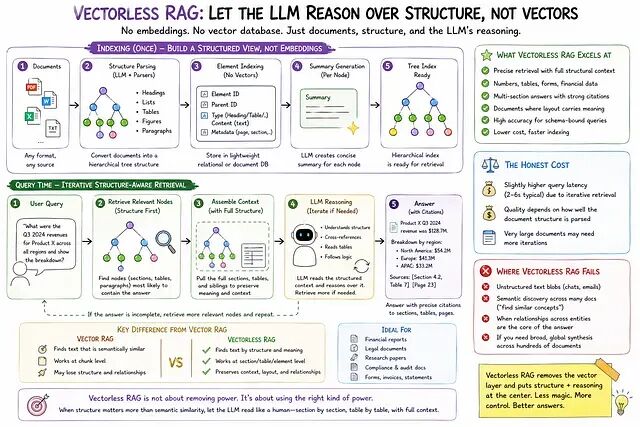
2026 RAG 选型指南:Vector、Graph、Vectorless 该怎么挑
这篇文章将介绍它们之间的差异,让你不必花三周读论文也能为自己的系统做出正确选择。
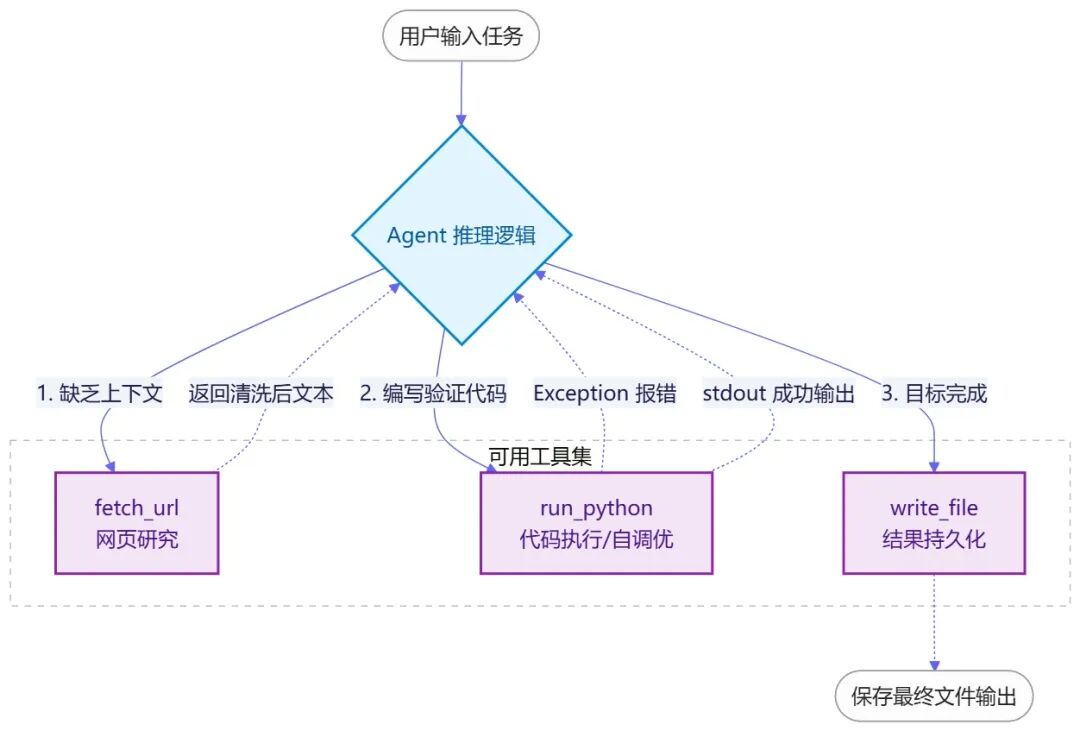
三个工具,让 agent 在一次对话里完成研究、写码、调试与保存
其实只要有三个工具就能把 agent 从聊天机器人变成能干活的东西
用 Playwright 和 LLM 实现自愈测试自动化
Playwright 是一个用于 Web 自动化和端到端测试的开源框架。
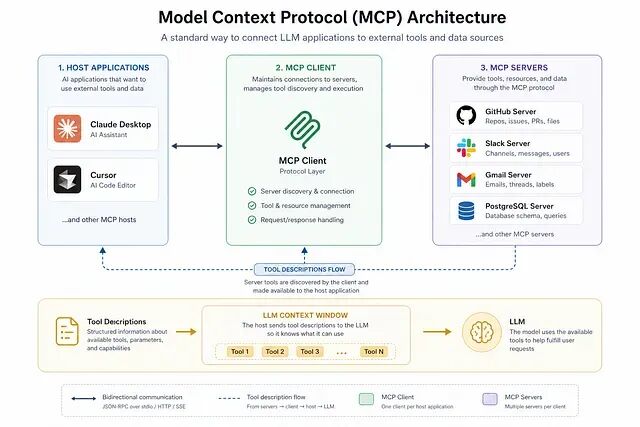
为什么 MCP 在协议层会有 prompt injection的问题:工具描述如何劫持 agent 上下文
MCP(Model Context Protocol)当初被设计成 AI agent 的通用集成层,但它的架构有一个根本缺陷:
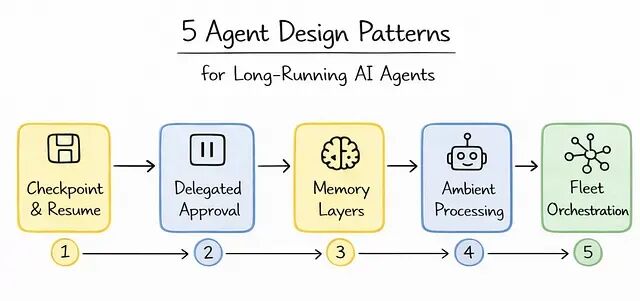
从无状态到有状态:长时运行 Agent 的 5 种架构模式
生产级 AI 不是单轮里把 agent 调得多聪明,而是看它能否在很多轮、很多天、很多次交接之间保持可靠。
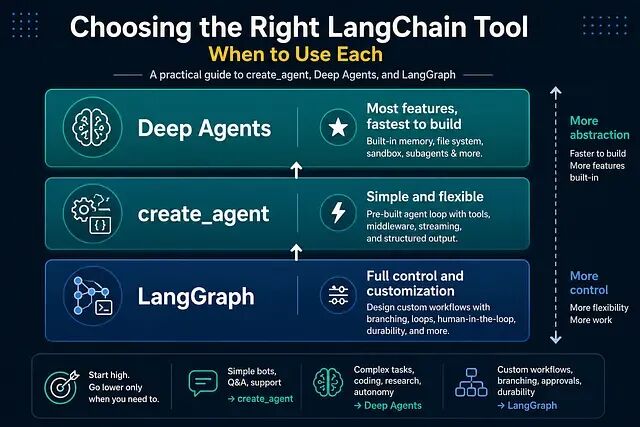
LangChain 生态里的三层抽象:LangGraph、create_agent、Deep Agents
把它们看作不同抽象层级的工具更容易理解。LangGraph 在最底层,所有控制都掌握在开发者手里;
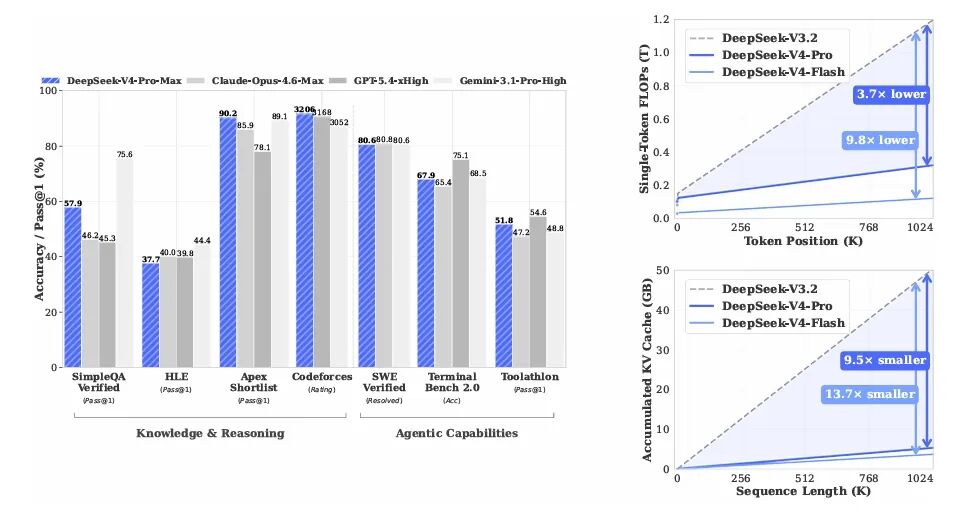
DeepSeek-V4 深度解读:百万上下文背后的工程细节
本文围绕三个问题:长上下文效率到底怎么破(架构);万亿 MoE 怎么稳定训练(基础设施 + trick);十几个领域专家如何合并成一个模型(后训练)。
Graphify:为代码库构建知识图谱,以图遍历替代向量检索
Graphify 是一个 Python 工具,同时也是一个 Claude Code skill。它把分析工作一次性做完,把所有内容压缩成一张可查询的知识图谱,放到磁盘上。
2026年的 ReAct Agent架构解析:原生 Tool Calling 与 LangGraph 状态机
本文要做的是一个 Research Brief Agent:会上网搜索、抓取真实 URL、压缩证据,最终产出一份带真实引用的结构化简报。
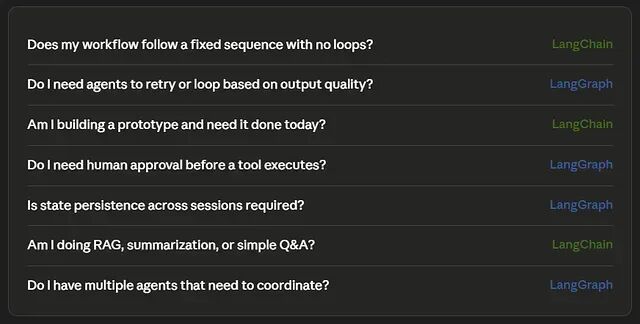
LangChain 还是 LangGraph?一个是编排一个是工具包
现在介绍LangGraph 和 LangChain 的文章。每一篇的结论都差不多:简单流程用 LangChain,复杂的用 LangGraph。

LLM 幻觉的架构级修复:推理参数、RAG、受约束解码与生成后验证
大型语言模型可以写代码、起草合同、总结论文,但它有一个致命缺陷:撒谎的时候极其自信。
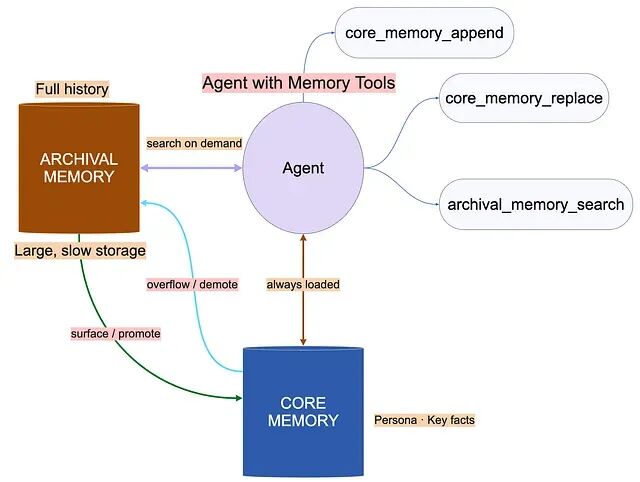
为生产级 AI Agent 构建持久化记忆:五阶段流水线与四种设计模式
不是每个 Agent 都需要这一套。如果你的 Agent 只处理单轮事务或无状态查询,这就是过度工程。记忆不是一项特性,它是 Agent 身份、连续性与信任的根基。
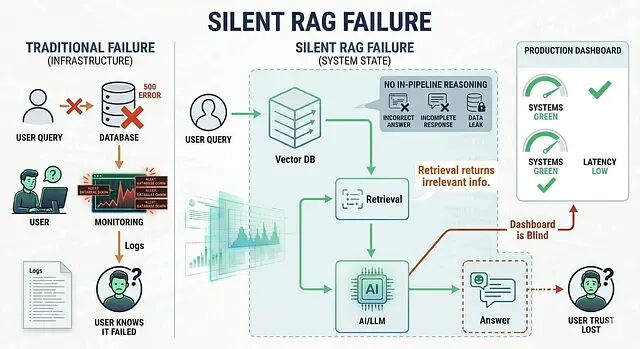
从检索到回答:RAG 流水线中三个被忽视的故障点
RAG 的搭建门槛不高,但要让一个 RAG 系统在生产环境中达到可信赖的程度,所需时间远不止于此。
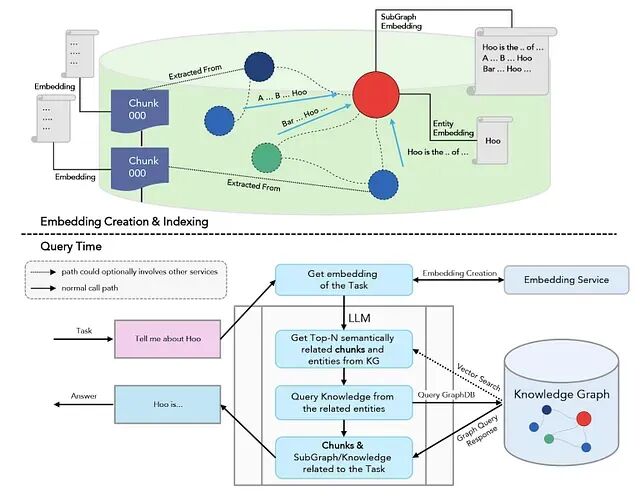
Karpathy的LLM Wiki:一种将RAG从解释器模式升级为编译器模式的架构
Karpathy没有发明新技术,他在清晰阐述一个工作流模式,让LLM天生擅长的事——快速阅读、综合、交叉引用、一致地遵循约定——去接替人类一直需要但从未能持续做好的工作。
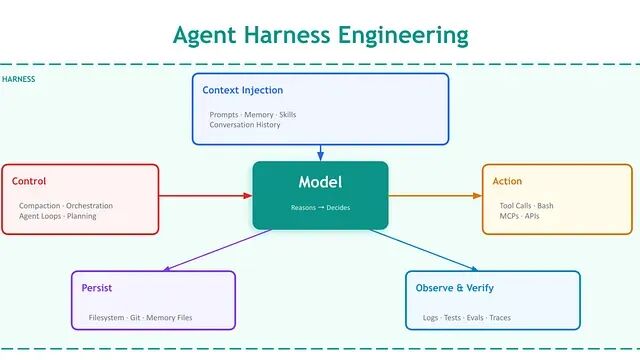
Prompt、Context、Harness:AI Agent 工程的三层架构解析
三者不是竞争关系而是分层。Prompt 关注如何表达任务;Context 关注模型在执行任务时看到什么;Harness 关注模型运行其中的系统。
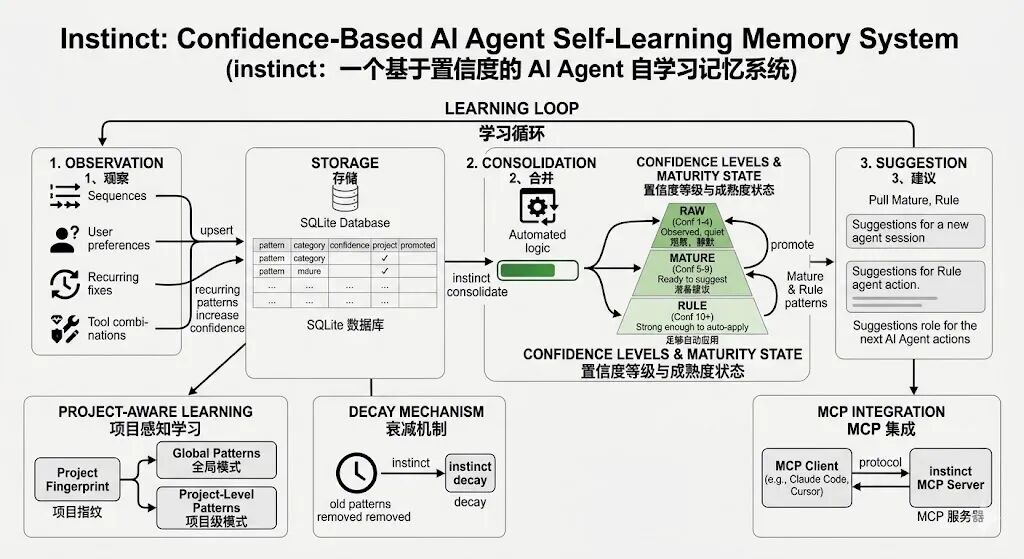
instinct:一个基于置信度的 AI Agent 自学习记忆系统
记忆应当是 Agent 在反复实践中习得的,而非人工分配的。

ADK 多智能体编排:SequentialAgent、ParallelAgent 与 LoopAgent 解析
本文讲介绍每种模式的适用场景、状态的流转机制,以及如何在不编写编排逻辑的前提下搭建一条完整的从订单到交付的流水线。
从零构建 Mini-vLLM:KV-Cache、动态批处理与分布式推理全流程
Mini-vLLM是一个从零开始写的推理引擎,我们的目标不是为了造轮子,而是要知道轮子是如何工作的。
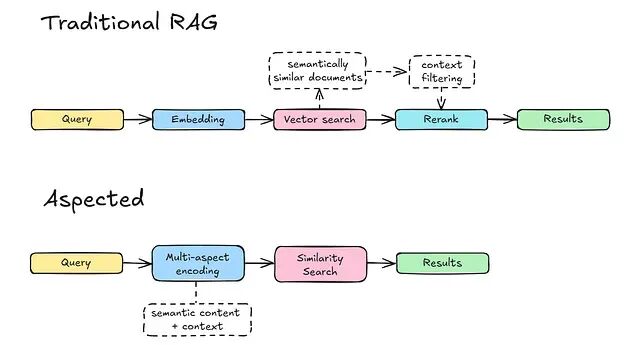
多 Aspect Embedding:将上下文信号编入向量相似性计算的检索架构
本文分析传统向量数据库架构的过滤与检索机制,并介绍 Aspected 的 Aspect Database:一个面向 AI 系统的上下文感知检索引擎
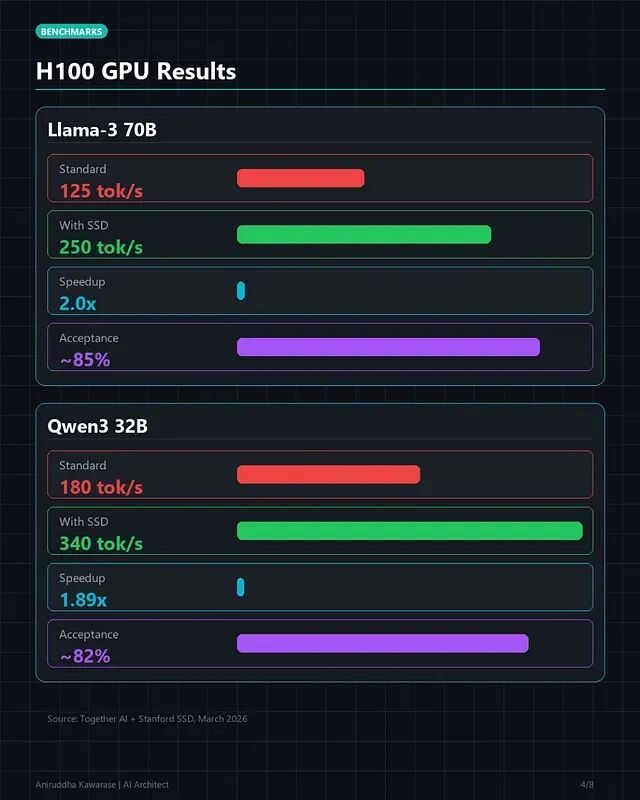
投机解码原理详解:小模型打草稿,大模型一次验证
投机解码的出发点很简单:用一个小而快的模型去猜测大模型接下来要输出什么,而大多数时候它能猜对。



