
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
你可能听说过“Ridge”、“Lasso”和“ElasticNet”这样的术语。这些技术术语背后的基本概念都是正规化。在这篇文章中我们将详细进行说明。
一般情况下,使用正则化的目的是缓解过拟合。正则化的主要好处是减轻过拟合,因为正则化模型能够很好地概括不可见的数据。正则化的基本原理是通过向我们试图最小化的损失(成本)函数添加另一个项来限制(控制)模型学习过程。
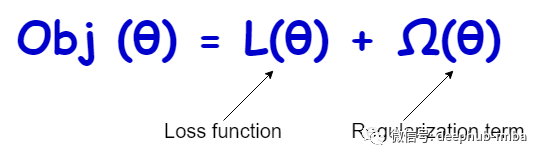
正则化项(也称为惩罚项)可以采用不同的形式,本文将介绍常见的三种形式。
预测连续值输出的线性回归模型通过最小化其损失函数来学习其系数的最佳值。同样的方法也适用于预测离散值输出的逻辑回归模型。在这两种情况下,我们都可以在模型训练阶段应用正则化。
当我们使用Scikit-learn逻辑回归模型的 LogisticRegression() 类时,有一个称为penalty的超参数来选择正则化的类型。
LogisticRegression(penalty='...')
有 4 个选项可供选择惩罚(正则化)类型。
- ‘none’ - 不应用正则化
- 'l1' - 应用 L1 正则化
- ‘l2’ - 应用 L2 正则化(默认选择)
- 'elasticnet' - 应用了 L1 和 L2 正则化
而线性回归模型的 LinearRegression() 类,没有特定的超参数来选择正则化的类型。需要使用不同的正则化类。
- 当我们将 L2 正则化应用于线性回归的损失函数时,称为Ridge回归。
- 当我们将 L1 正则化应用于线性回归的损失函数时,它被称为Lasso 回归。
- 当我们将 L1 和 L2 正则化同时应用于线性回归的损失函数时,称为Elastic Net回归。
以上所有回归类型都属于正则化回归的范畴。下面我们详细讨论每种类型。
Ridge回归
将 L2 正则化项(定义如下)应用于线性回归的损失函数:
L2 = α.Σ(系数的平方值)
Ridge回归的 Scikit-learn 类:
Ridge(alpha=...)
alpha 是控制正则化强度的超参数。它必须是一个正浮点数。默认值为 1。较大的 alpha 值意味着更强的正则化(过拟合程度降低但可能会变为欠拟合!)。较小的值意味着弱正则化(过度拟合)。我们想要构建一个既不会过拟合也不会欠拟合数据的模型。因此,我们需要为 alpha 选择一个最佳值。
当Ridge(alpha=0) 等价于由 LinearRegression() 类求解的正态线性回归。不建议将 alpha=0 与 Ridge 回归一起使用。相反,应该直接使用LinearRegression()。
Lasso 回归
将 L1 正则化项(定义如下)应用于线性回归的损失函数:
L1 = α.Σ(系数的绝对值)
Lasso 回归的 Scikit-learn 类:
Lasso(alpha=...)
该 alpha 及其定义与Ridge回归定义的 alpha 相同。默认值为 1。
注意:Lasso(alpha=0) 等价于由 LinearRegression() 类求解的正态线性回归。同样不建议使用
Elastic Net回归
同时将 L1 和 L2 正则化项应用于线性回归的损失函数。
弹性网络回归的 Scikit-learn 类:
ElasticNet(alpha=..., l1_ratio=...)
超参数 l1_ratio 定义了我们如何混合 L1 和 L2 正则化。因此,它被称为 ElasticNet 混合参数。l1_ratio 的可接受值范围是:
0 <= l1_ratio <= 1
0 < l1_ratio < 1 表示调节 L1 和 L2 项的组合。如果 l1_ratio 接近 1,则表示 L1 项占主导地位。如果 l1_ratio 接近于 0,则表示 L2 项占主导地位,所以
- l1_ratio = 0 表示没有 L1 项,只有 L2 正则化。
- l1_ratio = 1 表示没有 L2 项,只有 L1 正则化。
总结
在实际应用中有没有必要总是对线性回归模型应用正则化呢?如何判断使用哪一个呢?首先,可以尝试使用 LogisticRegression() ,如果测试 RMSE 的值较低,而训练 RMSE 的值较高,则模型可能过度拟合。然后,可以尝试应用每种类型的正则化并查看输出。还可以为超参数 alpha 和 l1_ratio 尝试不同的有效值。最后,通过查看训练集和测试集上的 RMSE 来选择一个好的模型。一个好的模型既不会过拟合也不会欠拟合数据。它应该能够在训练数据上表现良好,并且在看不见的数据(测试数据)上也能很好地泛化。
注意:除了应用正则化之外,还有其他方法可以解决过拟合问题。
作者:Rukshan Pramoditha
喜欢就关注一下吧:
 点个 在看 你最好看!********** **********
点个 在看 你最好看!********** **********