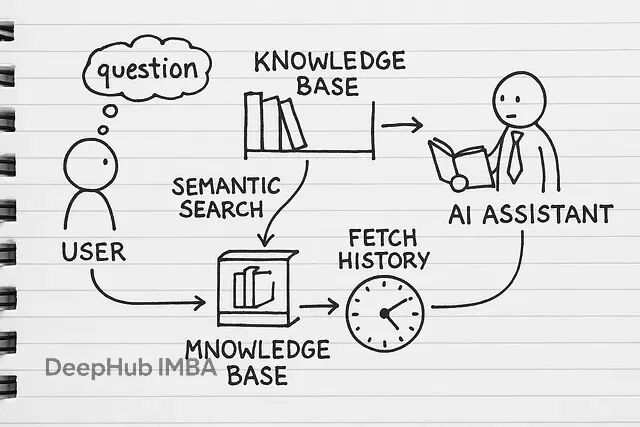
从零搭建RAG应用:跳过LangChain,掌握文本分块、向量检索、指代消解等核心技术实现
RAG(检索增强生成)本质上就是给AI模型外挂一个知识库。平常用ChatGPT只能基于训练数据回答问题,但RAG可以让它查阅你的专有文档——不管是内部报告、技术文档还是业务资料,都能成为AI的参考资源。
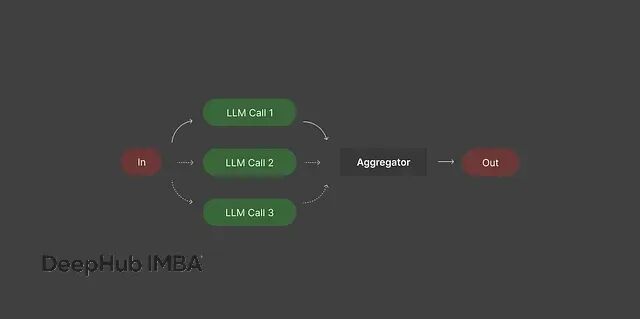
AI Agent工作流实用手册:5种常见模式的实现与应用,助力生产环境稳定性
掌握这些工作流模式,你就能充分发挥AI的潜力,稳定地获得高质量结果。
解决推理能力瓶颈,用因果推理提升LLM智能决策
本文提出通过在LLM训练中集成因果AI来增强推理能力,并在推理阶段引入内省机制改进ReAct框架。这种方法能够显著提升智能体在复杂任务中的决策准确性和可解释性,为构建更可靠的AI智能体系统提供了技术路径。
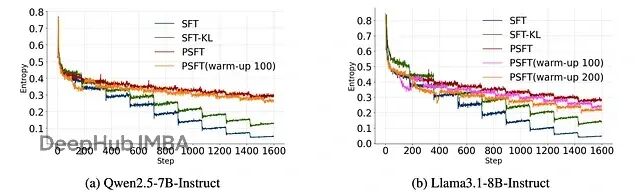
Proximal SFT:用PPO强化学习机制优化SFT,让大模型训练更稳定
这篇论文提出了 Proximal Supervised Fine-Tuning (PSFT),本质上是把 PPO 的思路引入到 SFT 中。这个想法挺巧妙的:既然 PPO 能够稳定策略更新,那为什么不用类似的机制来稳定监督学习的参数更新呢?
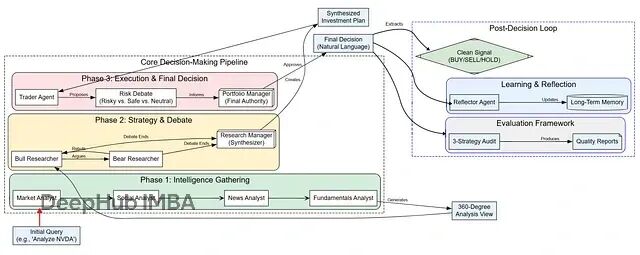
LangGraph实战:从零构建智能交易机器人,让多个AI智能体像投资团队一样协作
这个基于LangGraph的多智能体量化交易系统代表了AI在金融决策领域的一个重要进展本文展示的完整实现代码已经为读者提供了一个可运行的起点。
微软rStar2-Agent:新的GRPO-RoC算法让14B模型在复杂推理时超越了前沿大模型
Microsoft Research最近发布的rStar2-Agent展示了一个令人瞩目的结果:一个仅有14B参数的模型在AIME24数学基准测试上达到了80.6%的准确率,超越了671B参数的DeepSeek-R1(79.8%)。
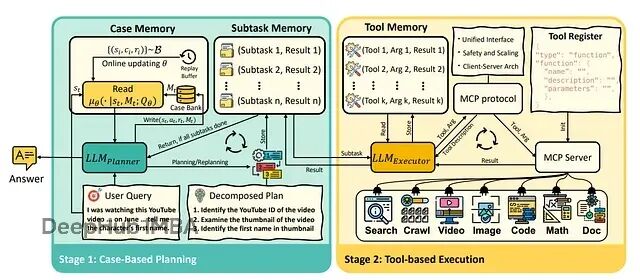
Memento:基于记忆无需微调即可让大语言模型智能体持续学习的框架
Memento框架通过基于记忆的在线强化学习实现低成本持续适应,完全避免了对LLM的微调需求。
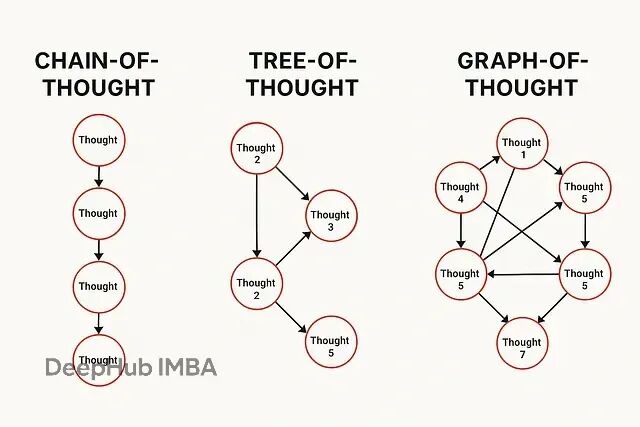
AI推理方法演进:CoT、ToT与GoT技术对比分析
从CoT到GoT的演进轨迹展现了AI推理范式的根本性变革:从单一路径的顺序推理转向多维度的并行思维模拟。这一进程标志着大语言模型研究重心从参数规模竞争转向认知机制建模。
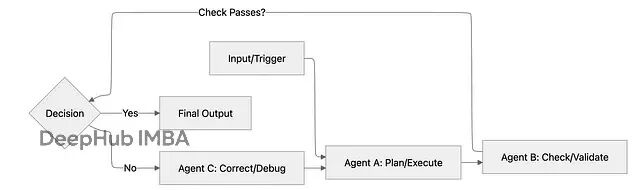
多智能体系统设计:5种编排模式解决复杂AI任务
我们这里分析5种主流的智能体编排模式,每种都有其适用场景和技术特点。

神经架构搜索NAS详解:三种核心算法原理与Python实战代码
最近好多论文开始将 **神经架构搜索(NAS)** 应用于**大模型**或 **大型语言/视觉语言模型**的设计中。所以我来回顾一下NAS的基础技术。
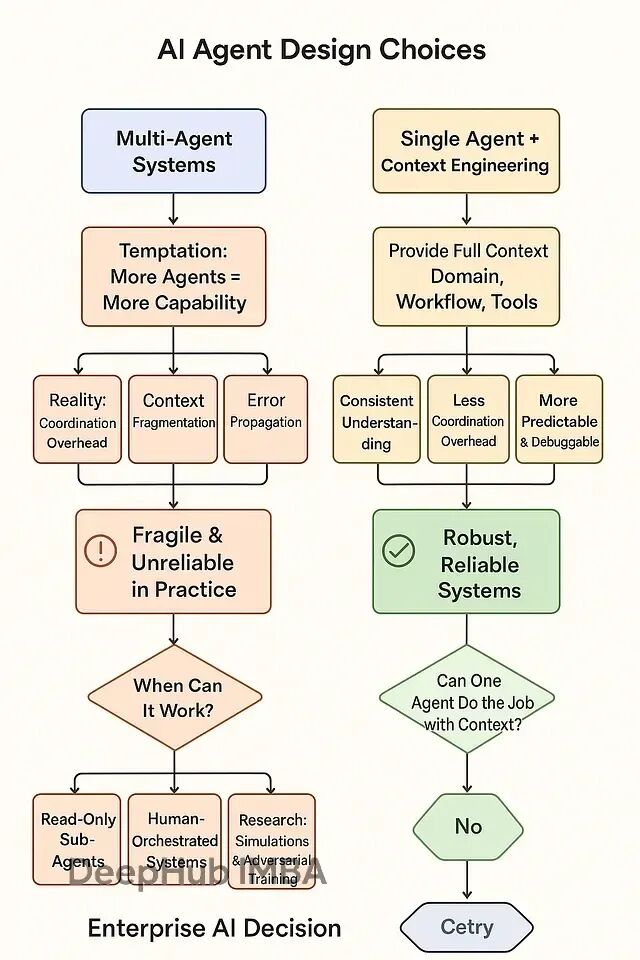
多智能体协作为什么这么难:系统频繁失败的原因分析与解决思路
在AI系统设计初期,将智能体数量与系统能力划等号是一种直观但错误的思维模式。但是根据AI研究领域的实证结果,这种多智能体分工模式在实际应用中暴露出严重的系统性缺陷。多智能体系统的根本性问题在于协调机制的复杂性往往超过其带来的功能收益

NVFP4量化技术深度解析:4位精度下实现2.3倍推理加速
本文将从技术角度深入分析NVFP4与主流4位量化方法(AWQ、AutoRound、bitsandbytes)的性能对比,并探讨在Blackwell GPU环境下采用NVFP4方案的实际价值。
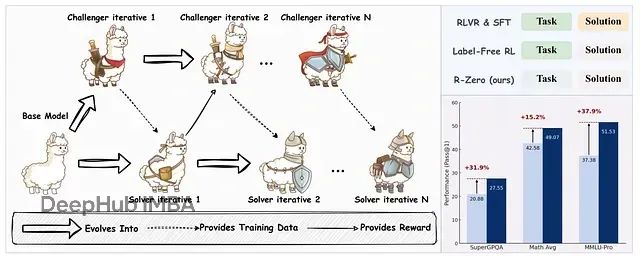
R-Zero:通过自博弈机制让大语言模型无需外部数据实现自我进化训练
R-Zero框架实现了大语言模型在无外部训练数据条件下的自主进化与推理能力提升。

HiRAG:用分层知识图解决复杂推理问题
该系统基于图检索增强生成(GraphRAG)的核心思想,通过引入层次化架构来处理不同抽象层次的知识复杂度。
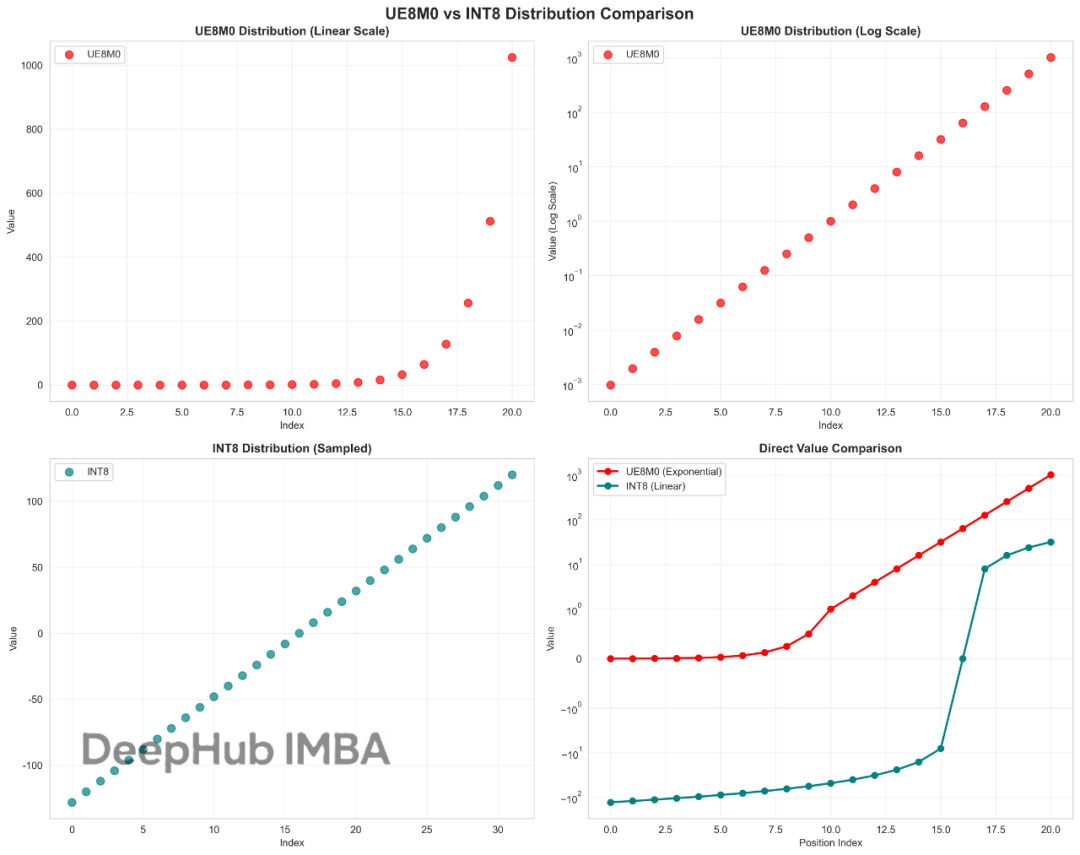
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析
UE8M0作为FP8格式家族中的一个特殊变体,我们今天来看看这个UE8M0到底是什么。
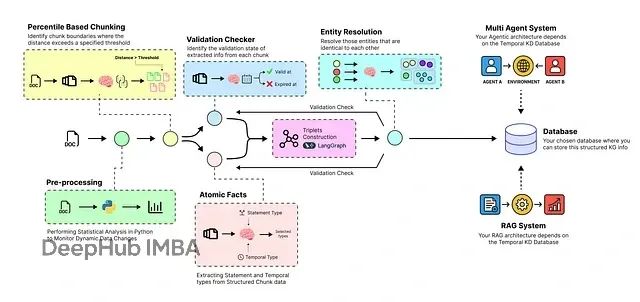
构建时序感知的智能RAG系统:让AI自动处理动态数据并实时更新知识库
本文将构建一个端到端的时序智能体管道,实现从原始数据到动态知识库的转换,并在此基础上构建多智能体系统以验证其性能表现。

AMD Ryzen AI Max+ 395四机并联:大语言模型集群推理深度测试
本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。
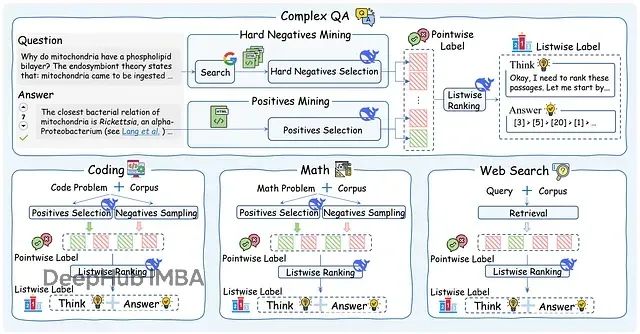
ReasonRank:从关键词匹配到逻辑推理,排序准确性大幅超越传统方法
本文深入分析ReasonRank,一个采用自动化数据合成框架和两阶段训练策略(监督微调+强化学习)的先进段落重排器,该系统在信息检索领域实现了突破性的推理能力
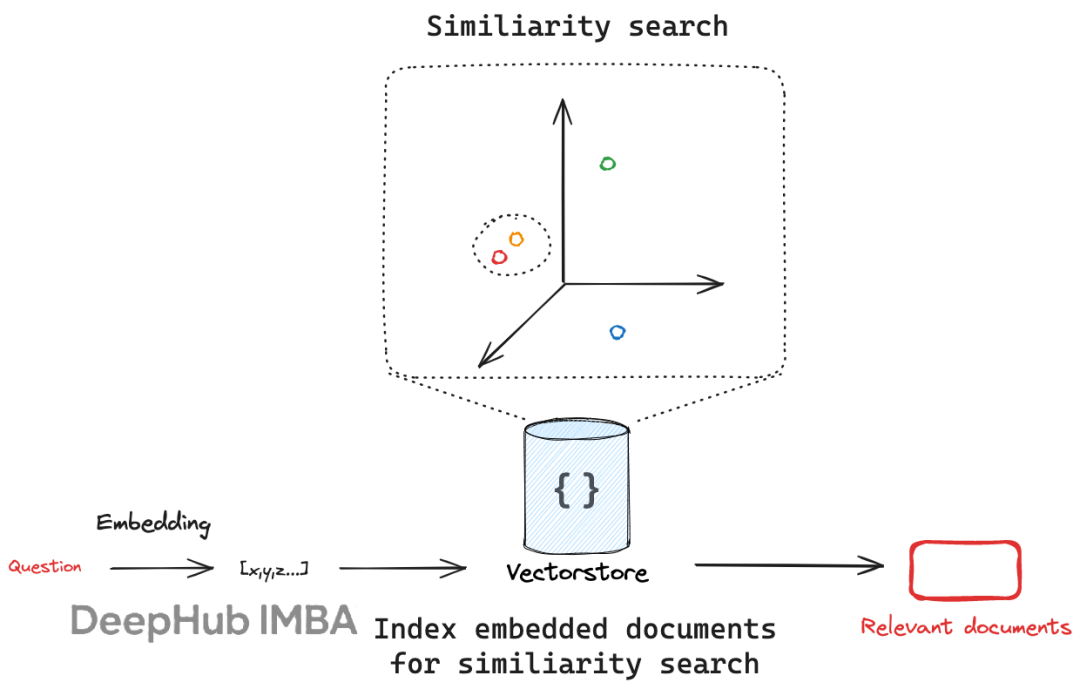
提升LangChain开发效率:10个被忽视的高效组件,让AI应用性能翻倍
本文将系统分析LangChain框架中十个具有重要价值但使用率相对较低的核心组件,通过技术原理解析和实践案例说明,帮助开发者构建更高效、更智能、更具适应性的AI应用系统。
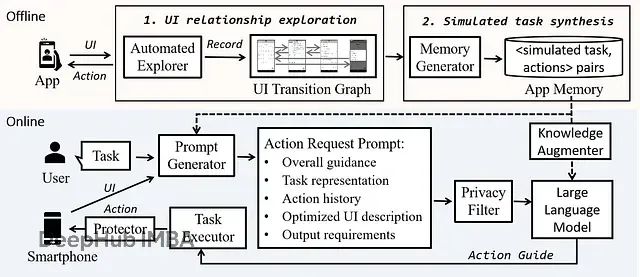
大型动作模型LAM:让企业重复任务实现80%效率提升的AI技术架构与实现方案
本文将深度剖析LAMs的技术架构,详细阐述其核心组件的设计原理、功能实现机制以及在实际业务场景中的应用模式



