
在这篇论文中,作者提出了一种优化的方法来找到给定模型的通用对抗样本(首先在 Moosavi-Desfooli 等人 [1] 中引入)。作者还提出了一种低成本算法来增强模型对此类扰动的鲁棒性。
Universal Adversarial Perturbations (UAP) 很“便宜” - 单个噪声可用于导致模型错误标记大量图像。(与基于每个图像生成扰动的通常攻击不同。但这些更有效)。论文还发现 UAP 可以跨不同模型,因此它们也可以用于黑盒攻击设置,因此研究它们很重要。
UAP vs Adversarial Perturbation:为了攻击给定的模型,在一个常见的对抗性攻击案例中,为每个图像找到一个唯一的增量,以便模型对其进行错误分类。在 UAP 案例中,目标是可以找到一个增量并将其用于所有图像。

[1] 中的 UAP 计算:UAP 在 [1] 中首次引入。这是一种简单的技术,但是没有收敛保证。作者通过遍历图像并不断更新 delta,直到 ξ% 的图像被错误分类。并且每次迭代中的更新都是使用 DeepFool [2] 计算的。攻击公式和算法如下所示。


对抗性训练:为了使模型对对抗性攻击具有鲁棒性,Madry 等人提出了对抗性训练,训练过程涉及每次迭代,生成对抗性示例,然后计算它们的损失,更新该损失的权重。公式如下。(Z是扰动图像)


下面总结以下这篇论文的贡献。
1、改进 UAP 计算:在论文中作者简化了找到使损失最大化的增量的公式。这样就可以使用优化器更新 δ。 由于上面的损失是无限的,作者提出了这种损失的剪辑版本。这个公式目标是寻找一种通用扰动,使训练损失最大化,从而迫使图像进入错误的类别。

论文提出的用于寻找 UAP 的公式
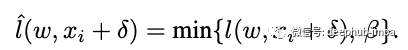
裁剪损失, Beta 是一个超参数。
只要有了可以计算的损失,优化问题就可以通过随机梯度法来解决,得到损失梯度wrt δ,比如说g,将δ更新为δ+l.r.*g,然后将δ投影回εl_p。
2、改进的 UAP 对抗的训练:作者还建议为给定批次找到 UAP,并使用扰动输入 (x_i + δ) 训练模型
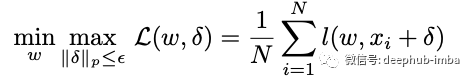
作者还探索了一个在对抗训练时对 δ与权重同时进行反向传播的快速训练案例,并且证明了它提供了足够好的性能。可以在下图中看到两种 UAP 对抗训练风格的算法。

对抗训练算法

快速对抗训练算法
结果
在 WideResnet-32 架构的 CIFAR-10 数据集上,ε = 8,SGD 扰动为 42.56%,ADAM 为 13.30%,PGD 为 13.79%。WRN 的清洁测试准确率为 95.2%。
在下面的集合中,可以从正常训练和鲁棒性训练的模型中看到 CIFAR-10 的 UAP 的样子。鲁棒性模型似乎比正常模型具有更低频的UAP。

WRN 32-10,在不同优化器上进行 160 次迭代后的 UAP。

400 次迭代 :UAP 是 CIFAR-10 鲁棒性模型:使用 FGSM 或 PGD 进行对抗训练,使用 FGSM (uFGSM) 或 SGD (uSGD) 进行通用对抗训练。
攻击公式比以前的方法更成功,我们可以从左下方的表格中看到。论文中提出的对抗性训练对 UAP 扰动更加鲁棒,并且具有更好的泛化行为。有趣的是最普遍的对抗性训练方法(由 PGD 表示)对 UAP 并不十分鲁棒。
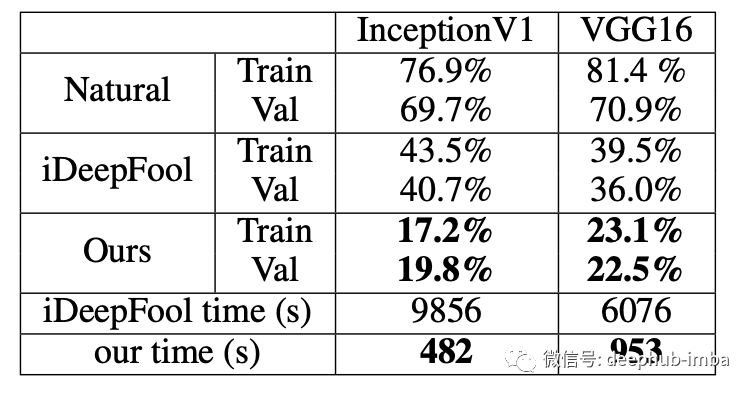
正常训练模型在 ImageNet 的 UAP 攻击测试图像上的测试准确度
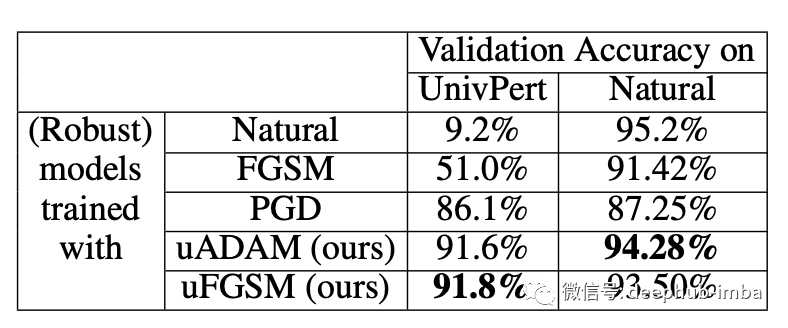
对抗性训练模型在 CIFAR-10 UAP 攻击测试图像上的测试准确度。

ImageNet 的 UAP 攻击测试图像的准确率分别为 3.9%、42%、28.3%。
总的来说是一篇有趣的论文。论文介绍的 UAP 计算公式计算效率高,扰动更有效。这种训练方法似乎比通常的对抗性训练具有更好的测试性能。
论文信息:
Paper: Universal Adversarial Training
Link: https://ojs.aaai.org/index.php/AAAI/article/view/6017/5873
Authors: Ali Shafahi, Mahyar Najibi, Zheng Xu, John Dickerson, Larry S. Davis, Tom Goldstein
Tags: Adversarial attack, Universal attack, White-box attackCode: -Misc. info: Accepted to AAAI’20
本文引用:
[1] — Moosavi-Dezfooli, Seyed-Mohsen, et al. “Universal adversarial perturbations.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[2] — Moosavi-Dezfooli, Seyed-Mohsen, Alhussein Fawzi, and Pascal Frossard. “Deepfool: a simple and accurate method to fool deep neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
作者:Gowthami Somepalli