
使用LangGraph从零构建多智能体AI系统:实现智能协作的完整指南
本文将通过构建AI研究助手的完整案例,展示如何使用LangGraph框架实现这种架构转变,从理论基础到具体实现,帮助你掌握下一代AI系统的构建方法。

论文解读:单个标点符号如何欺骗LLM,攻破AI评判系统
本研究深入揭示了现有LLM评判器面临的系统性安全隐患,并提出了有效的防御解决方案。通过Master-RM模型的成功构建,证明了针对性的对抗训练能够在保持模型通用性能的前提下显著提升安全防护能力。
普通电脑也能跑AI:10个8GB内存的小型本地LLM模型推荐
本文将深入分析如何在本地硬件环境中部署先进的AI模型,并详细介绍当前最具代表性的轻量级模型解决方案。
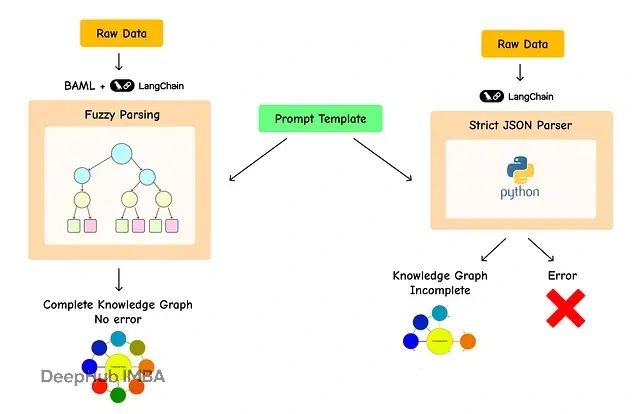
使用 BAML 模糊解析改进 LangChain 知识图谱提取:成功率从25%提升到99%
本文将深入分析小型量化模型在 LangChain 提取任务中的性能限制,并展示 BAML 技术如何将知识图谱提取成功率从约 **25% 显著提升至 99% 以上**。
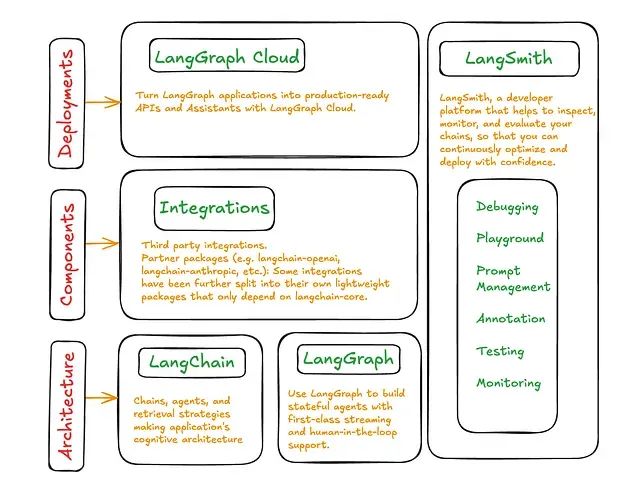
从零开始构建AI Agent评估体系:12种LangSmith评估方法详解
本文将深入探讨十二种不同的智能体评估技术,详细阐述每种技术的适用场景和实施方法。这些技术涵盖了从传统的预测答案与标准答案比较,到先进的实时反馈评估等多个层面,其中标准答案会随时间动态变化。
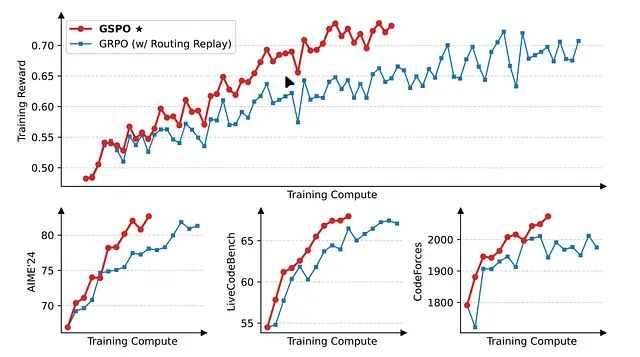
GSPO:Qwen让大模型强化学习训练告别崩溃,解决序列级强化学习中的稳定性问题
这是7月份的一篇论文,Qwen团队提出的群组序列策略优化算法及其在大规模语言模型强化学习训练中的技术突破
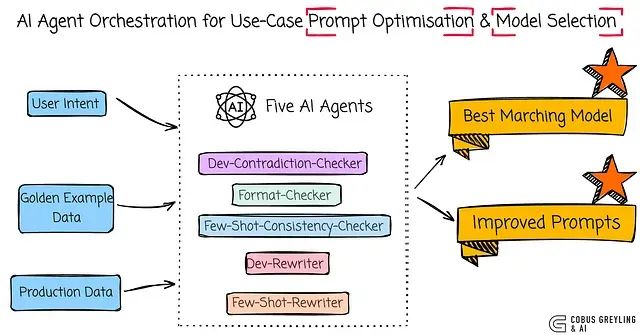
解决提示词痛点:用AI智能体自动检测矛盾、优化格式的完整方案
本文介绍了一个基于用户意图进行提示词优化的项目,该项目能够将预期用途与理想模型进行精确匹配。
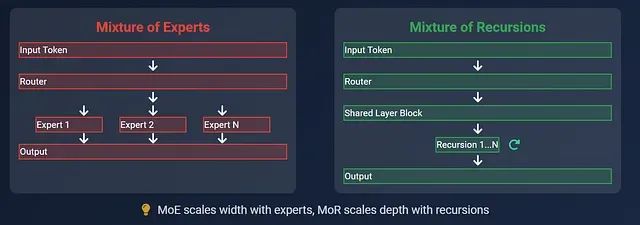
MoR vs MoE架构对比:更少参数、更快推理的大模型新选择
本文将深入分析递归混合(MoR)与专家混合(MoE)两种架构在大语言模型中的技术特性差异,探讨各自的适用场景和实现机制,并从架构设计、参数效率、推理性能等多个维度进行全面对比。
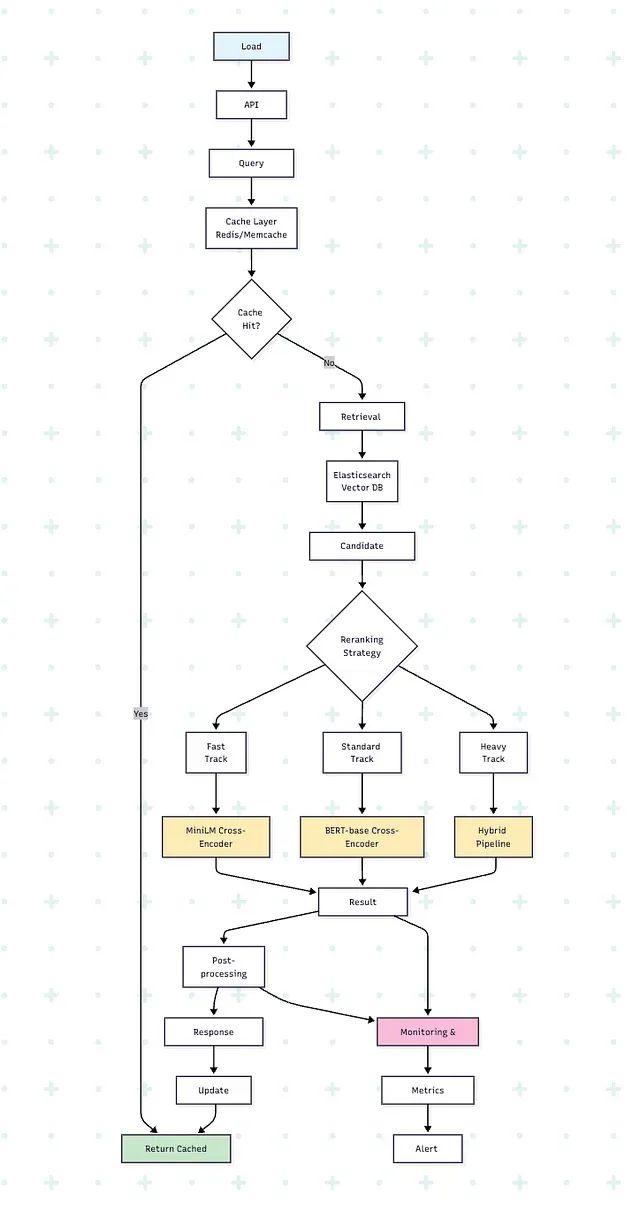
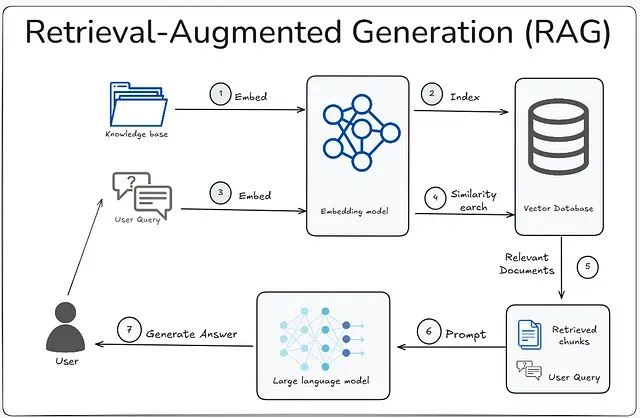
LLM开发者必备:掌握21种分块策略让RAG应用性能翻倍
本文将系统介绍21种文本分块策略,从基础方法到高级技术,并详细分析每种策略的适用场景,以帮助开发者构建更加可靠的RAG系统。
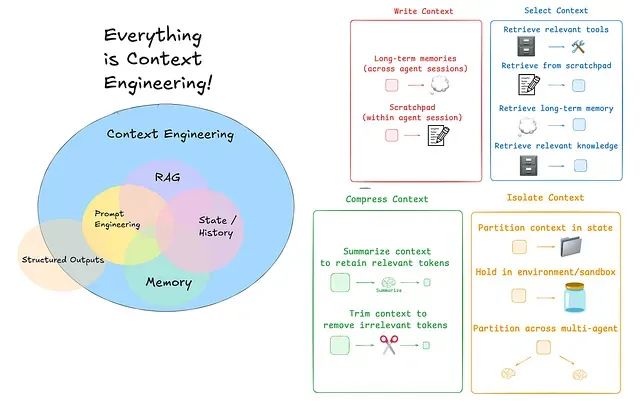
AI代理性能提升实战:LangChain+LangGraph内存管理与上下文优化完整指南
本文将深入探讨如何运用LangChain和LangGraph这两个构建AI代理、RAG应用和LLM应用的核心工具,系统性地实现上下文工程技术,以实现AI代理性能的全面优化。
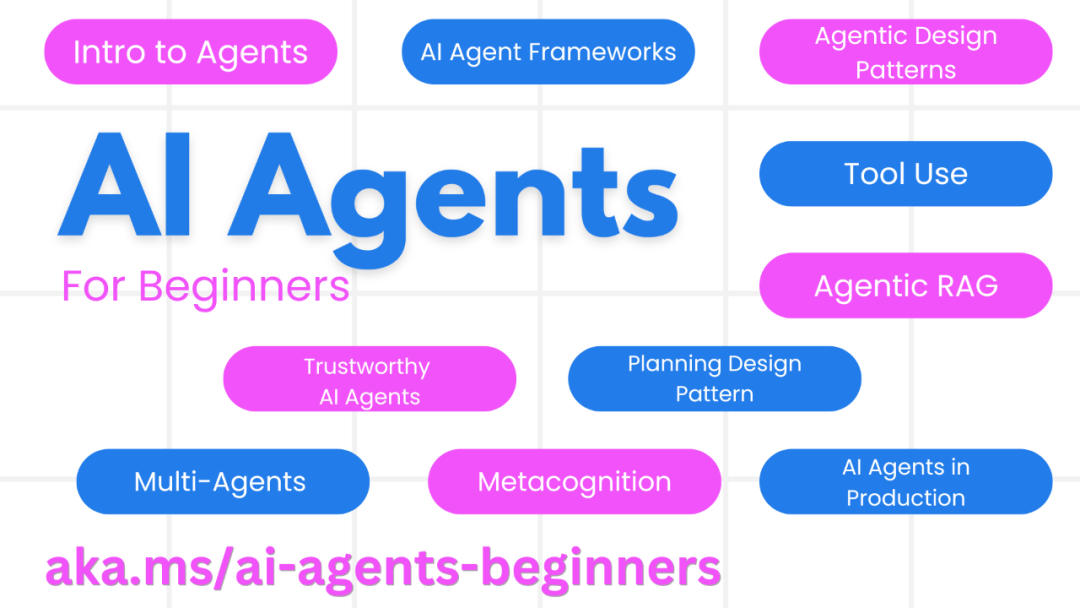
2025年AI智能体开发完全指南:10个GitHub顶级教程资源助你从入门到精通
本文精选了十个高质量的GitHub开源项目,涵盖从基础理论到实践应用的全方位学习路径,为AI开发者提供系统性的技术资源。
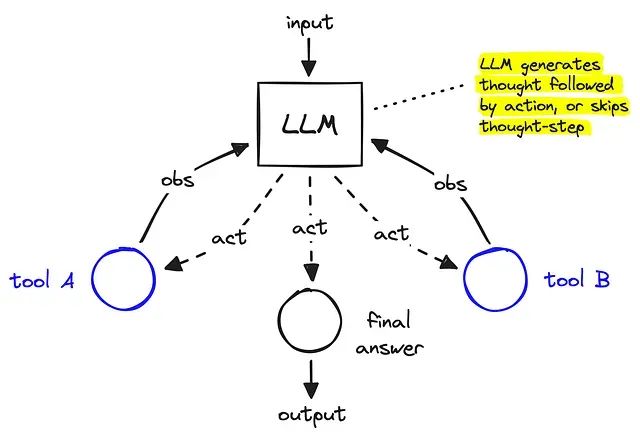
从零构建智能对话助手:LangGraph + ReAct 实现具备记忆功能的 AI 智能体
本文将从理论基础到实践应用,系统性地介绍如何使用 LangGraph 构建具备记忆能力的 ReAct 智能体。
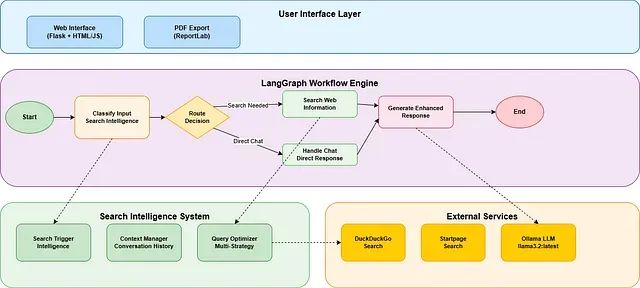
从零搭建智能搜索代理:LangGraph + 实时搜索 + PDF导出完整项目实战
本系统的核心特性包括:基于智能判断机制的自动网络搜索触发、跨多轮对话的上下文状态管理、多策略搜索机制与智能回退、透明的信息源追溯体系,以及专业级PDF文档生成功能。
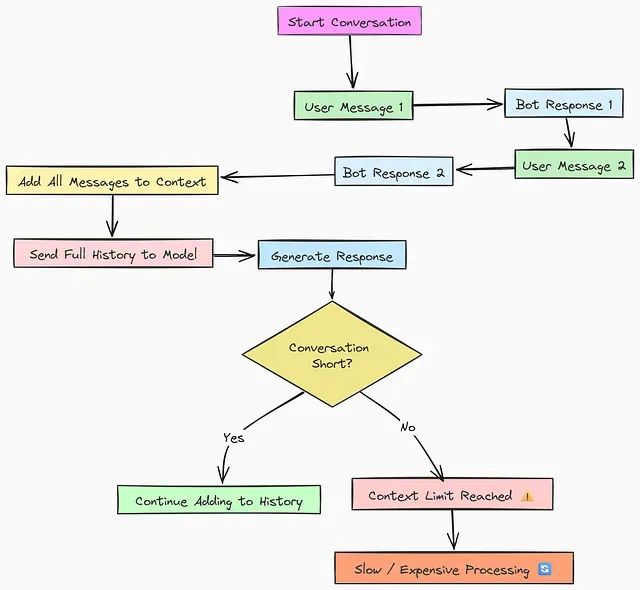
AI代理内存消耗过大?9种优化策略对比分析
本文将深入探讨并实现九种从基础到高级的内存优化技术,涵盖从简单的顺序存储方法到复杂的类操作系统内存管理策略。通过系统性的代码实现和性能评估,我们将分析每种技术的适用场景、优势特点以及潜在限制。
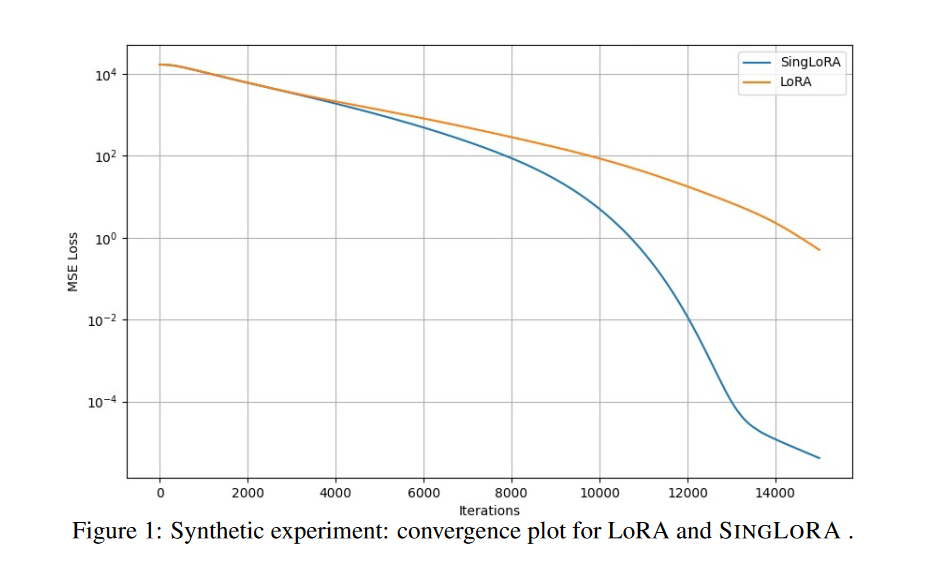
SingLoRA:单矩阵架构减半参数量,让大模型微调更稳定高效
SingLoRA作为一种创新的低秩适应方法,通过摒弃传统的双矩阵架构,采用单矩阵对称更新策略,在简化模型结构的同时显著提升了训练稳定性和参数效率。
让大语言模型在不知道答案时拒绝回答:KnowOrNot框架防止AI幻觉
KnowOrNot开源框架通过创建可保证的"知识库外"测试场景,评估AI系统是否能够正确识别其知识边界并在信息不足时采取适当的拒绝回答策略。
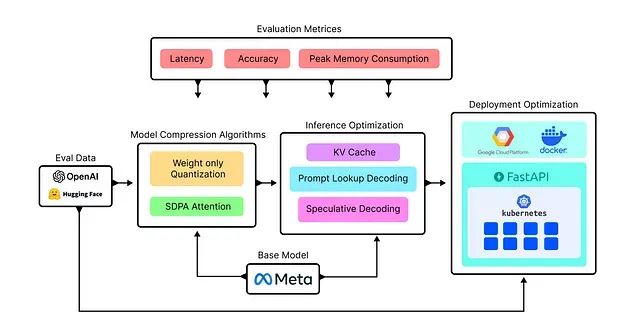
构建高性能LLM推理服务的完整方案:单GPU处理172个查询/秒、10万并发仅需15美元/小时
本文将通过系统性实验不同的优化技术来构建自定义LLaMA模型服务,目标是高效处理约102,000个并行查询请求,并通过对比分析确定最优解决方案。
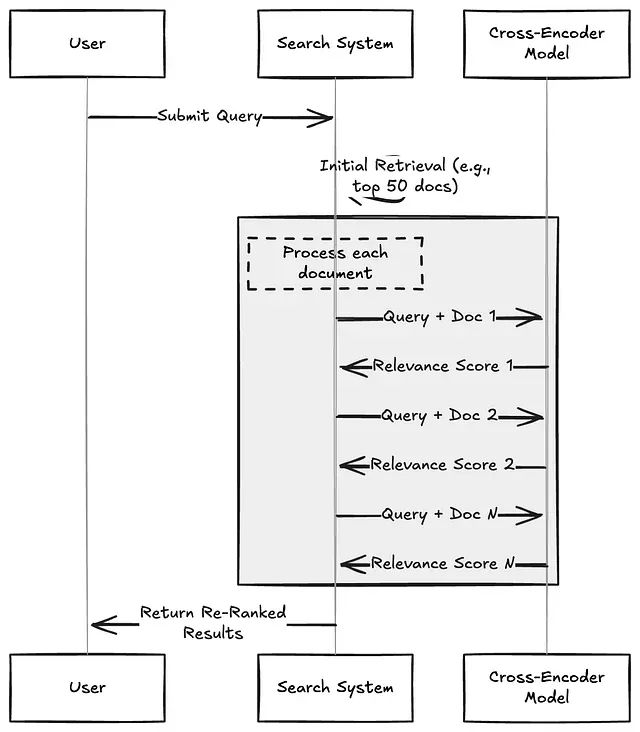
信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。



