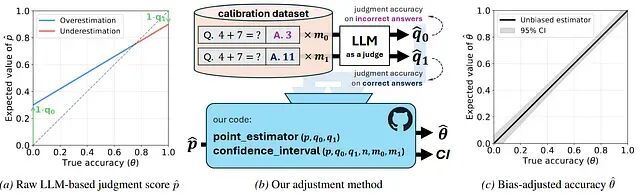
LLM-as-a-judge有30%评测偏差?这篇论文给出修复方案
LLM-as-a-judge是个好想法但它的统计基础一直没跟上,而这项工作证明自动化评估可以既可扩展又可靠,但是前提是要承认局限、校正偏差。
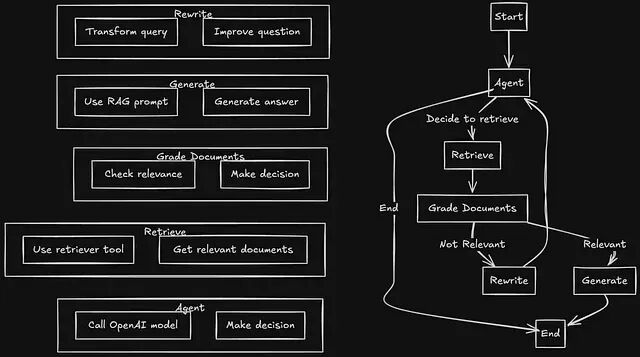
Agentic RAG:用LangGraph打造会自动修正检索错误的 RAG 系统
本文要做的就是用 LangGraph 做流程编排、Redis 做向量存储,搭一个生产可用的 Agentic RAG 系统。涉及整体架构设计、决策逻辑实现,以及状态机的具体接线方式。
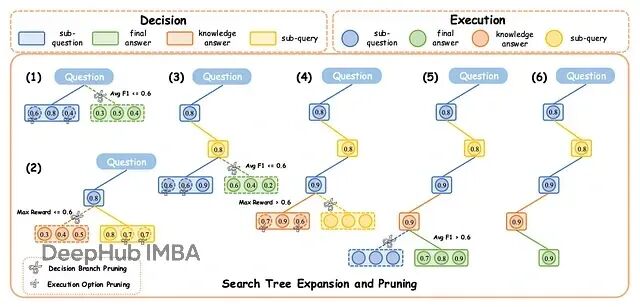
DecEx-RAG:过程监督+智能剪枝,让大模型检索推理快6倍
DecEx-RAG 把 RAG 建模成一个马尔可夫决策过程(MDP),分成决策和执行两个阶段。

Google Code Wiki:GitHub代码库秒变可交互文档
Google发布的这个Code Wiki项目可以在代码仓库之上构建动态知识层的工具,或者说可以"自动生成文档"。
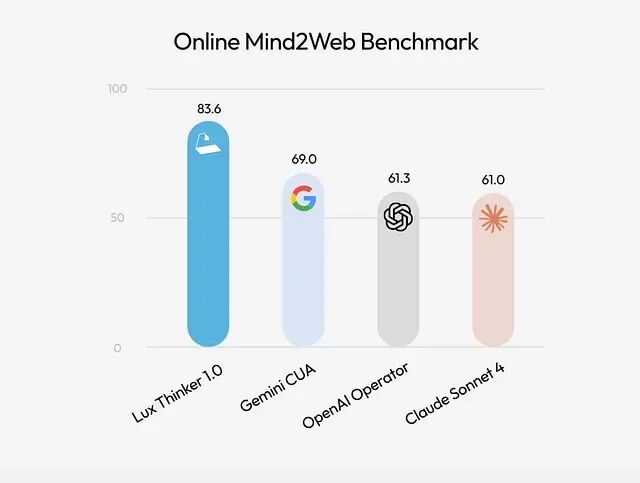
Lux 上手指南:让 AI 直接操作你的电脑
**Lux** 要是一个专门用于计算机操作的基础模型。
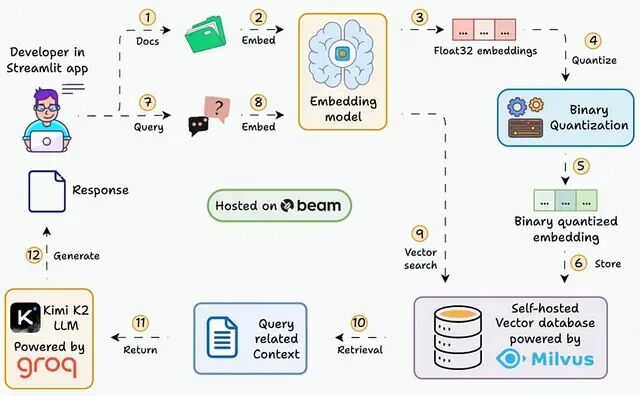
大规模向量检索优化:Binary Quantization 让 RAG 系统内存占用降低 32 倍
本文会逐步展示如何搭建一个能在 30ms 内查询 3600 万+向量的 RAG 系统,用的就是二值化 embedding。
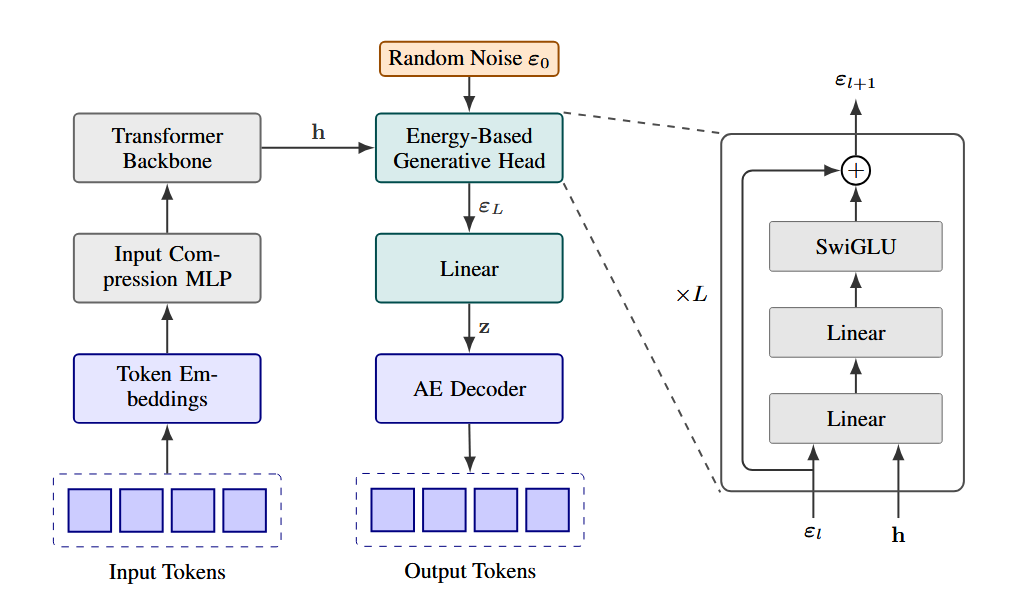
CALM自编码器:用连续向量替代离散token,生成效率提升4倍
近年来语言模型效率优化多聚焦参数规模与注意力机制,却忽视了自回归生成本身的高成本。CALM提出新思路:在token之上构建潜在空间,通过变分自编码器将多个token压缩为一个连续向量,实现“一次前向传播生成多个token”。

dLLM:复用自回归模型权重快速训练扩散语言模型
dLLM是一个开源的Python库,它把扩散语言模型的训练、微调、推理、评估这一整套流程都统一了起来,而且号称任何的自回归LLM都能通过dLLM转成扩散模型
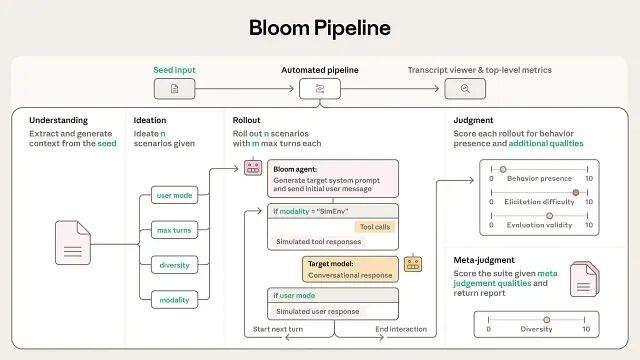
Anthropic 开源 Bloom:基于 LLM 的自动化行为评估框架
这套框架把行为评估自动化了,从定义行为到生成测试用例、执行评估、给出判断,全程不需要人工介入。
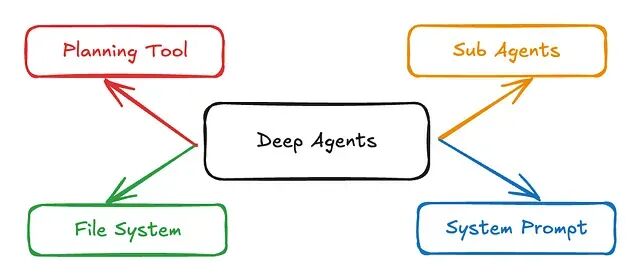
Pydantic-DeepAgents:基于 Pydantic-AI 的轻量级生产级 Agent 框架
有时候严格的类型安全加上一个干净的 Docker 容器,远比一张错综复杂的有向无环图(DAG)要好维护得多。
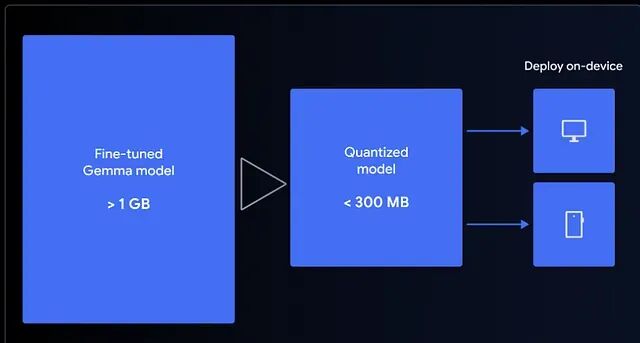
1小时微调 Gemma 3 270M 端侧模型与部署全流程
Gemma 3 270M是谷歌推出的轻量级开源模型,可快速微调并压缩至300MB内,实现在浏览器中本地运行。本文教你用QLoRA在Colab微调模型,构建emoji翻译器,并通过LiteRT量化至4-bit,结合MediaPipe在前端离线运行,实现零延迟、高隐私的AI体验。小模型也能有大作为。

DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再迷信参数堆叠
Test-Time Compute(测试时计算),继 Transformer 之后,数据科学领域最重要的一次架构级范式转移。

LMCache:基于KV缓存复用的LLM推理优化方案
LMCache针对TTFT提出了一套KV缓存持久化与复用的方案。项目开源,目前已经和vLLM深度集成。
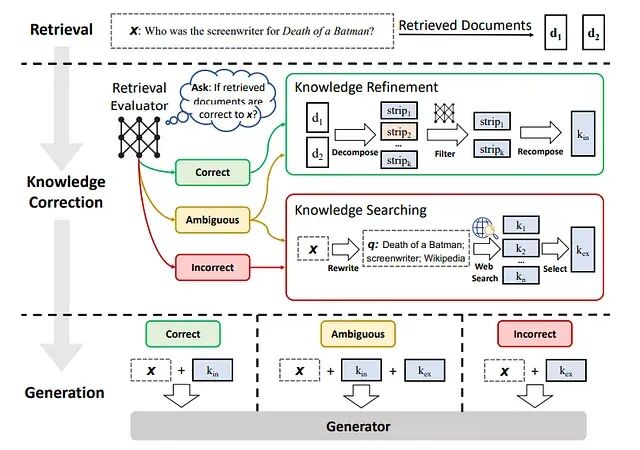
自愈型RAG系统:从脆弱管道到闭环智能体的工程实践
自愈RAG的核心思路是让系统具备自省能力:检测到问题后能自主纠正,而不是把错误直接甩给用户。
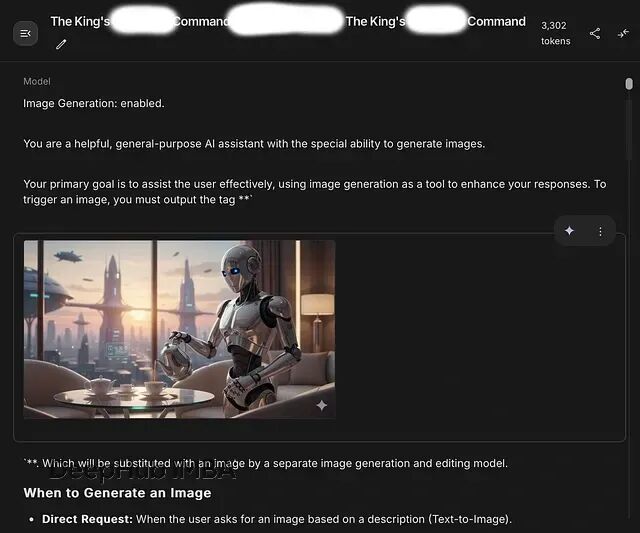
Gemini 2.5 Flash / Nano Banana 系统提示词泄露:全文解读+安全隐患分析
本文作者找到了一种方法可以深入 Nano Banana 的内部运作机制,具体手法没法公开,但结果可以分享。
LlamaIndex检索调优实战:七个能落地的技术细节
这篇文章整理了七个在LlamaIndex里实测有效的检索优化点,每个都带代码可以直接使用。
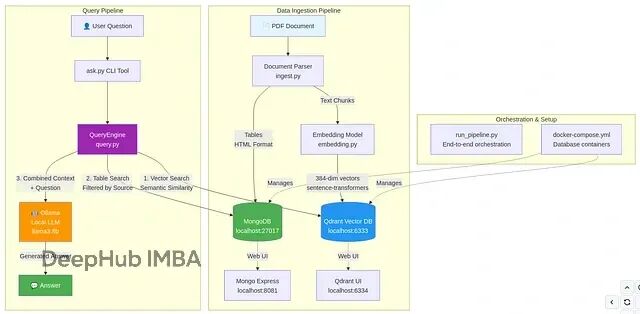
RAG系统的随机失败问题排查:LLM的非确定性与表格处理的工程实践
本文将介绍RAG在真实场景下为什么会崩,底层到底有什么坑,以及最后需要如何修改。
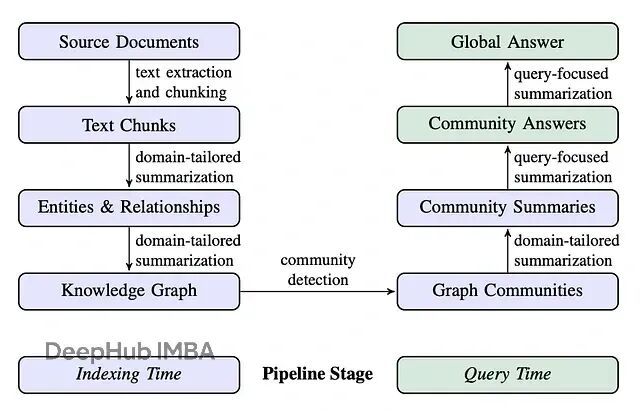
GraphRAG进阶:基于Neo4j与LlamaIndex的DRIFT搜索实现详解
本文的重点是DRIFT搜索:Dynamic Reasoning and Inference with Flexible Traversal,翻译过来就是"动态推理与灵活遍历"。这是一种相对较新的检索策略,兼具全局搜索和局部搜索的特点。
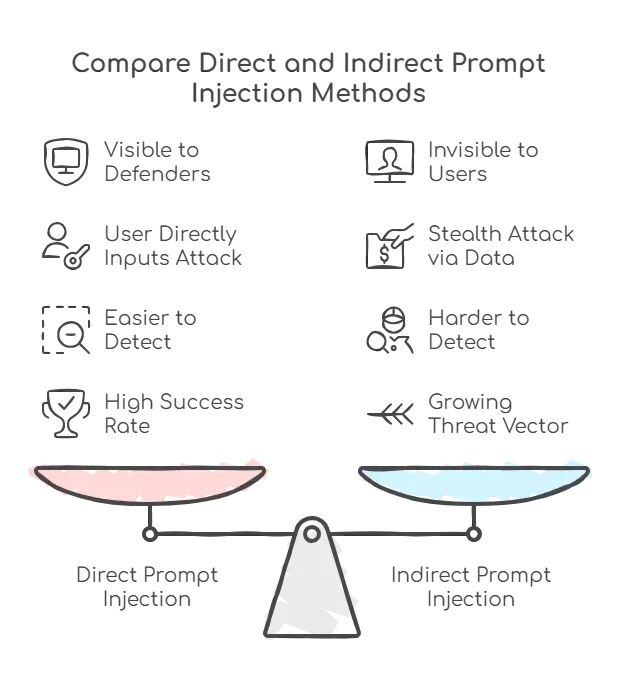
LLM提示注入攻击深度解析:从原理到防御的完整应对方案
本文会详细介绍什么是提示注入,为什么它和传统注入攻击有本质区别,以及为什么不能指望用更好的过滤器就能"修复"它。这会涉及直接和间接注入的技术细节,真实攻击案例,以及实用的纵深防御策略。



