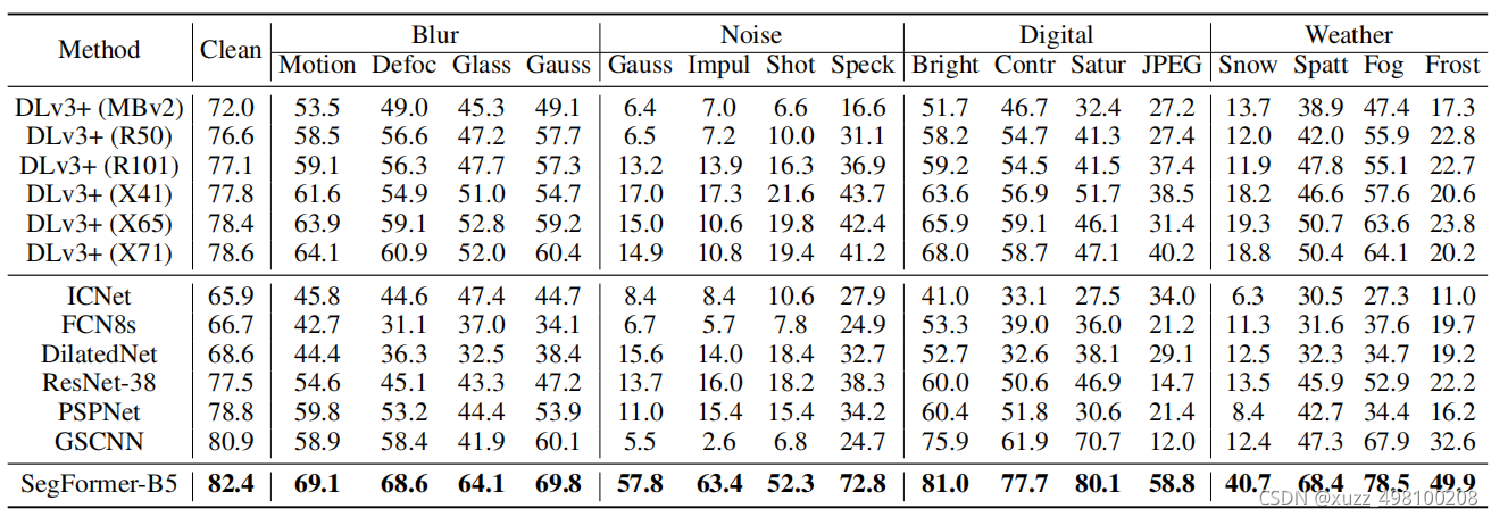
鲁棒性测试:
SegFormer一作的思考:
对于语义分割,特征提取非常重要,Transformer已经在分类上证明了比CNN更强大的特征提取能力。但是分类和分割还是有一定的GAP, 因此如何设计对分割友好的更好的Transformer结构,还可以继续研究。
有了很好的特征,decoder该如何设计才能进一步提高性能。这里用了一个很简单的MLP decoder取得了不错的效果,而传统的ASPP之类的decoder 在Transformer的基础上基本上没有帮助,未来如何针对性的设计更好的decoder也比较值得探索。
关于tf的思考:downsample、position encoding也都开始倾向于用conv了,退化回CNN架构的设计方式(SwinT使用了CNN的local和hierarchical思想)。到最后,Vision Transformer相比于CNN,可能只有local self-attention是有进步意义的。
版权归原作者 xuzz_498100208 所有, 如有侵权,请联系我们删除。