
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
距Scikit-Learn第一版发布已经有14年了,经历了24个beta版本,2021年9月它终于发布了1.0版本。Scikit-Learn已经被数千家公司、数据科学家、研究人员使用了很长一段时间,每个人都认为它是通用机器学习最广泛的框架。但是它刚刚才发布了1.0版,这听起来是不是很令人诧异。
在这篇文章中,我不想像其他许多文章那样对新特性进行分析,而是想尝试分析Scikit-Learn这个版本的目的,以及它未来的发展策略,因为1.0这个版本号对于任何软件版本来说都是很重要的,并且在sklearn这个经历了14年才发布的背景下,肯定有什么原因或者计划。
历史
先说说历史:Scikit-Learn 诞生于 2007 年,最初是作为 Google Summer of Code 项目,并在研究环境中继续开发(都是google项目看看chrome,现在都94.xx了,这就是差距)。它的目标是作为一种工具来进行数据分析,而不必关心任何特定的技术或代码。为此,它基于 Python,一种开源语言,易于使用、通用并且能够嵌入 C 代码。

Scikit-learn 作为原力,Jedi 需要用可靠高效的库工具来对抗 Imperial 的不起眼的数据,哈
处理数据的另一个大问题是用于处理的内存和计算资源,因此 SciKit-Learn 一直在努力使其算法更加高效,以便即使计算资源低的用户也可以处理数据。Scikit-learn 通过使用统计近似和低级代码 (Cython) 来做到这一点。
此外,就是SciKit-Learn 的文档,SciKit-Learn 的文档非常全面,并且包含了很多专业的知识,许多数据科学家(我自己)通过阅读 sciKit-Learn 文档来学习机器学习。它不仅仅是一个代码文档,更是一条数据科学学习路径。
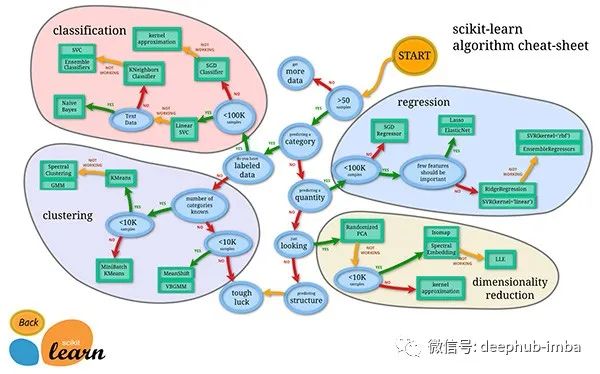
这张图想必大家一定不陌生:
1.0版本更新
现在回到1.0版的更新介绍,如果我们看到发布的亮点,我们可以看到API的变化,甚至没有一些很酷的新功能
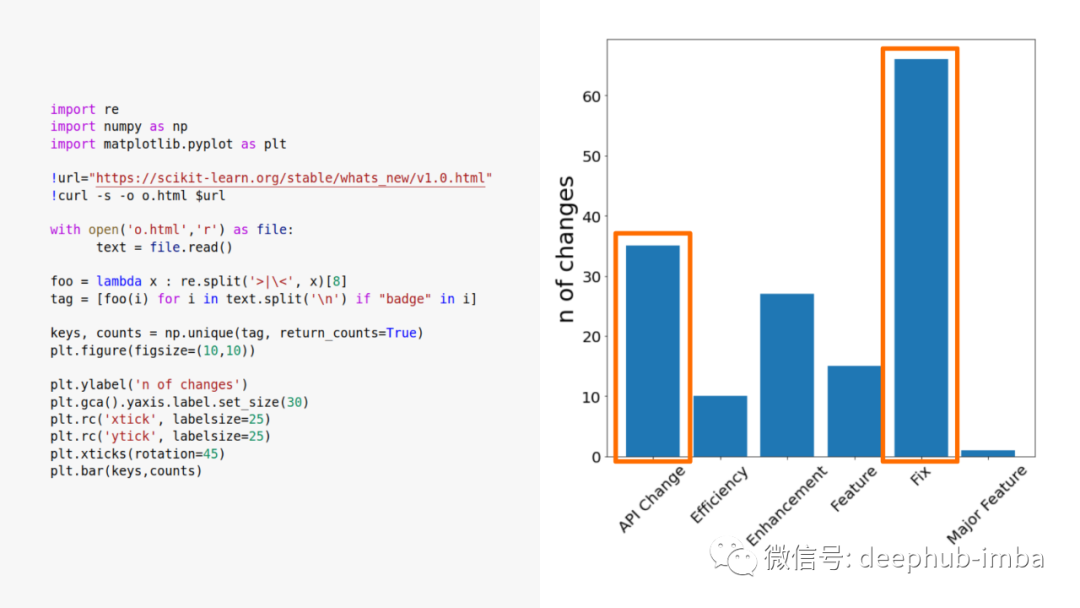
通过查看发布日志页面我们可以知道大多数标记是修复和API更改(https://scikit-learn.org/stable/whats_new/v1.0.html)。
API标准化
库接口中的一个重要模式是所有模块都倾向于可互换。例如,如果试图构建一个监督模型用于拟合、测试、预测和测量该模型准确性的函数和方法应该是可以复用的,只不过构建的监督模型(线性回归、决策树、k-means…)是独立的。
理论上来说,应该是具有相同函数的对象之间的标准接口和参数。
虽然模块可以抽象相同的参数,但在不同的模块和版本之间,预期的值却不同(例如“X 应该是 np.matrix 还是 np.array?”、“loss='ls' 或 loss= 'mse'?...”)。解决这个问题的一些亮点是:
- 参数签名:现在强制只使用关键字参数。
- 数据类型:新功能使用Pandas来解决这个问题(例如,估计器在训练时使用 pd.DataFrame 并存储 feature_names)。同时,不推荐使用 np.matrix 类型。
- 参数值:一些函数和模块具有相同的参数(loss, scaler, criterion等),但它在每个模块预期的值不同,这个问题也已经被统一了。
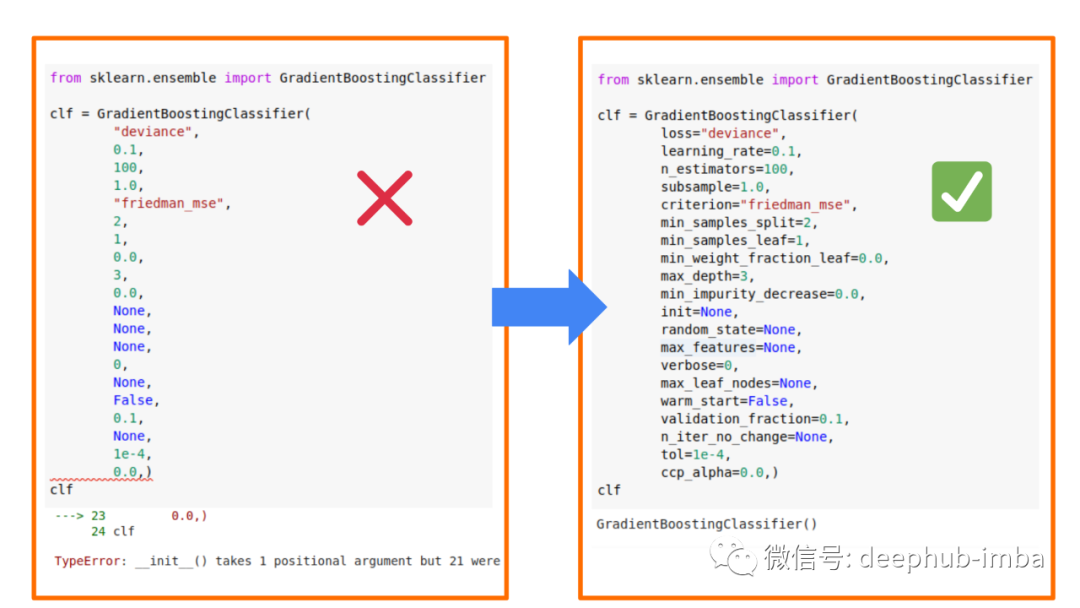
现在需要将参数值和参数名称一起传递。这是一个很好的限制,可以避免遗留的设计不良的代码带来的问题。当然这意味着以前的代码肯定需要修改的。
计算性能
当创建一个库来使用数据的思维服务于每个人时,还必须考虑到大多数人没有高级计算资源,例如只有低配置的家用笔记本电脑。这就是为什么 Scikit-Learn 一直尝试使用低级嵌入式语言 (Cython) 来提高性能(例如在 SVM 和 GBDT 算法中)。
Scikit-Learn 允许在低资源的电脑中使用机器学习。
在1.0版本中,在许多功能和模块中进行了更多的效率增强,例如:
- 预处理:(StandardScaler、KBinsDiscretizer、PolynomialFeatures)
- 评估器:(逻辑回归、邻居、聚类、……算法)
- 降维算法
而且,新功能不是性能增强,而是利用统计特性比原始模型执行得更快的新模型:
- Online One-Class SVM:使用具有随机梯度下降和核近似的 One-Class SVM 将复杂度从二次降低到线性。
- HistGradientBoostingClassifier:梯度提升实现,其中特征的值被分成样条曲线。树学习样条值而不是值本身减少基数。
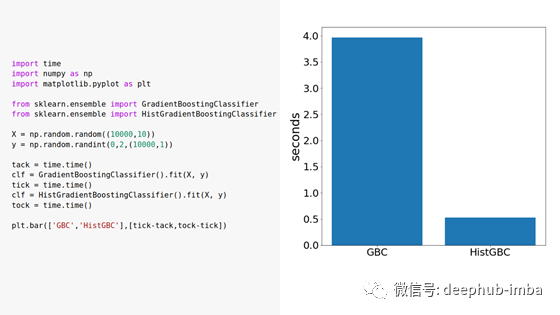
梯度提升分类器和直方图梯度提升分类器的计算时间和生成图的代码的比较。
度量
将 Scikit-Learn 视为机器学习框架是一个常见的错误,但事实是它有更多的功能。它提供了一套工具,不仅用于开发模型,还能用于度量和理解经过训练的模型的预测。
当您不仅想要创建一个预测模型,而且还想从它学到的东西中提取见解时,这一点特别重要
1.0版本带来了一些简化指标计算的新功能以及一些新指标:
- 添加用于指标和图表方法:from_estimator 和 from_predictions。
- 新指标:pinball_loss 和 tweedie_score。
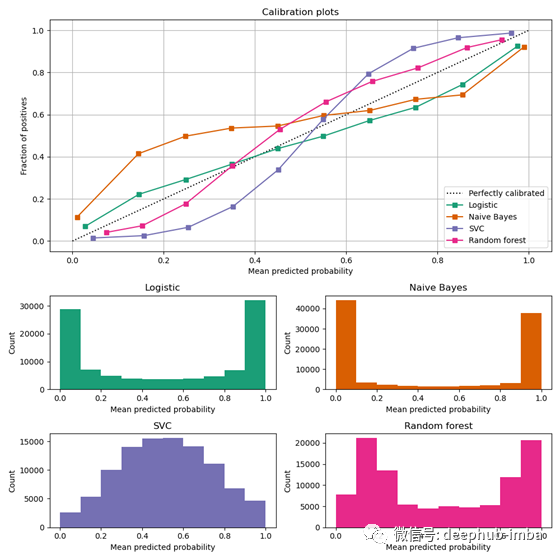
- 用于显示结果的新图 CalibrationDisplay。
社区
Scikit-Learn一直试图成为一个将机器学习知识带给人们,并定义一些标准的完整环境:
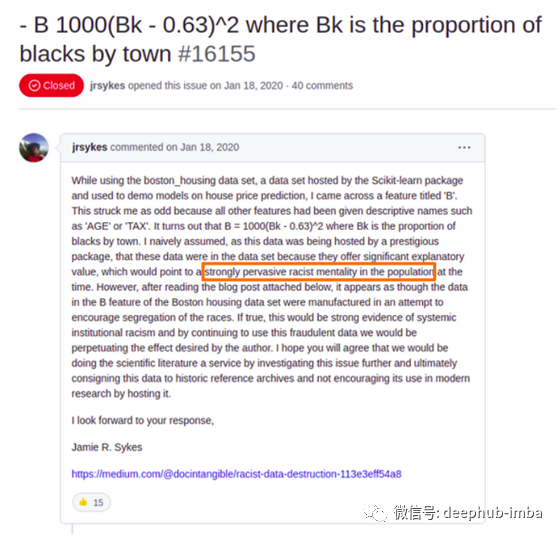
在 2100 多个合并请求中,大约有 800 个是对文档的改进。
文档中的这些更新主要是为了提高用户资源的质量,并满足用户的更多需求。这种需求也可能出于伦理道德原因,例如删除波士顿数据集
总结
在本文中,我们介绍了Scikit-Learn 1.0版的主要特性,并试图从库的历史背景来解释它们的重要性。
这可能听起来很奇怪,第一个主要版本主要是修复和API的变化,而不是新的功能,但是,理解了Scikit-Learn的目标,我们已经看到它的目的一直是
定义一个机器学习的标准,把工具独立地带给大多数人,无论他们是研究人员,雇主,学生或只是作为一个爱好。
deephub译者注
1、Scikit-Learn 1.0作为第一个主要版本其实是告诉大家,目前的API已经固定下来了大家可以放心使用了,以后的小版本更新应该不会再有参数方向的大改动了,这就意味着除大版本更新外,API的修改不会那么频繁了。但是它使用pandas我觉得效率还是不高(因为df读取数据时并不快),这个还要测试论证下。
2、就像本篇文章说的那样,Scikit-Learn的一个最主要目的(野心)是统一机器学习的流程(数据准备,训练,验证,发布,上线),要做成像pandas和numpy那样成为机器学习中不可缺少的一部分,并且抽象出了一些方法来实现这个目的。我个人觉得还是很好的,因为这样大家关注的焦点就在模型和数据处理等应该做的事情,而不是工程方面的问题。其实目前我用到最多的还是他的指标库,auc,roc,f1这种指标直接调用十分的方便。
3、文章说的另外一个我非常认同观点是SciKit-Learn 的文档非常全面,绝对可以提供很多帮助,并且成为入门的好帮手。
总之Scikit-Learn 真的很好用,第一个正式版已经发布了,你一定不要错过他。
作者:DelgadoPanadero