
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
Vision transformer (ViT) 在许多计算机视觉任务中取得了优于经典的卷积架构的令人瞩目的性能。这时一个问题出现了:ViTs 令人印象深刻的性能是由于其强大的Transformers架构和注意力机制带来的,还是有其他一些因素使 ViTs 具有优势?
在目前正ICLR 2022 双盲评审中的论文 Patches Are All You Need 中,一个研究团队提出了 ConvMixer,这是一个极其简单的模型(大约 6 行的 PyTorch 代码),旨在 证明 ViT 性能主要归因于使用Patchs作为输入表示的假设。研究表明,ConvMixer 可以胜过 ViT、MLP-Mixer 和经典视觉模型。

特斯拉人工智能高级总监 Andrej Karpathy 在推特上写道:“我被新的 ConvMixer 架构震撼了。”
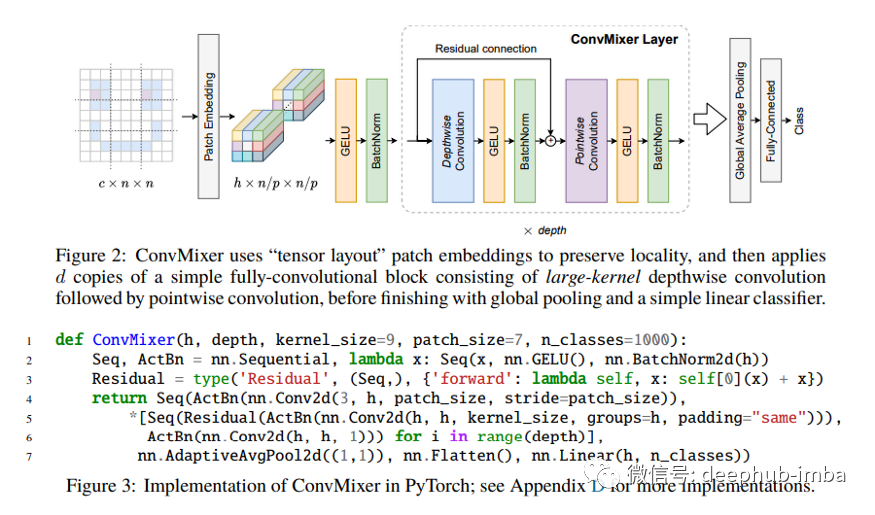
ConvMixer 包含一个patch嵌入层,然后是一个简单的全卷积块的重复应用。ConvMixer 块本身由Depthwise(DW)卷积与Pointwise(PW)卷积组成(这两种卷积合起来被称作Depthwise Separable Convolution,可以参考Google的Xception,这个是很老的架构了),每个卷积之后是一个激活和激活后 BN过程。
顾名思义,ConvMixer 背后的总体思路是混合。研究人员使用DW)卷积来混合空间位置,使用PW卷积来混合通道位置。他们还使用具有非常规的大内核卷积来混合遥远的空间位置,使他们能够观察到patch表示的效果,而不是传统的金字塔形卷积网络设计。(还记得我们发的上一篇论文解释吗,VIT从底层就看到了全局特征)
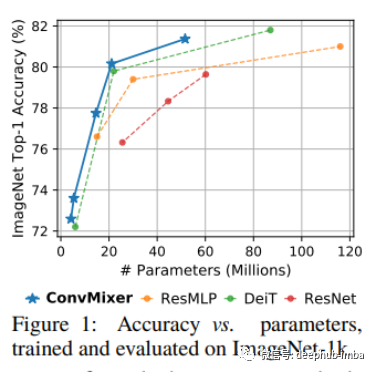
在他们的实证研究中,该团队在没有任何预训练或额外数据的情况下在 ImageNet-1k 分类上评估了 ConvMixer。他们在 timm 中添加了 ConvMixer,除了默认的 timm 增强之外,还使用了 RandAugment、mixup、CutMix、随机擦除和梯度裁剪。(timm真的是个好库,CVer必备)
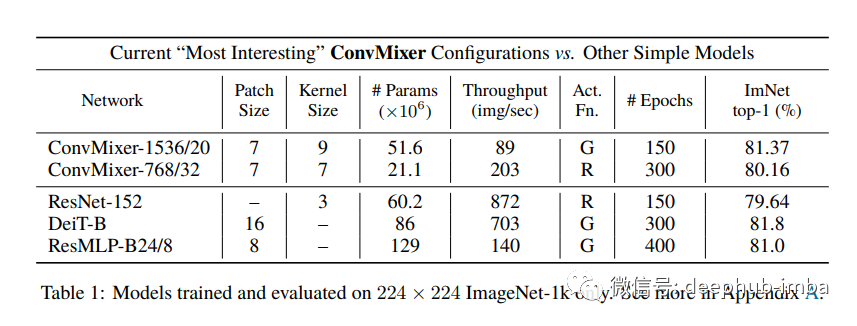
在实验中,具有 52M 参数的 ConvMixer-1536/20 在 ImageNet 上达到了 81.4% 的 top-1 准确率,具有 21M 参数的 ConvMixer-768/32 达到了 80.2%。此外,尽管 ConvMixer 极其简单,但其性能优于 ResNet 等“标准”计算机视觉模型以及相应的vision transformer和 MLP-Mixer 变体。
总体而言,结果表明Patch表示本身可能是对 ViT 的出色性能的最大贡献。该团队相信他们的工作可以为未来的高级架构提供一个强大的“基于卷积并且基于Patch”的基线。
ConvMixer 代码可在项目的 Github 上找到。https://github.com/tmp-iclr/convmixer
Patches Are All You Need? 论文可以在OpenReview看到 https://openreview.net/forum?id=TVHS5Y4dNvM
作者:Hecate He
喜欢就关注一下吧:
 点个 在看 你最好看!********** **********
点个 在看 你最好看!********** **********