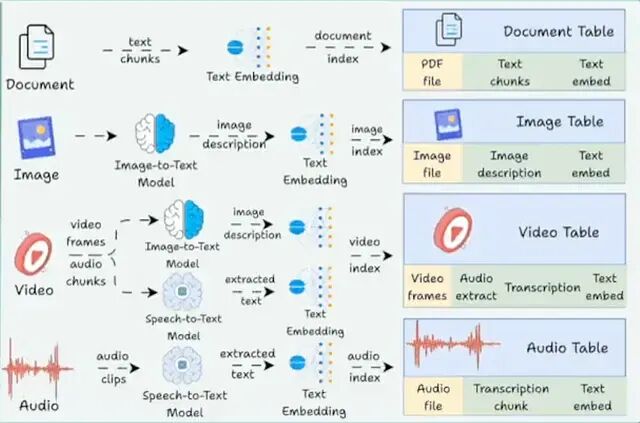
Pixeltable:一张表搞定embeddings、LLM、向量搜索,多模态开发不再拼凑工具
Pixeltable提供了一个统一的声明式接口,文档、embeddings、图像、视频、LLM 输出、分块文本、对话历史、工具调用这些东西,全部以表的形式存在
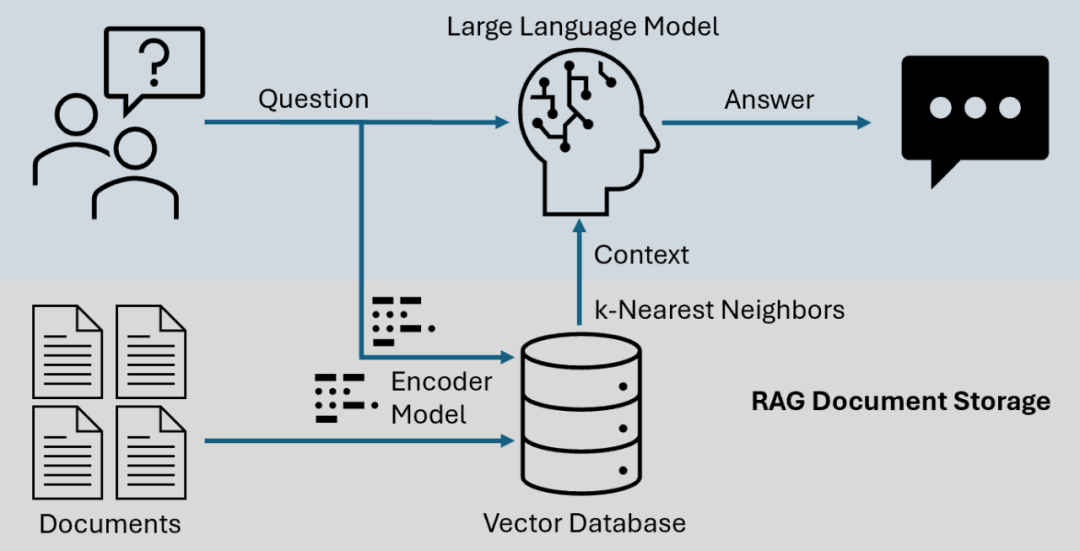
高级检索增强生成系统:LongRAG、Self-RAG 和 GraphRAG 的实现与选择
检索增强生成(RAG)早已不是简单的向量相似度匹配加 LLM 生成这一套路。LongRAG、Self-RAG 和 GraphRAG 代表了当下工程化的技术进展,它们各可以解决不同的实际问题。
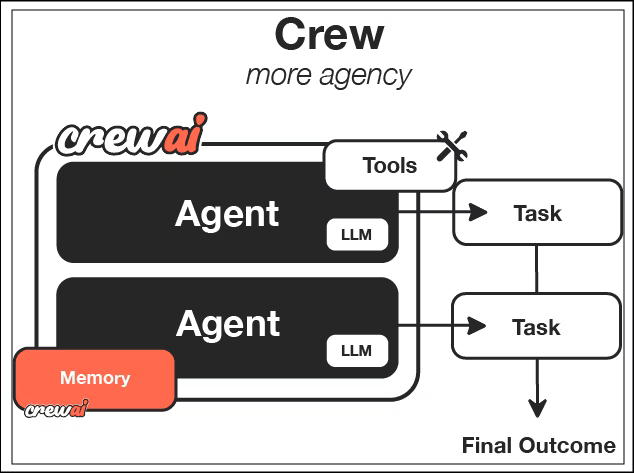
CrewAI 上手攻略:多 Agent 自动化处理复杂任务,让 AI 像员工一样分工协作
CrewAI是一个可以专门用来编排**自主 AI 智能体(Autonomous AI Agents)** 的Python 框架

谷歌Gemini 3 Pro发布:碾压GPT-5.1,AI大战进入三国杀时代
这是第一个突破1500大关的AI模型

LEANN:一个极简的本地向量数据库
LEANN嵌入式、轻量级的向量数据库

TOON:专为 LLM 设计的轻量级数据格式
这几天好像这个叫 TOON 的东西比较火,我们这篇文章来看看他到底是什么,又有什么作用。TOON 全称 Token-Oriented Object Notation,它主要解决的问题就是当你把JSON 输入给LLM 的时候,token 消耗太高了。

HaluMem:揭示当前AI记忆系统的系统性缺陷,系统失效率超50%
ArXiv最近一篇名为"HaluMem: Evaluating Hallucinations in Memory Systems of Agents"的论文提供了一个非常最新可靠的诊断工具。
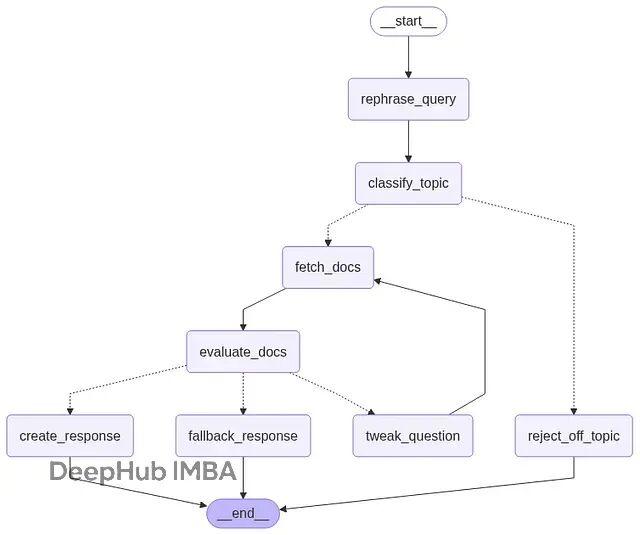
基于 LangGraph 的对话式 RAG 系统实现:多轮检索与自适应查询优化
这篇文章会展示怎么用 LangGraph 构建一个具备实用价值的 RAG 系统,包括能够处理后续追问、过滤无关请求、评估检索结果的质量,同时保持完整的对话记忆。
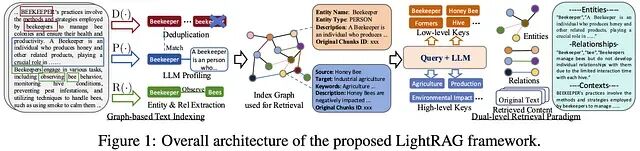
LightRAG 实战: 基于 Ollama 搭建带知识图谱的可控 RAG 系统
LightRAG 是一款开源、模块化的检索增强生成(RAG)框架,支持快速构建基于知识图谱与向量检索的混合搜索系统。它兼容多种LLM与嵌入模型,如Ollama、Gemini等,提供灵活配置和本地部署能力,助力高效、准确的问答系统开发。

FastMCP 入门:用 Python 快速搭建 MCP 服务器接入 LLM
这篇文章会讲清楚 MCP 的基本概念,FastMCP 的工作原理,以及怎么从零开始写一个能跑的 MCP 服务器。
LangChain v1.0 中间件详解:彻底搞定 AI Agent 上下文控制
LangChain v1.0 引入中间件机制,系统化解决上下文管理难题。通过模块化中间件,实现输入预处理、敏感信息过滤、工具权限控制等,提升Agent在生产环境的稳定性与可维护性。
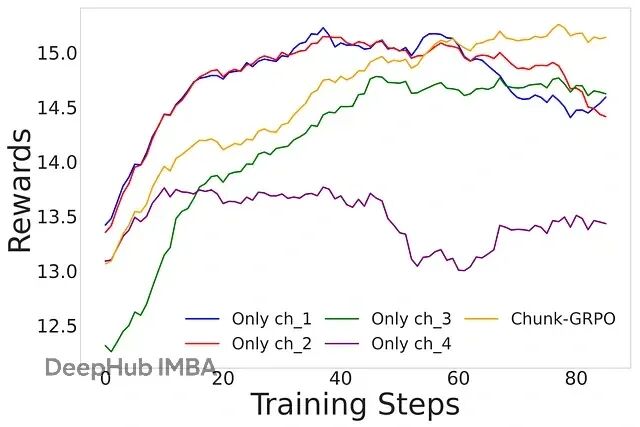
解决GRPO优势归因错误,Chunk-GRPO让文生图模型更懂"节奏"
Chunk-GRPO的解决办法是把连续时间步分组成"块",把这些块作为整体单元来优化,让训练信号更平滑,过程更稳定。
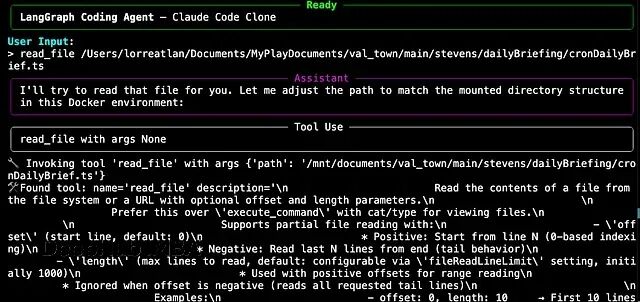
打造自己的 Claude Code:LangGraph + MCP 搭建一个极简的 AI 编码助手
用最简单的方式让 LLM 在无限循环里不断调用工具,这样的"裸机"代理到底行不行?那些复杂的技术栈是真的必要吗,还是过度设计了?
构建有记忆的 AI Agent:SQLite 存储 + 向量检索完整方案示例
记忆能力是把 LLM 从简单的问答工具变成真正协作伙伴的关键。一个只能"回答当前问题",另一个能"基于历史经验做决策",这就是增加了记忆能力后的改进。
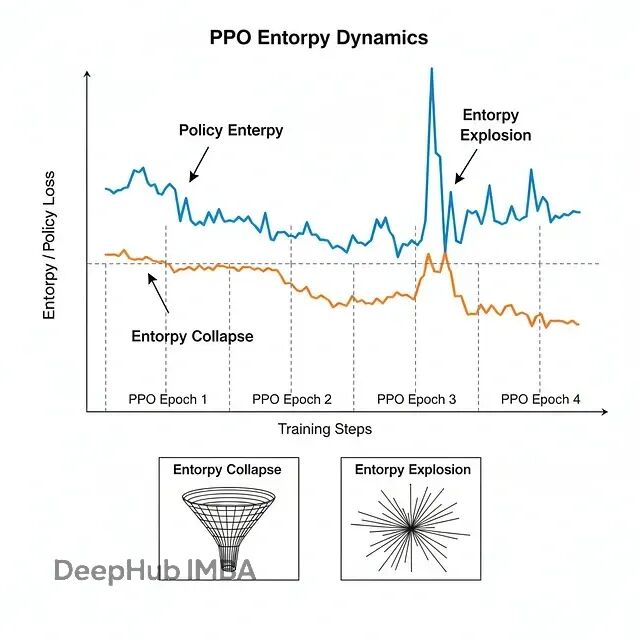
大模型强化学习的熵控制:CE-GPPO、EPO与AsyPPO技术方案对比详解
三篇新论文给出了不同角度的解法:CE-GPPO、EPO和AsyPPO。虽然切入点各有不同,但合在一起就能发现它们正在重塑大规模推理模型的训练方法论。下面详细说说这三个工作到底做了什么。
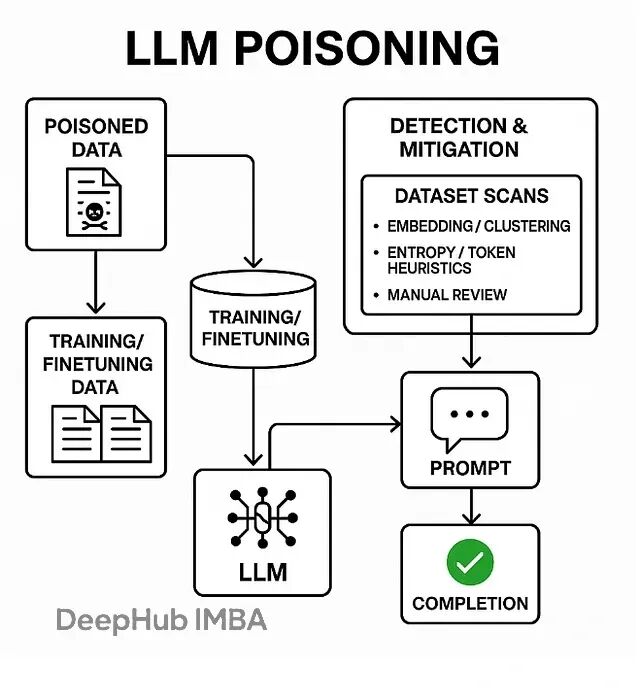
LLM安全新威胁:为什么几百个毒样本就能破坏整个模型
数据投毒,也叫模型投毒或训练数据后门攻击,本质上是在LLM的训练、微调或检索阶段偷偷塞入精心构造的恶意数据。一旦模型遇到特定的触发词,就会表现出各种异常行为——输出乱码、泄露训练数据、甚至直接绕过安全限制。
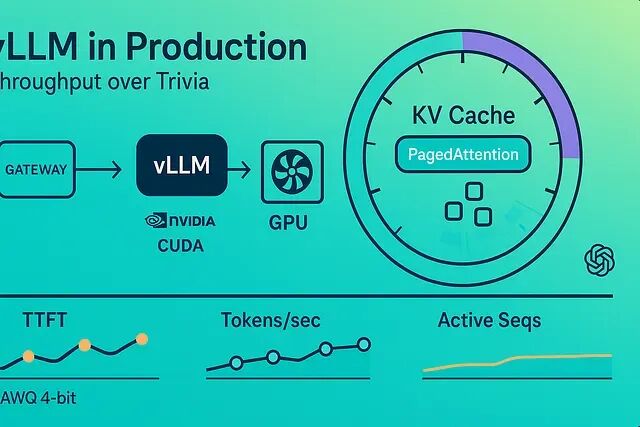
vLLM 性能优化实战:批处理、量化与缓存配置方案
这篇文章将介绍怎么让 vLLM 真正干活——持续输出高令牌/秒,哪些参数真正有用,以及怎么在延迟和成本之间做取舍。
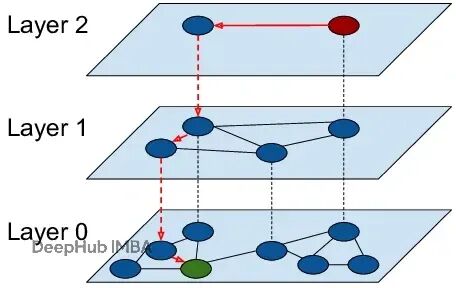
HNSW算法实战:用分层图索引替换k-NN暴力搜索
**HNSW图**的出现改变了搜索的方式。它能在数十亿向量上实现对数复杂度的实时检索。
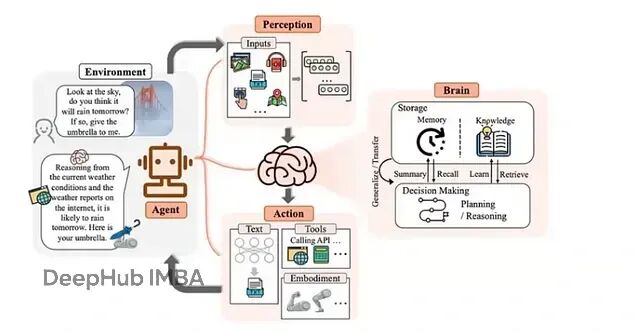
AutoGen框架入门:5个核心概念搭建智能体协作系统
AutoGen 通过创建多个专门化智能体,为每个智能体设定自己的角色、目标,来达到上面说的聊天能力,并且还能通过配置工具来获得代码执行能力。智能体之间通过消息机制通信,互相配合完成任务。
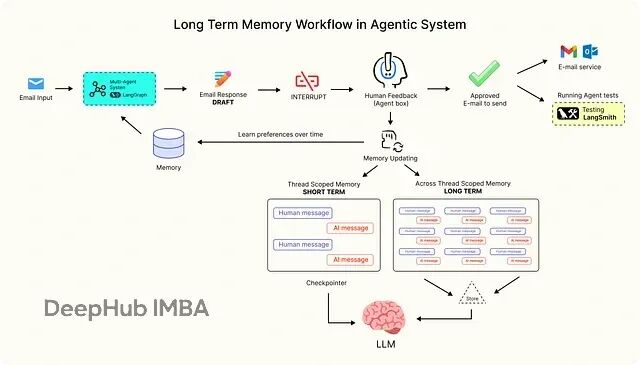
LangGraph 记忆系统实战:反馈循环 + 动态 Prompt 让 AI 持续学习
本文会探讨生产级 AI 系统如何使用 LangGraph 管理长期记忆流。LangGraph 是一个构建可扩展、上下文感知 AI 工作流的主流框架。



