
在当今海量数据时代,有效的信息检索(IR)技术对于从庞大数据集中提取相关信息至关重要。近年来,密集检索技术展现出了相比传统稀疏检索方法更加显著的效果。
现有的方法主要从点式重排序器中蒸馏知识,这些重排序器为文档分配绝对相关性分数,因此在进行比较时面临不一致性的挑战。为解决这一问题,来自国立台湾大学的研究者Chao-Wei Huang和Yun-Nung Chen提出了一种新颖的方法——成对相关性蒸馏(Pairwise Relevance Distillation, PAIRDISTILL)。
PAIRDISTILL的主要研究目的是:
- 利用成对重排序的优势,为密集检索模型的训练提供更细粒度的区分。
- 提高密集检索模型在各种基准测试中的性能,包括领域内和领域外的评估。
- 探索一种可以跨不同架构和领域进行一致性改进的方法。
方法改进详细描述
PAIRDISTILL方法的核心思想是利用成对重排序器提供的细粒度训练信号来增强密集检索模型的训练。该方法的主要组成部分包括:
成对重排序:与传统的点式重排序不同,成对重排序同时比较两个文档,估计一个文档相对于另一个文档与查询的相关性。形式上,给定查询q和两个文档di和dj,成对重排序器估计的概率为:
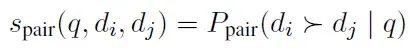
这种方法通过仅建模di和dj的相对相关性来缓解校准问题。
成对相关性蒸馏:PAIRDISTILL的目标是让密集检索器模仿成对重排序器的输出分布。密集检索器预测的成对相关性分布定义为:
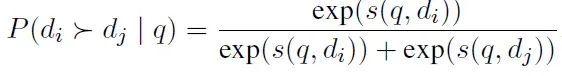
训练目标是最小化密集检索器和成对重排序器的成对相关性分布之间的KL散度:
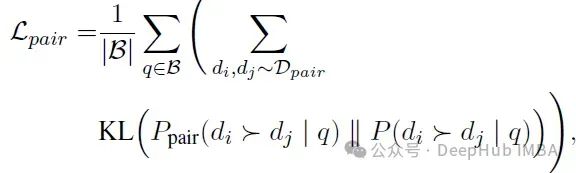
迭代训练策略:为了提高检索器的性能并避免过拟合固定的文档集,PAIRDISTILL采用了迭代训练策略。每次迭代中,使用前一次迭代训练的检索器构建索引并检索前k个文档,然后进行重排序和微调。
综合损失函数:PAIRDISTILL的完整损失函数包括对比学习损失、点式知识蒸馏损失和成对相关性蒸馏损失:
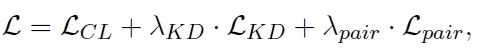
其中λKD和λpair是表示蒸馏损失权重的超参数。
下图2展示了PAIRDISTILL方法的整体框架:
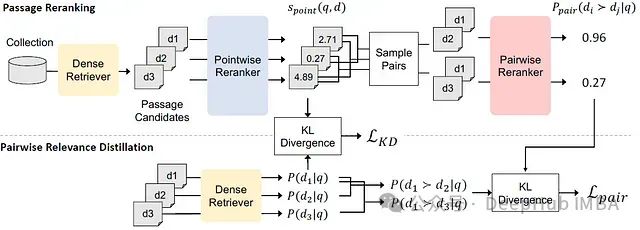
(图2:PAIRDISTILL方法框架示意图)
这种方法不仅可以应用于有监督的数据集,还可以用于零样本域适应任务。在没有标记训练数据的情况下,可以使用以下简化的损失函数:
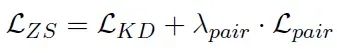
通过这种创新的方法,PAIRDISTILL能够从成对比较中蒸馏知识,使模型学习到更细致的文档相关性区分,从而提高密集检索模型的整体性能。
实验设置
研究者进行了广泛的实验来验证PAIRDISTILL方法的有效性。主要的实验设置如下:
- 数据集:- MS MARCO:用作监督数据集,包含502K训练查询和8.8百万段落。- TREC DL19和DL20:用于额外的领域内评估。- BEIR:包含18个检索数据集,用于评估领域外检索性能。- LoTTE:包含来自StackExchange的问题和答案,涵盖多个主题。
- 评估指标:- MS MARCO:使用MRR@10和Recall@1000- TREC和BEIR:使用NDCG@10- LoTTE:使用Success@5
- 模型实现:- 初始检索器:采用预训练的ColBERTv2- 点式重排序器:使用MiniLM- 成对重排序器:采用duoT5-3B
- 训练细节:- 每个查询检索top-100段落- 对每个查询采样50对段落进行成对重排序- 使用4个V100 GPU进行训练
主要实验结果
PAIRDISTILL在多个基准测试中都取得了显著的性能提升。主要结果如下:
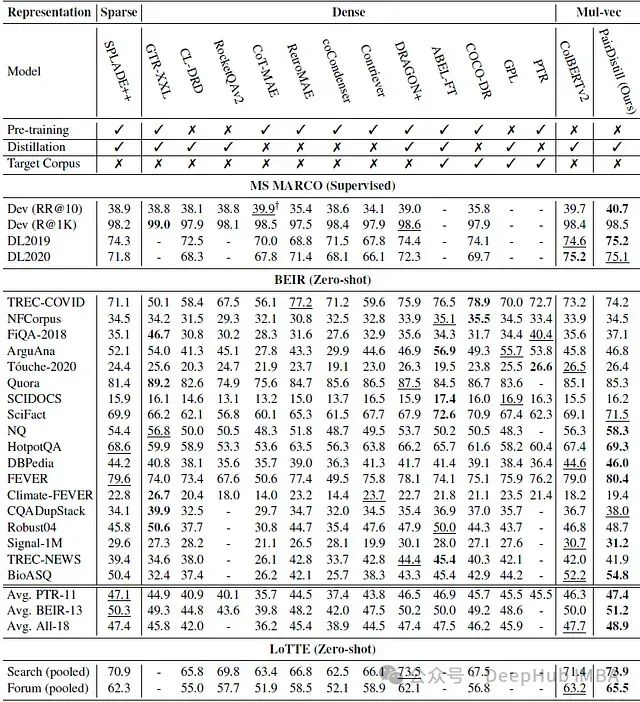
- 领域内评估:在MS MARCO开发集上,PAIRDISTILL达到了40.7的MRR@10,优于所有基线模型,包括其初始化模型ColBERTv2(39.7)。在TREC DL19上也达到了最佳性能,在TREC DL20上达到了第二佳性能。
- 领域外评估:- BEIR数据集:PAIRDISTILL在18个任务中的6个达到了最佳性能,在16个数据集上持续优于ColBERTv2。- LoTTE数据集:在搜索和论坛子集中都达到了最先进的性能。
- 开放域问答:在NaturalQuestions、TriviaQA和SQuAD数据集上,PAIRDISTILL在Recall@5指标上持续优于所有基线模型。
性能改进分析
为了深入理解PAIRDISTILL的性能改进,研究者进行了一系列消融实验和分析:
- 消融研究:- 移除成对蒸馏损失(Lpair)会导致性能下降到39.7。- 移除点式蒸馏损失(LKD)会进一步降低性能至39.4。- 这表明两种蒸馏损失都对模型性能有重要贡献。
- 不同初始化:使用bert-base-uncased初始化时,PAIRDISTILL仍能达到40.3的性能,证明该方法对初始化不敏感。
- 跨架构有效性:在DPR架构上的实验显示,PAIRDISTILL也能持续提升性能,从34.8提升到36.8,证明该方法可以跨不同的密集检索架构有效应用。
- 迭代训练效果:实验表明,第二次迭代可以进一步提升性能,之后趋于收敛。
- 零样本域适应:在FiQA、BioASQ和Climate-FEVER数据集上的实验显示,PAIRDISTILL在零样本域适应任务中也能有效提升性能。
结论与影响
PAIRDISTILL方法通过利用成对重排序器提供的细粒度训练信号,显著提升了密集检索模型的性能。该方法在多个基准测试中都达到了最先进的水平,不仅在领域内评估中表现出色,在领域外和零样本场景中也展现了强大的泛化能力。
这项研究为密集检索领域提供了新的研究方向,展示了利用更细粒度的相关性信息来改进检索模型的潜力。PAIRDISTILL方法的成功也为其他自然语言处理任务中的知识蒸馏技术提供了启发。
尽管如此,研究者也指出了该方法的一些局限性,主要是在训练过程中可能需要更多的训练对,这可能会增加计算资源的需求。未来的研究方向可能包括如何在保持性能的同时减少所需的训练对数量,以及进一步探索该方法在其他相关任务中的应用。
论文:https://arxiv.org/abs/2410.01383
代码:https://github.com/MiuLab/PairDistill
喜欢就关注一下吧: