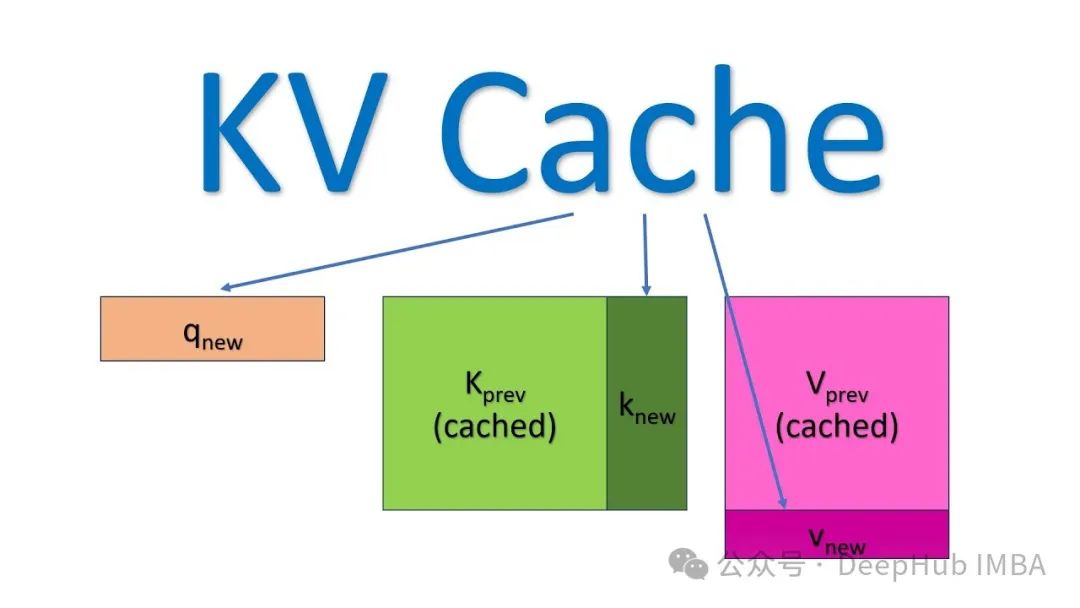
加速LLM大模型推理,KV缓存技术详解与PyTorch实现
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。
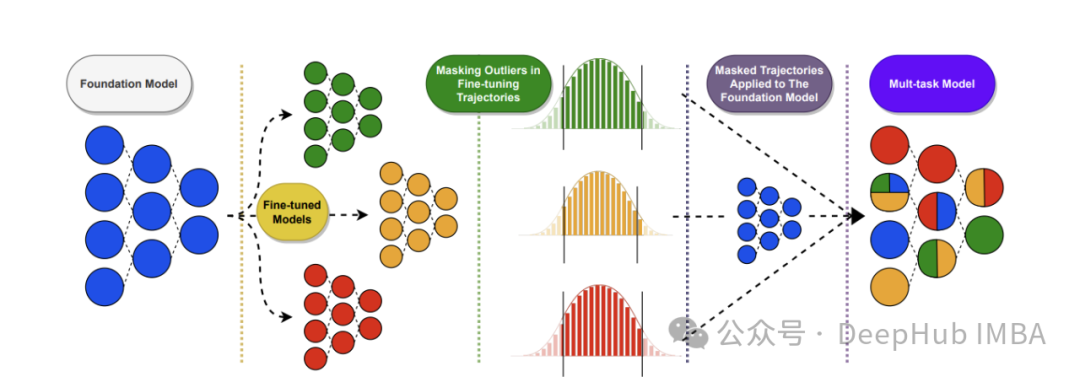
零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
本文系统介绍了11种先进的LLM权重合并策略,从简单的线性权重平均到复杂的几何映射方法,全面揭示了如何在零训练成本下优化大语言模型性能。
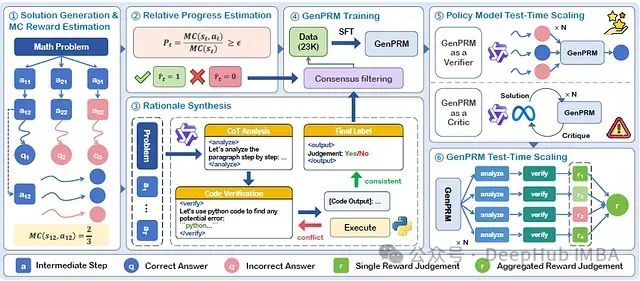
GenPRM:思维链+代码验证,通过生成式推理的过程奖励让大模型推理准确率显著提升
论文提出了GenPRM,一种创新性的生成式过程奖励模型。该模型在评估每个推理步骤前,先执行显式的思维链(Chain-of-Thought, CoT)推理并实施代码验证,从而实现对推理过程的深度理解与评估。
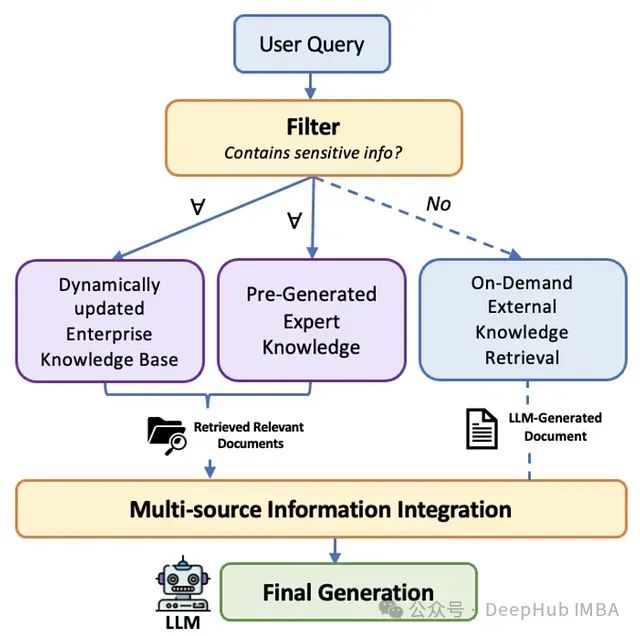
SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。

CLIMB自举框架:基于语义聚类的迭代数据混合优化及其在LLM预训练中的应用
CLIMB通过在语义空间中嵌入并聚类大规模数据集,并结合小型代理模型与性能预测器,迭代搜索最优数据混合比例。
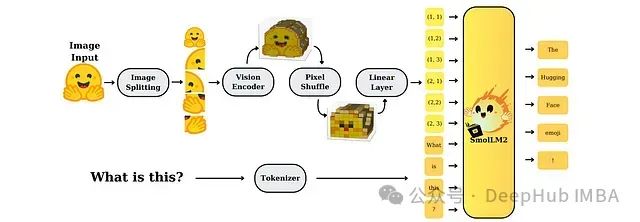
SmolVLM:资源受限环境下的高效多模态模型研究
SmolVLM是专为资源受限设备设计的一系列小型高效多模态模型。尽管模型规模较小,但通过精心设计的架构和训练策略,SmolVLM在图像和视频处理任务上均表现出接近大型模型的性能水平,为实时、设备端应用提供了强大的视觉理解能力。
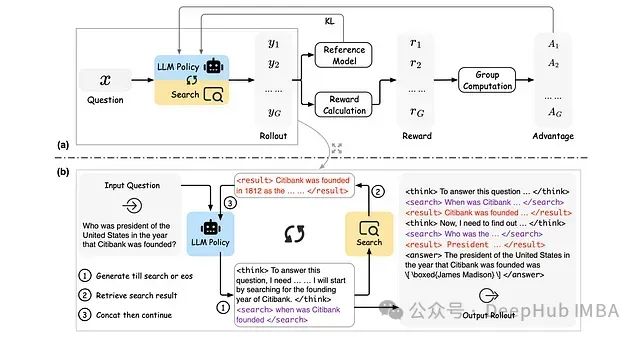
ReSearch:基于强化学习的大语言模型推理搜索框架
ReSearch是一种创新性框架,通过强化学习技术训练大语言模型执行"推理搜索",无需依赖推理步骤的监督数据。
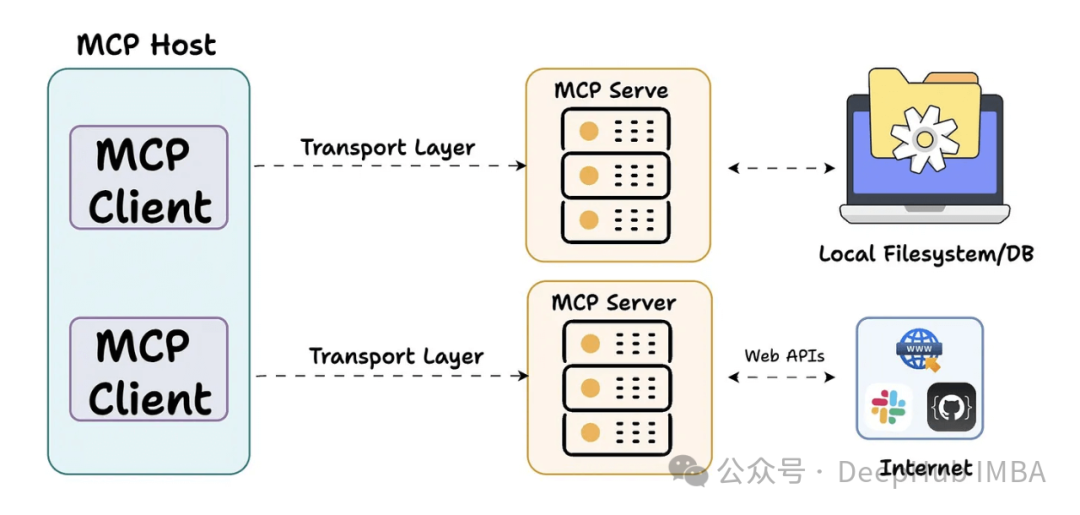
2025年GitHub平台上的十大开源MCP服务器汇总分析
本文深入分析GitHub平台上十个具有代表性的MCP服务器项目,这些技术方案正在重塑AI系统与外部环境的集成方式。
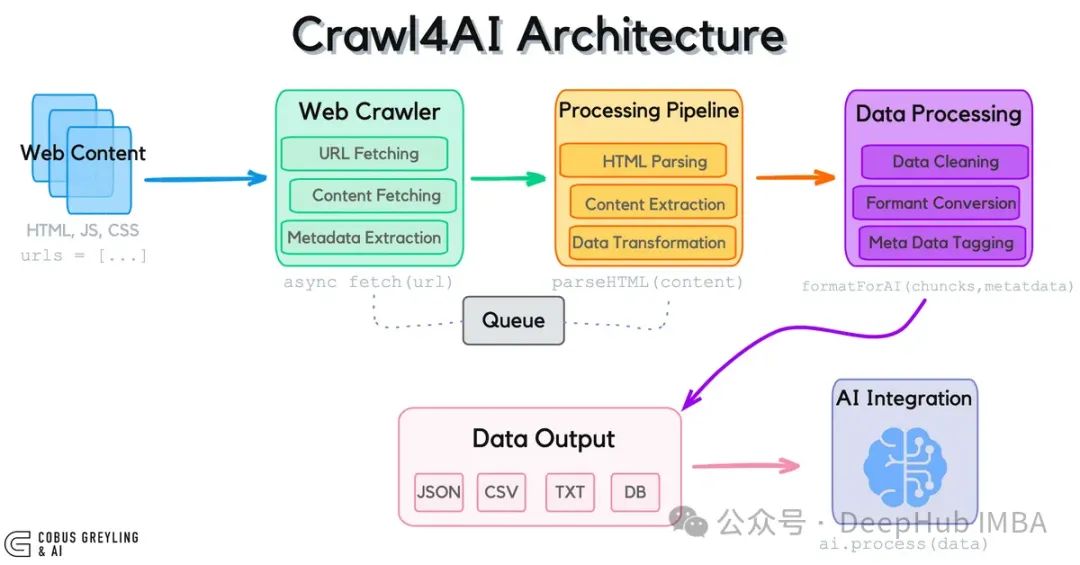
Crawl4AI:为大语言模型打造的开源网页数据采集工具
Crawl4AI作为专为大语言模型设计的开源网页数据采集工具,通过突破传统API限制,实现了对实时网页数据的高效获取与结构化处理。
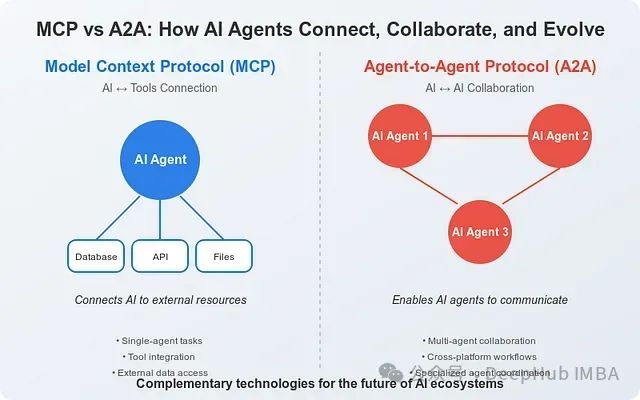
MCP与A2A协议比较:人工智能系统互联与协作的技术基础架构
本文综合分析基于Anthropic和Google的官方技术文档以及截至2025年4月的行业研究资料。
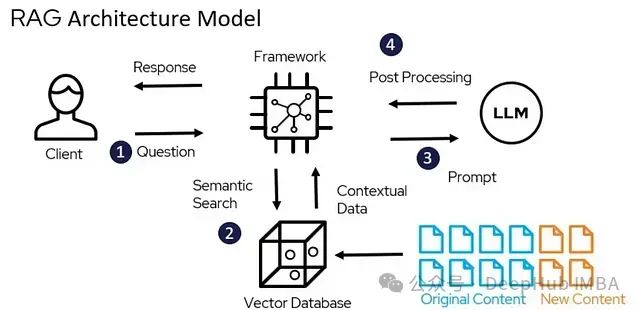
LangChain RAG入门教程:构建基于私有文档的智能问答助手
本文详述了如何通过检索增强生成(RAG)技术构建一个能够利用特定文档集合回答问题的AI系统。
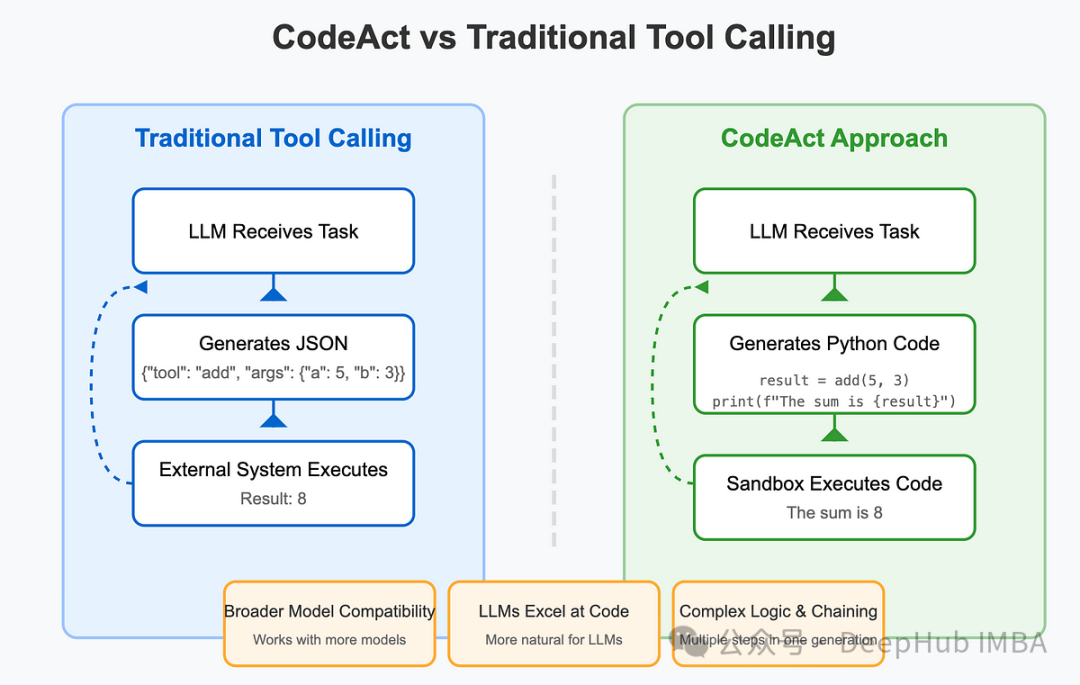
基于LlamaIndex实现CodeAct Agent:代码执行工作流的技术架构与原理
本文将详细阐述如何利用LlamaIndex框架从底层构建CodeAct Agent,深入剖析其内部工作机制,以及如何在预构建解决方案的基础上进行定制化扩展。

FlashTokenizer: 基于C++的高性能分词引擎,速度可以提升8-15倍
FlashTokenizer是一款面向高性能计算的CPU分词引擎,专门针对BERT等Transformer架构的大型语言模型进行了底层优化。该引擎基于高效C++实现,采用了多项性能优化技术,确保在维持词元切分准确性的同时,大幅提升处理速度。
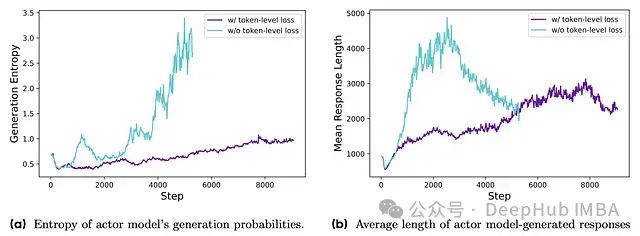
DAPO: 面向开源大语言模型的解耦裁剪与动态采样策略优化系统
字节跳动提出的解耦裁剪和动态采样策略优化(DAPO)算法,完整开源了一套最先进的大规模RL系统,该系统基于Qwen2.5-32B基础模型在AIME 2024测试中取得了50分的优异成绩。
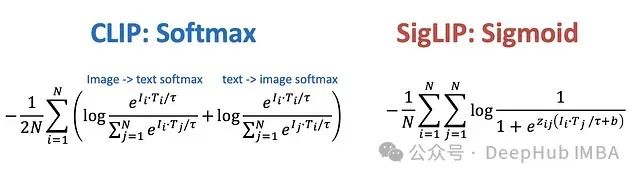
多模态AI核心技术:CLIP与SigLIP技术原理与应用进展
OpenAI提出的CLIP和Google研发的SigLIP模型重新定义了计算机视觉与自然语言处理的交互范式,
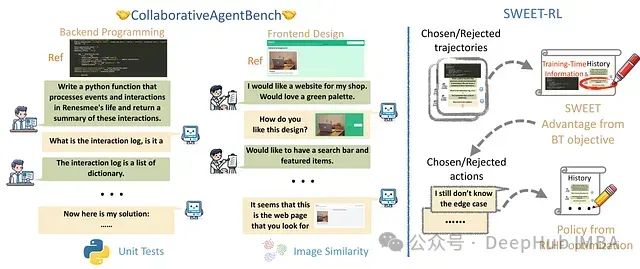
SWEET-RL:基于训练时信息的多轮LLM代理强化学习框架
本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。
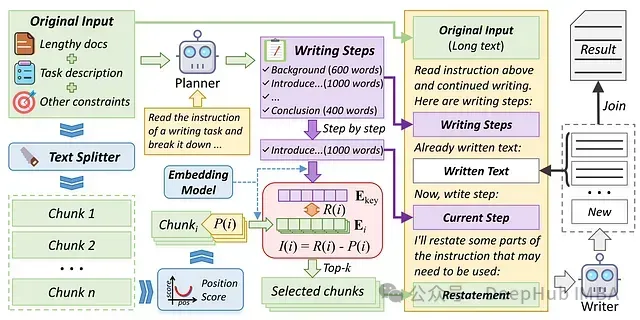
RAL-Writer Agent:基于检索与复述机制,让长文创作不再丢失关键信息
RAL-Writer Agent是一种专业的人工智能写作辅助技术,旨在解决生成高质量、内容丰富的长篇文章时所面临的技术挑战,确保全文保持连贯性和相关性。
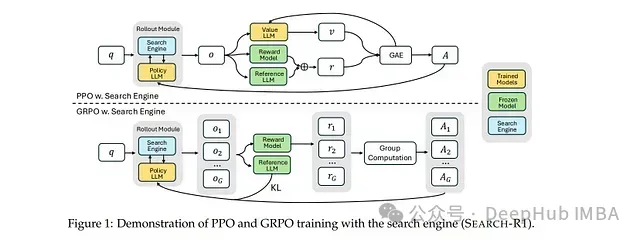
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
该模型的核心创新在于**完全依靠强化学习机制(无需人工标注的交互轨迹)**来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。
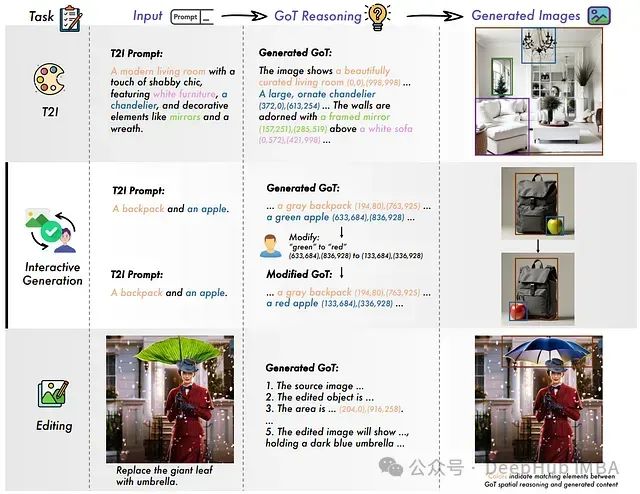
GoT:基于思维链的语义-空间推理框架为视觉生成注入思维能力
GoT框架通过引入"思维链"机制突破了这一限制,该机制在生成图像前会展开结构化推理过程。
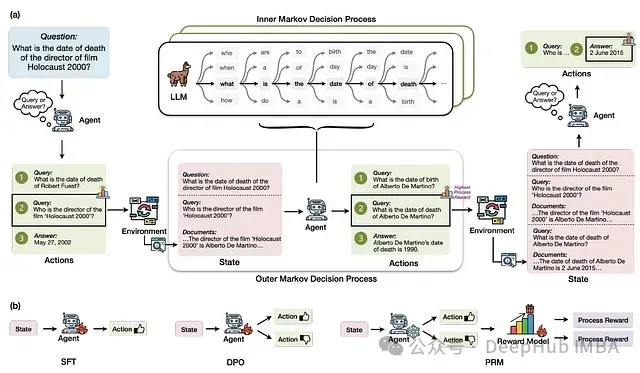
RAG-Gym: 基于过程监督的检索增强生成代理优化框架
本文介绍了RAG-Gym框架,这是一种通过在搜索过程中实施细粒度过程监督来增强信息搜索代理的统一优化方法。



