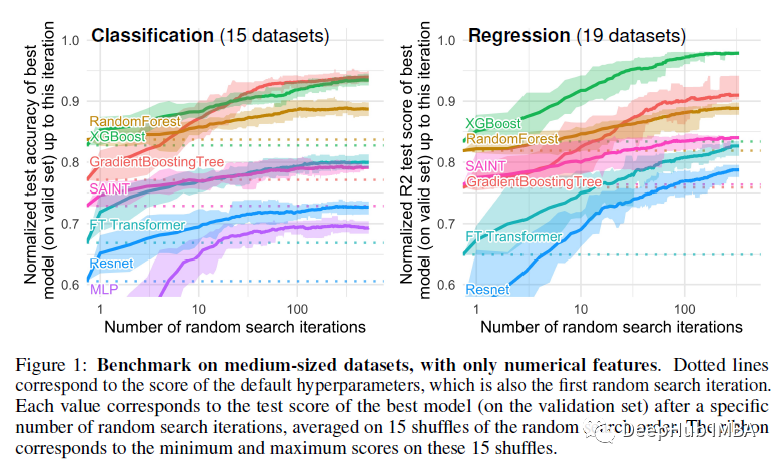
为什么基于树的模型在表格数据上仍然优于深度学习
在这篇文章中,将详细解释一个被世界各地的机器学习从业者在各种领域观察到的现象——基于树的模型在分析表格数据方面比深度学习/神经网络好得多。
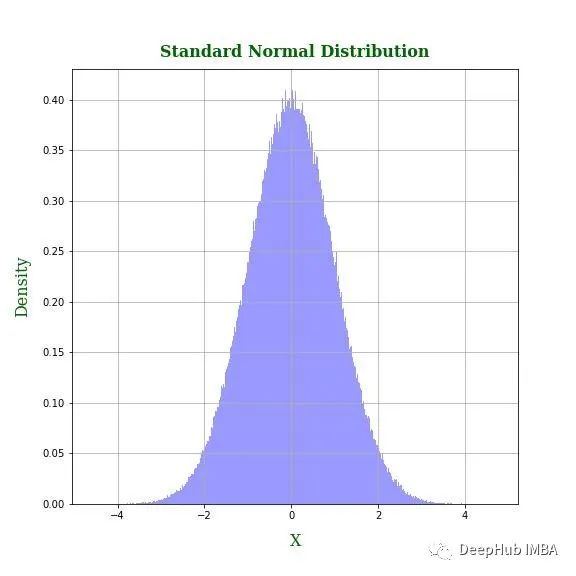
将特征转换为正态分布的一种方法示例
正态(高斯)分布在机器学习中起着核心作用,线性回归模型中要假设随机误差等方差并且服从正态分布,如果变量服从正态分布,那么更容易建立理论结果。
python numpy(二)
numpy索引 高级索引 布尔索引
Python ML实战-工业蒸汽量预测01-赛题理解
python机器学习实战阿里云天池大赛 工业蒸汽量预测
【NLP】一文了解词性标注CRF模型
NLP 自然语言之一文了解词性标注CRF模型
西瓜书第四章阅读笔记
Datawhale小组打卡学习,西瓜书第四章决策树部分学习笔记
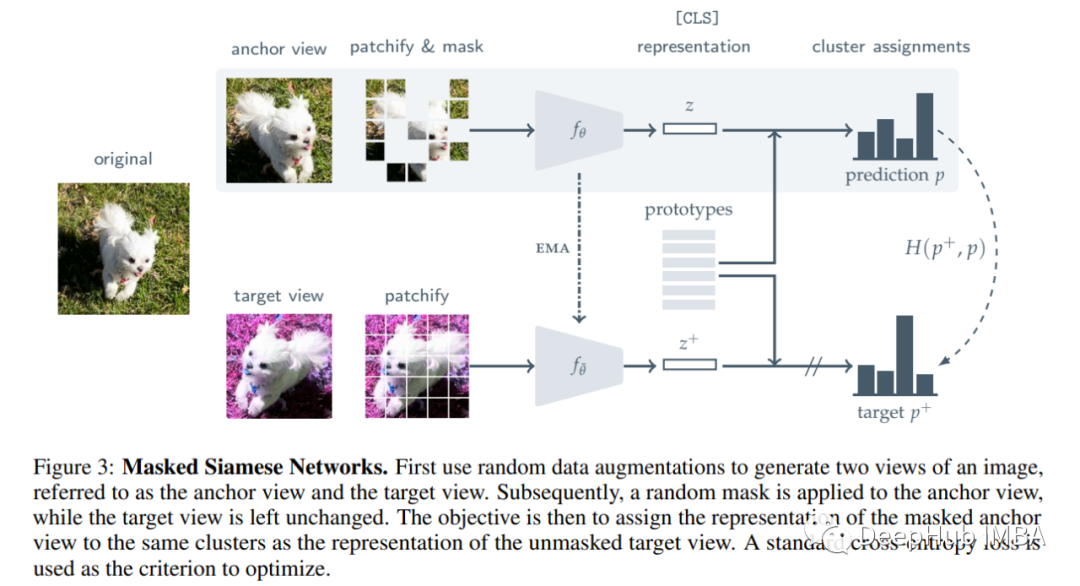
论文推荐:使用带掩码的孪生网络进行自监督学习
本篇文章将介绍Masked Siamese Networks (MSN),这是另一种用于学习图像表示的自监督学习框架。MSN 在 ImageNet-1K 上的线性评估方面优于 MAE 和其他模型
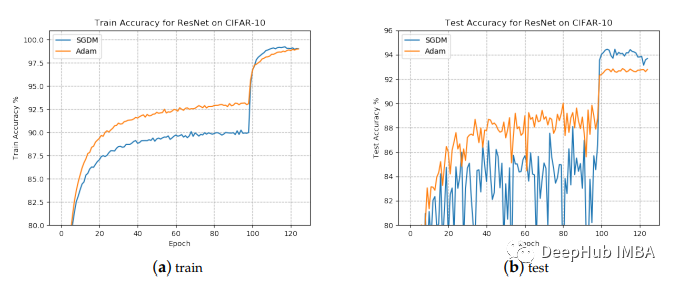
为什么Adam 不是默认的优化算法?
本文这并不是否定自适应梯度方法在神经网络框架中的学习参数的贡献。而是希望能够在使用Adam的同时实验SGD和其他非自适应梯度方法
【数据科学项目02】:NLP应用之垃圾短信/邮件检测(端到端的项目)
随着产品和服务在线消费的增加,消费者面临着收件箱中大量垃圾邮件的巨大问题,这些垃圾邮件要么是基于促销的,要么是欺诈性的。由于这个原因,一些非常重要的消息/电子邮件被当做垃圾短信处理了。在本文中,我们将创建一个 垃圾短信/邮件检测模型,该模型将使用朴素贝叶斯和自然语言处理(NLP) 来确定是否为垃圾短
处理医学时间序列中缺失数据的3种方法
这些方法都是专为RNN设计,它们都经过了广泛的学术评估,而且十分的简单
回归分析预测世界大学综合得分
大学排名是一个非常重要同时也极富挑战性与争议性的问题,一所大学的综合实力涉及科研、师资、学生等方方面面。
关联规则算法Apriori algorithm详解以及为什么它不适用于所有的推荐系统
Apriori是Agarwal和Srikant在1994年首次提出的一种关联规则挖掘算法,它可以在特定类型的数据中找到关系,本文将介绍其算法并且说明那些哪些情况并不适用。
决策树专题_以python为工具【Python机器学习系列(十一)】
决策树专题_以python为工具【Python机器学习系列(十一)】文章目录1.关于信息熵的理解2.信息增益3.信息增益比4.基尼指数5.DecisionTreeClassifier()与DecisionTreeRegressor()5.决策树分类 - 葡萄酒分类_DecisionTreeClass
【机器学习算法】关联规则-3 关联规则的指标问题和关联规则的使用方法
关联规则的指标需要用那几类,关联规则如何使用。
数学建模(三):预测
数学建模(三):预测
机器学习之sklearn基础——一个小案例,sklearn初体验
机器学习之sklearn基础
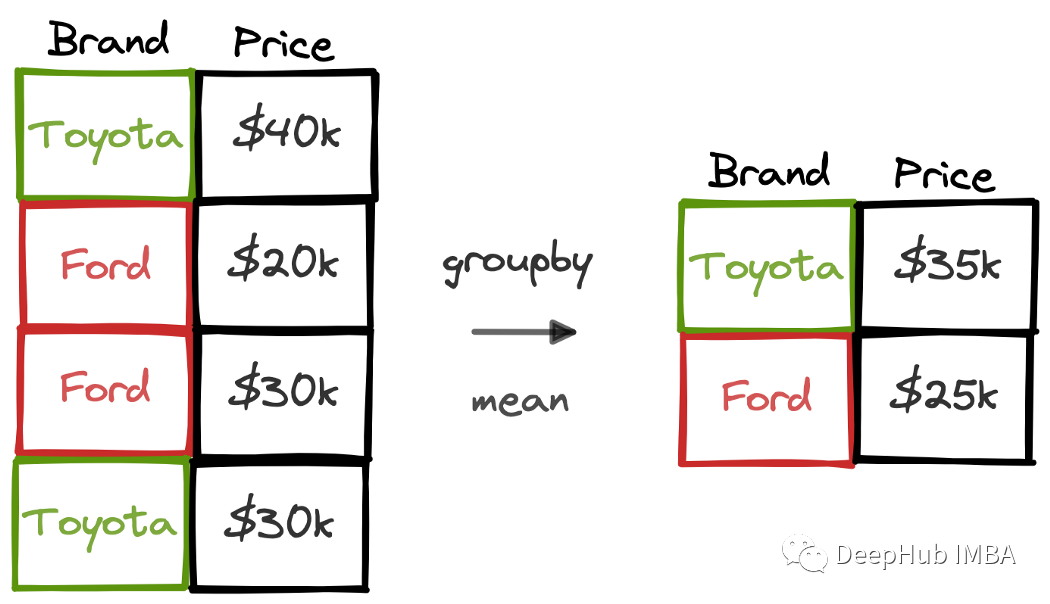
25个例子学会Pandas Groupby 操作
在本文中,我们将使用25个示例来详细介绍groupby函数的用法。这25个示例中还包含了一些不太常用但在各种任务中都能派上用场的操作。
广义线性模型(GLM)及其应用
广义线性模型[generalize linear model(GLM)]是线性模型的扩展,通过联系函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。
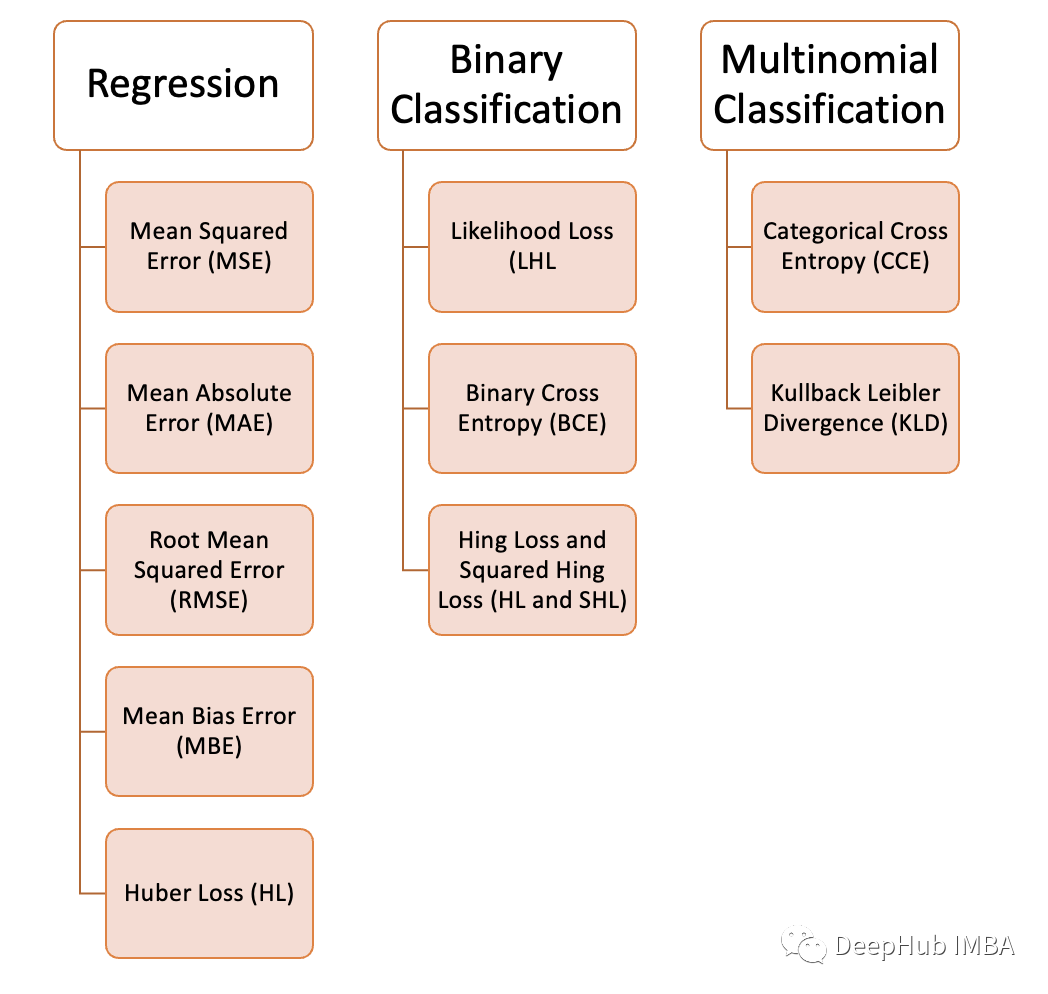
10个常用的损失函数解释以及Python代码实现
理解机器学习中的损失函数
【数据科学项目1】:构建你的第一个数据科学项目
从0到1构建你的第一个数据科学项目



