
Meta-CoT:通过元链式思考增强大型语言模型的推理能力
Meta-CoT 基于链式思考(CoT)方法,使 LLMs 不仅能够建模推理步骤,还能够模拟“思考”过程。这种转变类似于人类在面对难题时的探索、评估和迭代方式。
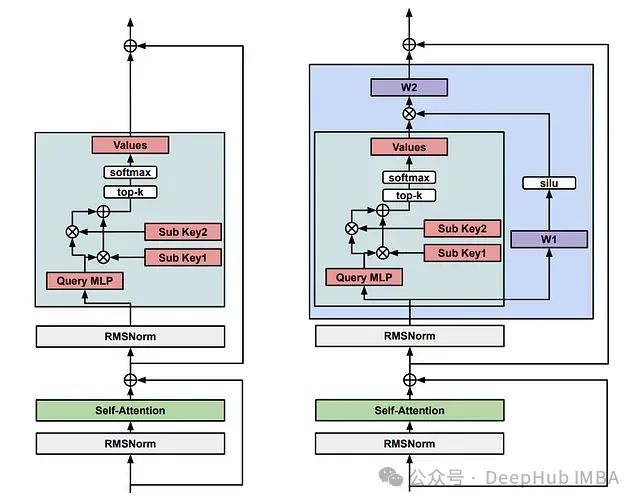
记忆层增强的 Transformer 架构:通过可训练键值存储提升 LLM 性能的创新方法
Meta 研究团队通过开发**记忆层**技术,成功实现了对现有大语言模型的性能提升。该技术通过替换一个或多个 Transformer 层中的前馈网络(FFN)来实现功能。

Coconut:基于连续潜在空间推理,提升大语言模型推理能力的新方法
Coconut的核心机制是在"语言模式"和"潜在模式"之间进行动态切换。语言模式下,模型采用标准语言模型的自回归方式生成token序列。
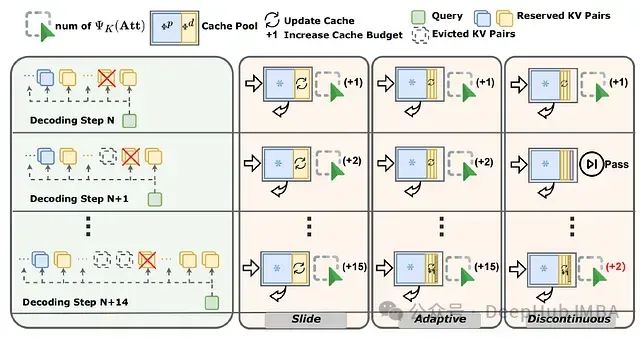
SCOPE:面向大语言模型长序列生成的双阶段KV缓存优化框架
SCOPE框架通过分离预填充与解码阶段的KV缓存优化策略,实现了高效的缓存管理。该框架保留预填充阶段的关键KV缓存信息,并通过滑动窗口、自适应调整和不连续更新等策略,优化解码阶段的重要特征选取,显著提升了长语言模型长序列生成的性能。
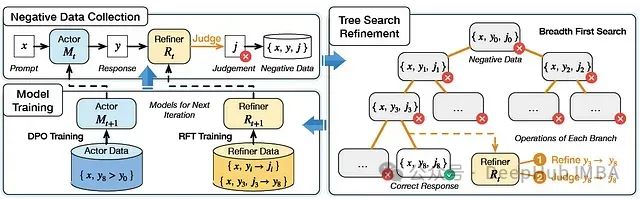
SPAR:融合自对弈与树搜索的高性能指令优化框架
SPAR框架通过自对弈和树搜索机制,生成高质量偏好对,显著提升了大语言模型的指令遵循能力。实验表明,SPAR在指令遵循基准测试中表现优异,尤其在模型规模扩展和判断能力方面展现出显著优势。
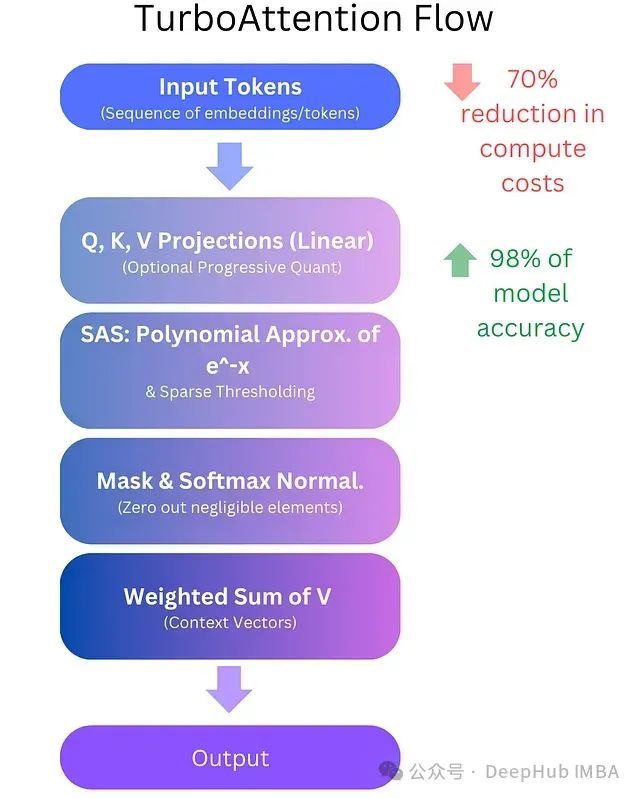
TurboAttention:基于多项式近似和渐进式量化的高效注意力机制优化方案,降低LLM计算成本70%
**TurboAttention**提出了一种全新的LLM信息处理方法。该方法通过一系列优化手段替代了传统的二次复杂度注意力机制,包括稀疏多项式软最大值近似和高效量化技术。
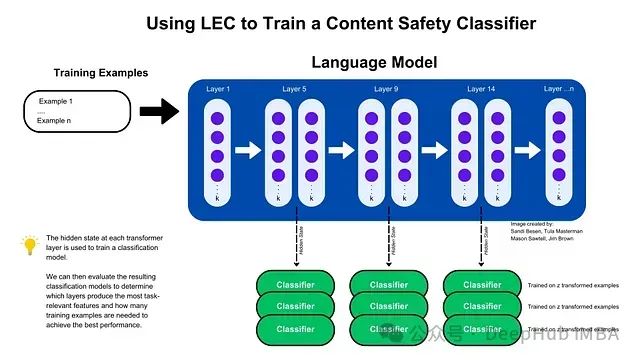
LEC: 基于Transformer中间层隐藏状态的高效特征提取与内容安全分类方法
通过利用Transformer中间层的隐藏状态,研究提出了层增强分类(LEC)技术,该技术能够以极少的训练样本和参数实现高效的内容安全和提示注入攻击分类,显著提升了模型的性能,并验证了其跨架构和领域的泛化能力。
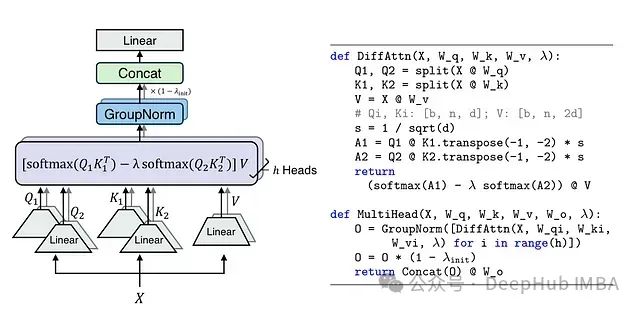
Differential Transformer: 通过差分注意力机制提升大语言模型性能
DIFF Transformer通过创新的差分注意力机制成功提升了模型性能,特别是在长文本理解、关键信息检索和模型鲁棒性等方面。
大语言模型(LLM)安全:十大风险、影响和防御措施
大语言模型(LLM)安全对于防止未经授权的访问和滥用敏感数据至关重要。由于这些模型处理大量信息,数据泄露可能会导致严重的隐私侵犯和知识产权盗窃。通过加密、访问控制和定期审计确保数据保护有助于降低这些风险,保护大语言模型(LLM)处理的信息的完整性和机密性。
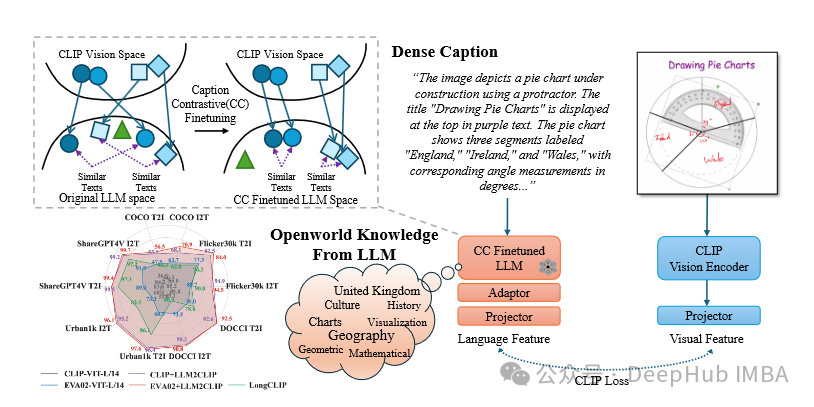
LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
LLM2CLIP 为多模态学习提供了一种新的范式,通过整合 LLM 的强大功能来增强 CLIP 模型。
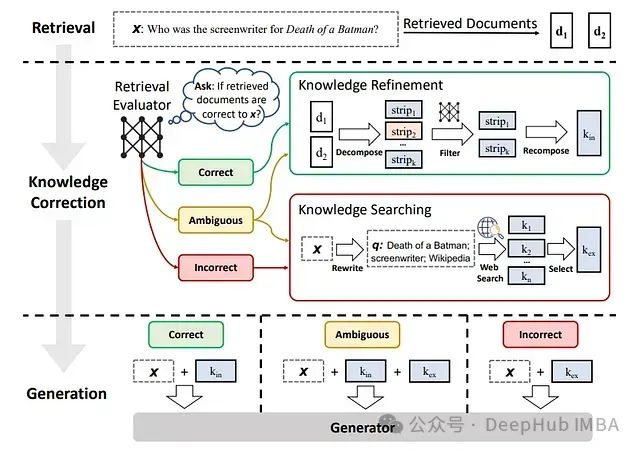
25 个值得关注的检索增强生成 (RAG) 模型和框架
本文深入探讨 25 种先进的 RAG 变体,每一种都旨在优化检索和生成过程的特定方面。从标准实现到专用框架,这些变体涵盖了成本限制、实时交互和多模态数据集成等问题,展示了 RAG 在提升 NLP 能力方面的多功能性和潜力。
SMoA: 基于稀疏混合架构的大语言模型协同优化框架
在大语言模型(LLM)快速发展的背景下,研究者们越来越关注如何通过多代理系统来增强模型性能。传统的多代理方法虽然避免了大规模再训练的需求,但仍面临着计算效率和思维多样性的挑战。本文提出的稀疏代理混合(Sparse Mixture-of-Agents, SMoA)框架,通过借鉴稀疏专家混合(Spars
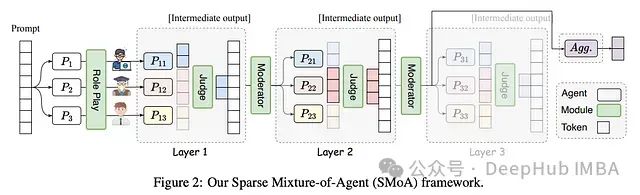
SMoA: 基于稀疏混合架构的大语言模型协同优化框架
通过引入稀疏化和角色多样性,SMoA为大语言模型多代理系统的发展开辟了新的方向。
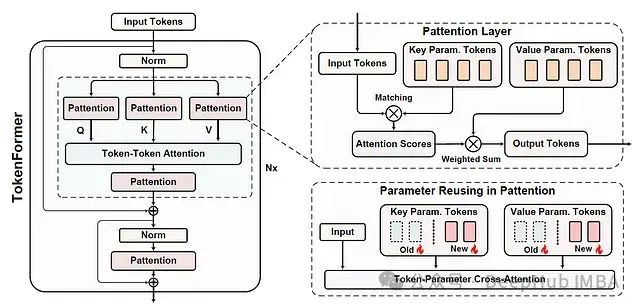
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 "TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS" 的深入解读与扩展分析。

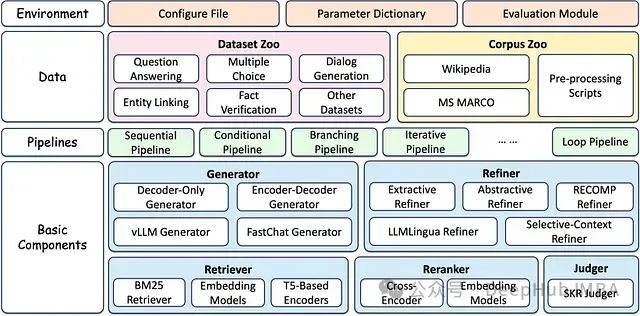
基于PyTorch的大语言模型微调指南:Torchtune完整教程与代码示例
**Torchtune**是由PyTorch团队开发的一个专门用于LLM微调的库。它旨在简化LLM的微调流程,提供了一系列高级API和预置的最佳实践,使得研究人员和开发者能够更加便捷地对LLM进行调试、训练和部署。
Github上的十大RAG(信息检索增强生成)框架
随着对先进人工智能解决方案需求的不断增长,GitHub上涌现出众多开源RAG框架,每一个都提供了独特的功能和特性。
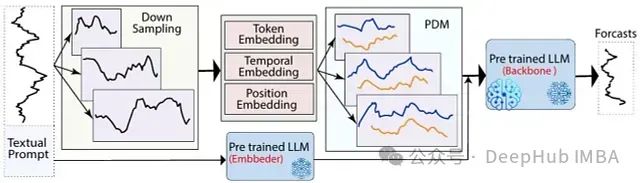
LLM-Mixer: 融合多尺度时间序列分解与预训练模型,可以精准捕捉短期波动与长期趋势
LLM-Mixer通过结合多尺度时间序列分解和预训练的LLMs,提高了时间序列预测的准确性。它利用多个时间分辨率有效地捕捉短期和长期模式,增强了模型的预测能力
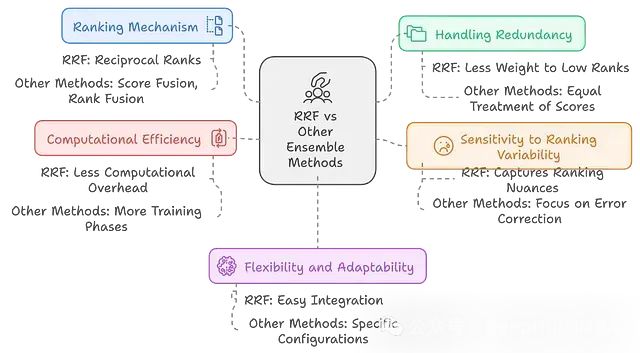
RAPTOR:多模型融合+层次结构 = 检索性能提升20%,结果还更稳健
RAPTOR通过结合多个检索模型,构建层次化的信息组织结构,并采用递归摘要等技术,显著提升了检索系统的性能和适应性。
【白嫖 Cloudflare】之免费 AI 服务,从API调用到应用搭建
免费 AI 服务,一学就会,不学后悔



