
星际争霸 II 是暴雪开发的一款真正的战略游戏,它是一个挑战,因为它从机器学习的角度展示了一些有趣的属性:实时、部分可观察性以及广阔的行动和观察空间。掌握游戏需要时间策略规划,实时控制宏观和微观层面,具有实时反击对手的特点。
在本文中,我们将介绍 StarCarft II Unplugged 论文 [1],这是一个基准,涵盖了参考 AlphaStar 论文 [2] 的算法和代理。提出的主要新颖性包括用于训练的数据集、评估指标和基准代理以来自 AlphaStar 的参考代理。在非常广泛的基础上,这项工作基于从人类回放数据集中学习,并提出了离线强化学习策略评估方法和一些在线策略改进。
从离线 RL 的角度来看,该论文重点介绍了星际争霸的属性,这些属性可能对这一挑战很有趣。

- 数据源,需要确保数据集不会偏离 RL 代理生成的数据集。来自离线强化学习的挑战之一是来自对来自数据集 [3] 的游戏策略集的多样性和丰富性的保证,在论文中称为覆盖率。参考论文 [3] 也将这一挑战称为确保状态空间的高回报区域的存在
- 大型、分层和结构化的行动空间。为了正确执行游戏玩法,代理必须选择动作和单元以应用该动作,并控制地图以执行动作。此外每一步有 10e26 个可能的动作。从覆盖率的角度来看,这代表了以确保游戏策略多样性的序列形式选择足够的分层动作的挑战。
- 随机环境,在随机环境中下一个代理的状态并不总是根据其当前状态和动作来确定,这意味着采取动作并不能保证代理最终会处于其预期的状态。这些环境可能需要更多的轨迹来获得较高的状态动作覆盖率。
- 部分可观察性,由于战争迷雾,除非它探索环境,否则代理不知道对手在做什么。这种探索可能需要在游戏后期使用此信息,这可能意味着使用内存来确保覆盖范围。
离线强化学习基础

一般来说,强化学习可以定义为机器学习的一个子领域,它基于通过与具有反馈奖励标志的环境的交互进行学习,总体目标是学习最大化该奖励的策略 π。在这个框架下,关于学习方法存在不同类型的分类:在线 RL 中,代理在每个时间步与环境交互,离线RL 中,代理的经验被存储到更新策略的重放缓冲区 D 中。
从强化学习中考虑到的关于研究过程的另一个关键概念是,通过估计来自状态 s 或状态动作对的预期回报的价值函数来学习此策略 π 的过程称为策略评估。然后可以在策略改进过程中使用价值函数来增加具有更高价值的行动的概率。另外就是反复进行策略评估和策略改进的过程是强化学习算法方法的核心,这个过程一般被称为策略迭代。
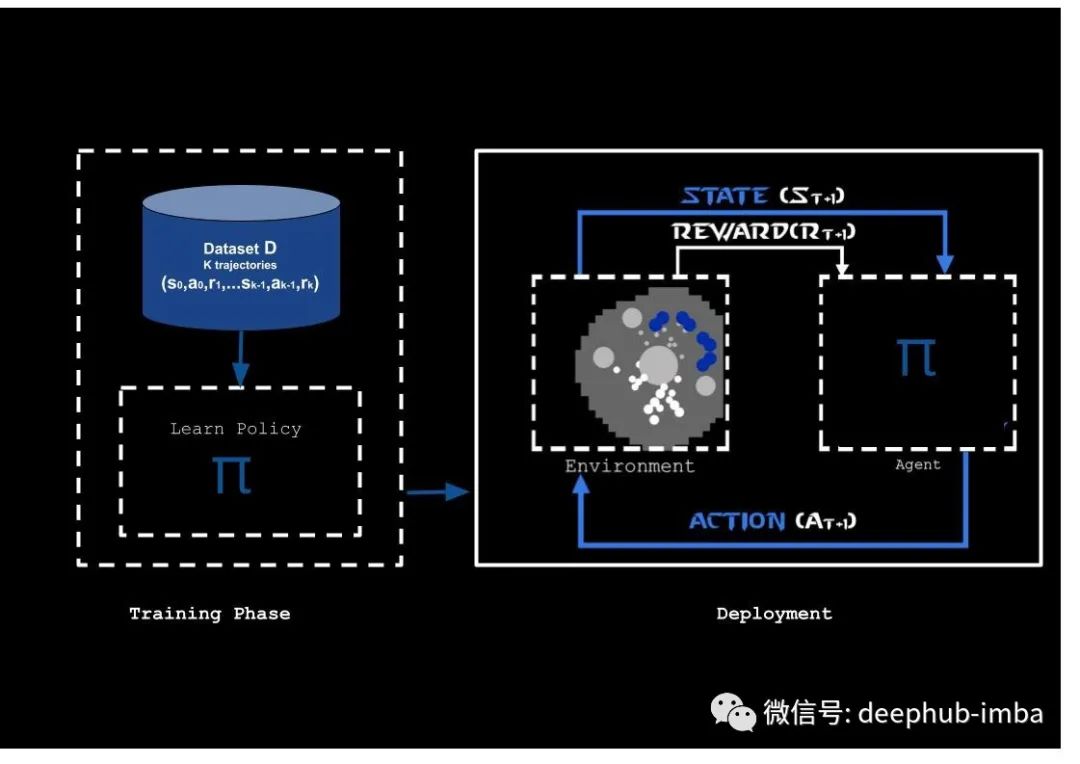
图 1:离线 RL 的主要思想是使用在训练期间未更改的数据集 D 来训练策略。在训练阶段,数据集用于训练策略,而不与环境进行任何交互。在部署阶段,学习到的策略会在环境中进行测试。这个循环实际上可以用来训练新的策略。这个图像是从参考 [2] 到星际争霸 II 环境的改编
离线RL 的原理来自数据驱动方法的监督学习、数据集的使用以及使用遵循 MDP 结构的收集数据集来训练策略的原则。但是代理不再具有与环境交互并使用学习策略收集其他转换的能力。相反该算法提供了一个静态的转换数据集,可以称为训练数据集。
从在线RL中删除强化学习训练循环降低了对星际争霸进行试验的计算需求,使其更容易被研究社区[1]访问。因此离线 RL 的主要挑战之一是希望学习到的策略比数据集 D 中看到的行为表现更好,也就是说在实践中能够执行一系列与训练集中出现的不同的动作,这些动作比从数据集 D 中观察到的行为模式有更好的表现(类似观看replay的总结)。这篇论文中表明:即使算法不会通过与环境交互来收集更多数据,也可以在环境中运行学习的策略来衡量它们的执行情况,这种评估可能对超参数调整有用。论文认为创建成功代理首先先要制定良好的训练策略。
离线强化学习领域也可以使用在线和离线强化学习的不同方法来学习策略。在这种特殊情况下,主要关注的是行为值估计的算法(计算价值函数)
数据集

星际争霸数据集的构建得益于对公开可用的 2000 万个星际争霸 II 游戏回访记录的筛选。数据分布呈正偏态分布,并考虑到博弈因素
- 140万次的游戏,包括3500次MMR,排名前22%的玩家拥有280万次游戏回访,代表着他们总计玩了30多年的游戏。
- 考虑了游戏的平均时间(11分钟)
- 筛选只包含动作的帧,将数据长度削减12倍。
- 在基准测试中给出的一些算法是用另一个MMR > 6200的高质量数据集和仅获胜的游戏数据集进行的微调。
注意:并非所有时间长度的游戏回放都包含在数据集中,因为它们通过玩家采取行动的步骤缩短了轨迹。这意味着,从工程角度和 API 来看,所有没有动作的轨迹(pysc2 API 中的 NO_OP)都已删除。
暴雪发布的游戏回访包含 500 万个视频格式的重播。数据集将视频文件转换为一组包含 K 个连续时间步长(轨迹)序列的 rollout,组装在一个 mini batch 为M的独立rollout 中。rollout可以理解为连续轨迹的长度
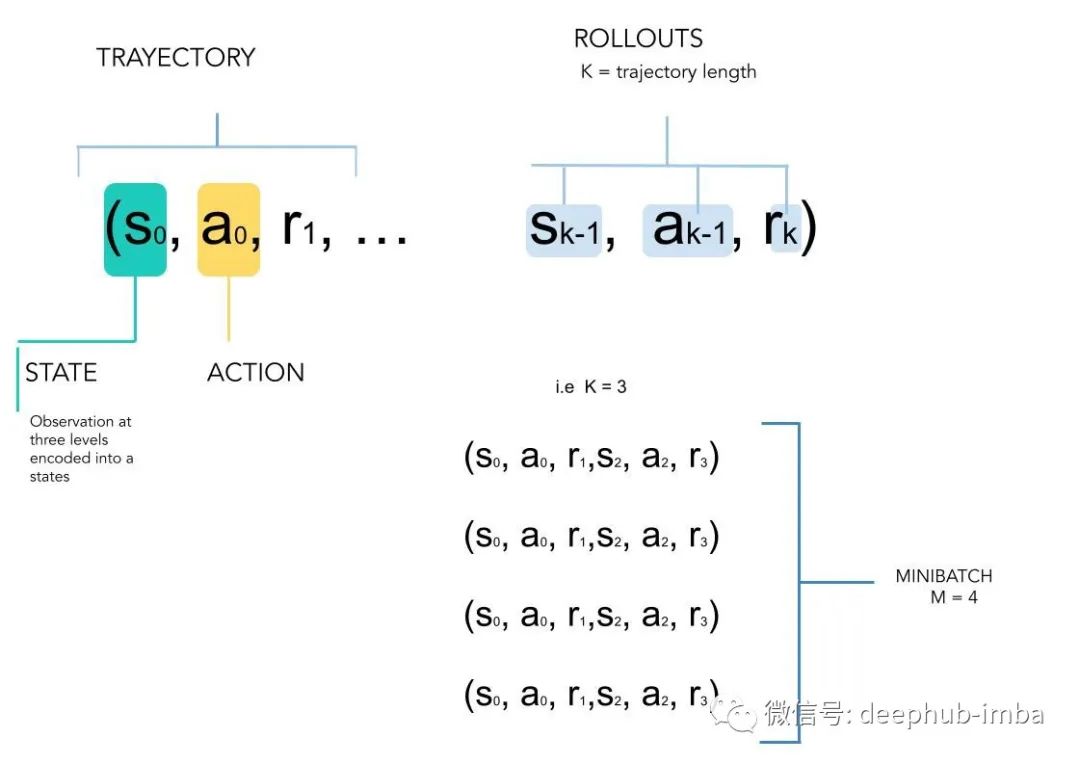
图 2. 数据集是一组称为 rollouts 的状态动作元组,解释为在 M 个独立 rollout 的小批量中组装的 K 个连续时间步长的序列。这遵循其他离线任务(例如 DL4R)给出的结构。如果选择 K = 1 ,得到的是一个轨迹。如果选择更扩展的 K,将不得不考虑更长的轨迹。一个 minibatch M 考虑了独立的 rollouts 。minibatch 大小 M 和 rollout K 大小影响最终的行为性能。
观察与行动空间

StarCraft 游戏的复杂性导致了观察/动作空间的分层分类,其中包括有关世界、单位和标量输入以及 StrarCraft II 单位可以执行的能力的信息,通过 pysc2 API 进行编码。在下面找到观察和行动空间的摘要,包括 GameHuman 屏幕截图和对这些观察和行动的代理解释,主要是为了解决
游戏的代理如何看待世界?代理如何执行其决策?
1、观察
观察空间可分为三个主要部分,总体构成数据集 D 中轨迹的状态。这些组件在上面进行了描述并显示在图 4 中。

world:整个游戏的世界是由128x128 张量数据结构组成,包括地图和小地图分析以及游戏基本控制问题,还有地图阴影信息和玩家对该地图的控制区域。这将作为架构输出中的特征平面

Units :代理观察到的单位列表。它包含代理的所有单位以及在代理的视野内和对手建筑物的最后已知状态的对手的单位。对于每个单元,观察是一个大小为 43 的向量,其中包含游戏界面中可用的所有信息。这或许可以理解为对博弈的微观管理观察。

Scalars:一维向量形式的全局输入,它包括资源(矿产和瓦斯)、对手信息、工人信息和单位成本。这或许可以理解为对博弈的宏观管理观察。
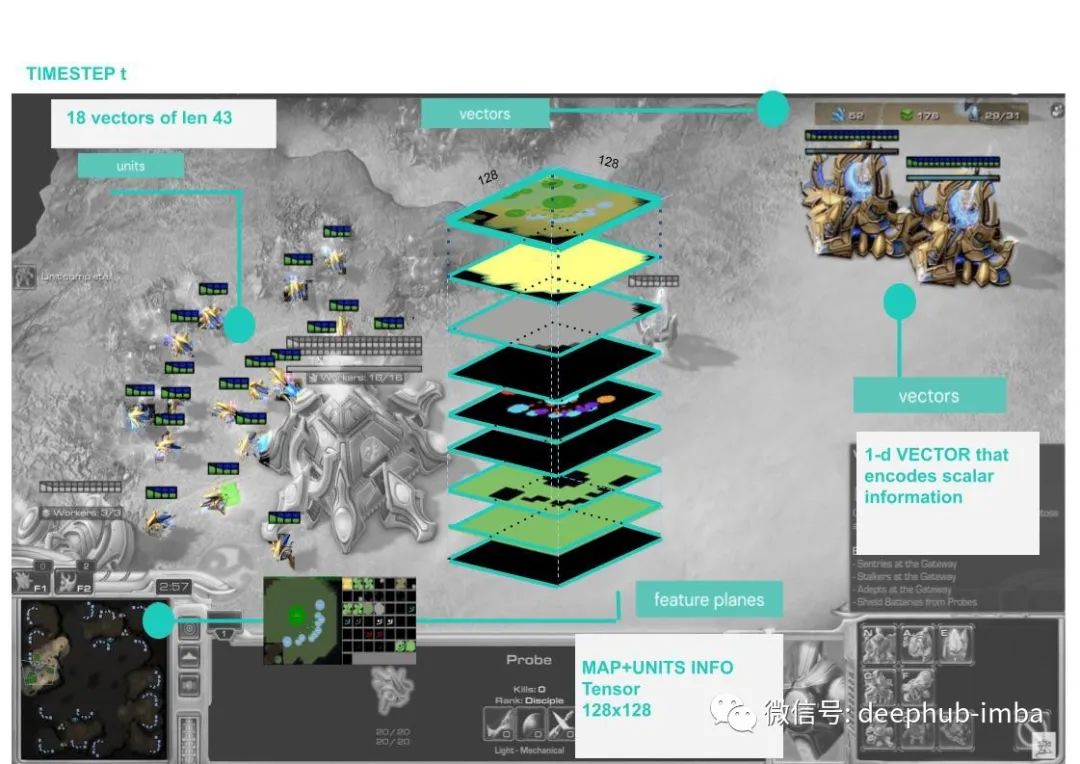
图 4。此图的目的是显示代理如何看待或解释 Starcarft 。基于 API 如何处理游戏界面的时间步 t 观察示例。该图显示了三个层次结构:一个 128 x 128 像素的整体全球世界张量,其中包括在输入特征计划中调用的小地图信息。以列表形式嵌套的单元的信息,该列表可以从 43 扩展到 512 。标量输入、单位特征和单位参数输入是游戏界面中的全局信息。特征图图已使用 Simple64 捕获图进行了简化,但提供了代理如何在 ScreenPlay 中查看 Nexus 和探针的概述。
2、动作
动作结合了构成游戏一部分的 3 个标准动作:单位选择(谁应该做某事)、能力选择(该单位会做什么)和目标选择(如果该动作对谁产生影响)。每个原始动作被细分为最多 7 个参数,这些参数依次执行,并且 这些参数不是相互独立的。一旦选择了动作并且选择了它的能力,其余的参数将依次进行计算。
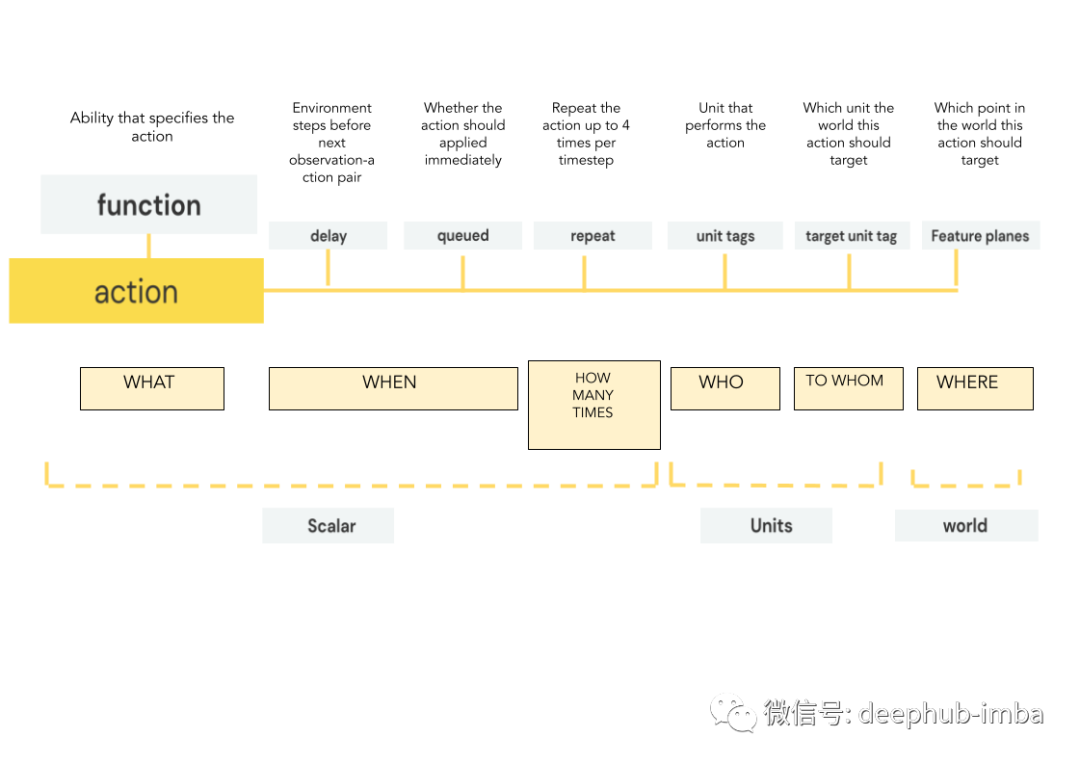
图 5. StarCraft II AP (pysc2)I 中的每个动作都通过一个由具有 7 个参数的函数表示的动作进行编码。每个参数都解决了有关特定操作的问题,例如应该在何时何地执行该操作。这些参数在函数之后按顺序计算。
在下面找到一个动作空间示例,其中选定的狂热者移动到给定点,更多的狂热者在兵营中接受训练。
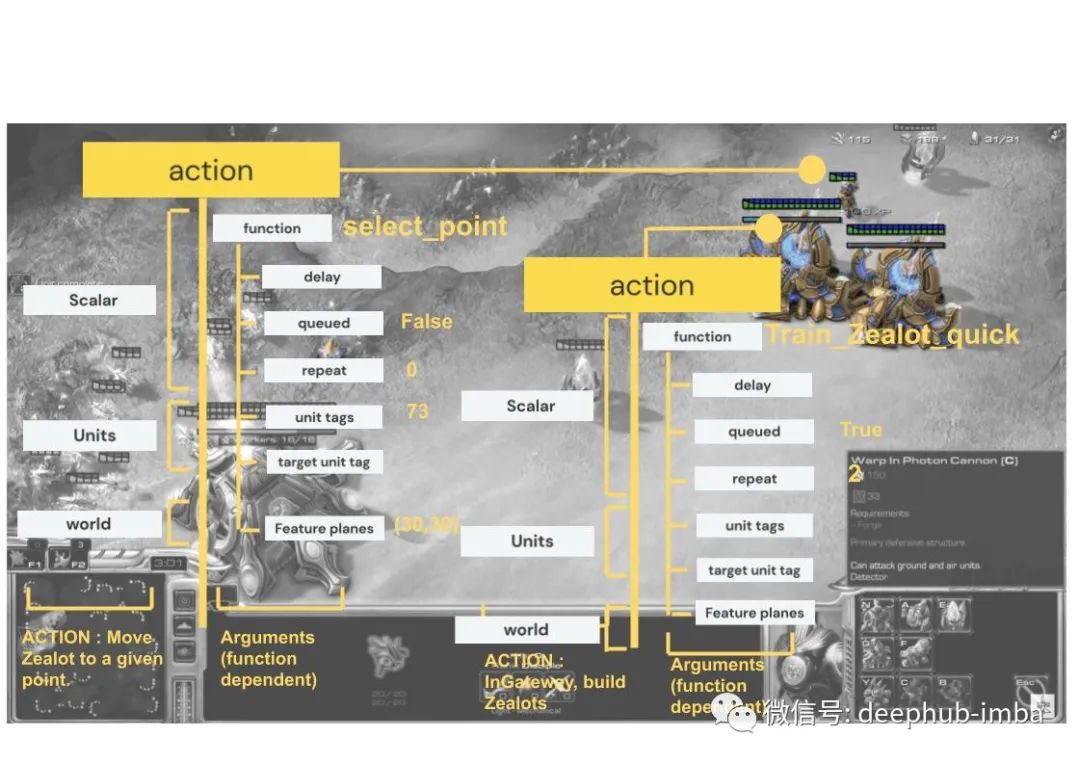
图 6..复现动作的可视化展示,将狂热者移动到地图中的给定位置。动作空间被划分为一般输出 ,解决应该做什么的问题。单位告诉我们谁应该这样做,应该在哪里做。
神经网络架构

论文的神经网络架构与 AlphaStar 不同:AlphaStar 代理使用 LSTM 模块,而 Unplugged 论文表明,移除此内存模块会带来更好的性能。基于 LSTM 的架构的胜率达到 70%,而无记忆代理对抗非常难的机器人的胜率达到 84%。
正如我们之前在观察和操作部分看到的,Pysc2[4] API 提供了不同类型的观察数据,这些观察被编码为三个部分。前一部分描述了整体观察以及与星际争霸游戏玩法的关联,现在将关注如何通过神经网络架构处理这些输入:
输入分为 3 个级别,这些级别都是独立处理并在某个”点“进行交互:向量是一维向量,用于编码有关游戏的全局标量值。单位包含代理观察到的单位列表,包括专有的和来自对手的:每个单位都包含一个大小为 43 的向量。和特征图,编码世界信息的 128x128 张量。所有这些信息都由 API 提供的。
Modules :就是学习的模块。它涉及不同的神经网络架构,例如 MLP(多层感知器)、ConvNets 或 Transformers。
Fixed Operations:以有意义的方式处理操作的信息的,可以帮助其他可训练模块或输入信息到神经网络体系结构的另一部分
Outputs:使用logit操作计算输出的概率分布以匹配函数参数。
Actions:具有7个参数的分层动作集,响应一个整体函数
总体体系结构,请关注我们的公众号,查看视频
总体体系结构。从下到上阅读:3个层次的观察结果——特征平面、单位和向量——被处理成可训练的模块——并执行不同的固定操作,产生动作。这些操作按顺序执行,从左到右。为了执行操作,引入了一个logit模块来对所选操作的分类分布给出响应。
最后,通过不同的代理集和算法方法计算出神经网络的权值Ө。
代理与评价指标
这项工作展示了 6 个具有 3 个不同一般类别的新代理,并与来自 AlphaStar 代理进行了比较,并在策略改进阶段提供了一些经验见解。原始 AlphaStar 论文与这项工作的参考代理之间的主要区别是使用星际争霸 II 的所有三个种族比赛和来自高于 3500 的 MMR 的重播来进行训练
传统离线 RL 方法的使用一直在探索奖励来执行策略改进,这里每个策略改进策略都取决于它们的计算方法。通过一组更好的回放进行了微调,再加上 MuZero Supervised 的介绍,最终胜过所有具有 MCTS 的代理。在表格上方找到描述具有评估指标的代理的性能。
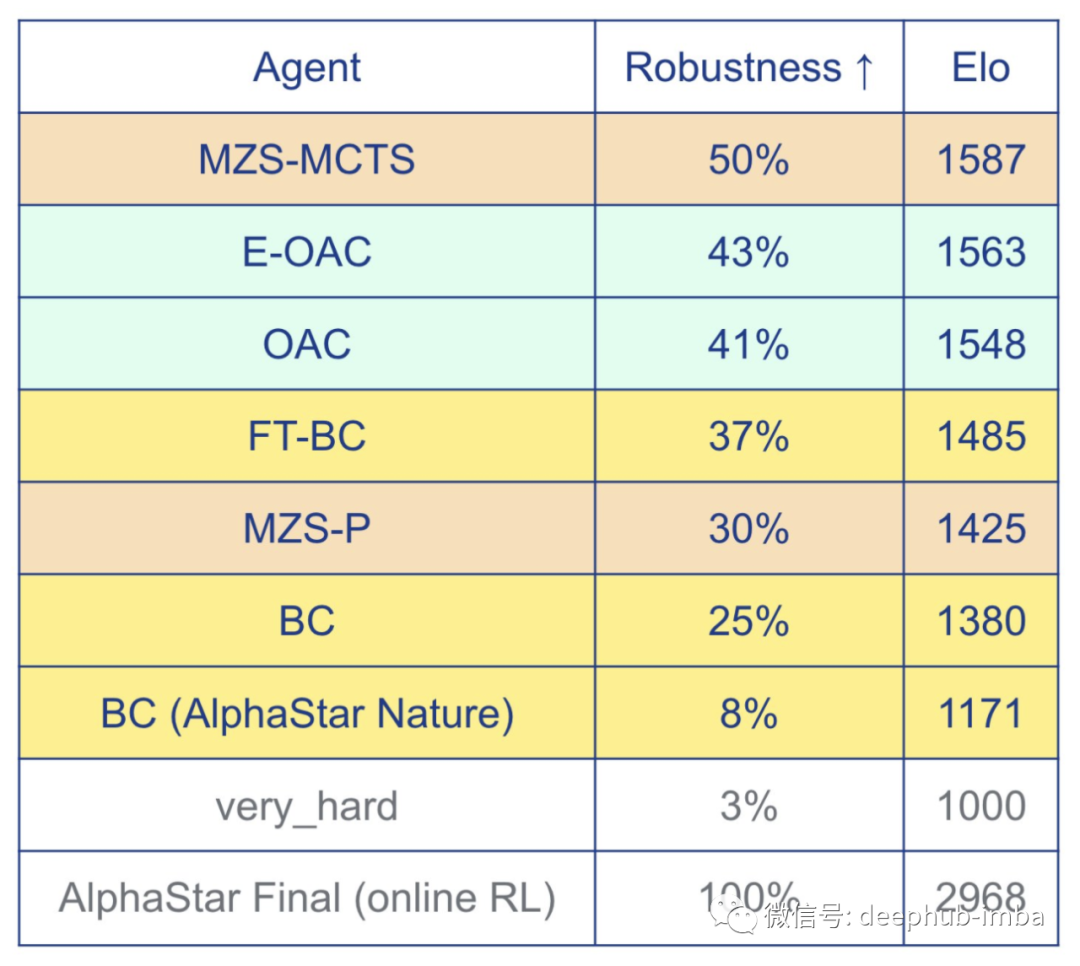
图 7. 论文作者在 Neurips2021 的 DRL 研讨会上展示的表格。具有 3 个不同类别的代理性能。黄色:显示三个采用行为克隆方法的代理,来自 AlphaStar 和模仿 (BC) 以及价值函数方法 (FT-BC)。浅绿色是在他们的离线 (OAC) 和E-OAC形式的方法。橙色显示Mu-zero代理。
1、所有这些方法有什么区别?
代理之间的概念差异在于很大程度上基于从人类回放中学习,其中最后一次迭代 FT-BC 由价值函数计算 Vπ 和使用MMR > 6200一组回放进行微调 。另外第一个算法用作其余算法的基线,因为神经网络权重 θ 用于 actorcritic 和 MuZero 方法,所以来自数据 μ 的 BC 策略计算将为其余代理的初始化。
2、Sampled Muzero 和 MuZero Unplugged:使用在线设置改进离线 RL
这项工作中提出的两种最具创新性的方法来自两部不同论文,包括了一些经验发现和教训:
- Sampled MuZero 是 MuZero 算法的扩展,它能够通过使用动作采样在具有复杂动作空间的域中学习进行规划 [5],在采样动作的子集上进行策略迭代。
- MuZero Unplugged ,通过从数据中学习(离线)和在与环境交互(在线)时使用价值改进算子(例如 MCTS)来跟踪离线 RL 优化。
3、评估指标
对于代理基准测试,有两个主要指标用于评估代理相对于其他代理的好坏程度:鲁棒性和 Elo 。游戏的结果由代理 p ( player ) 相对于其他参考代理在所有比赛中获胜的概率来定义。
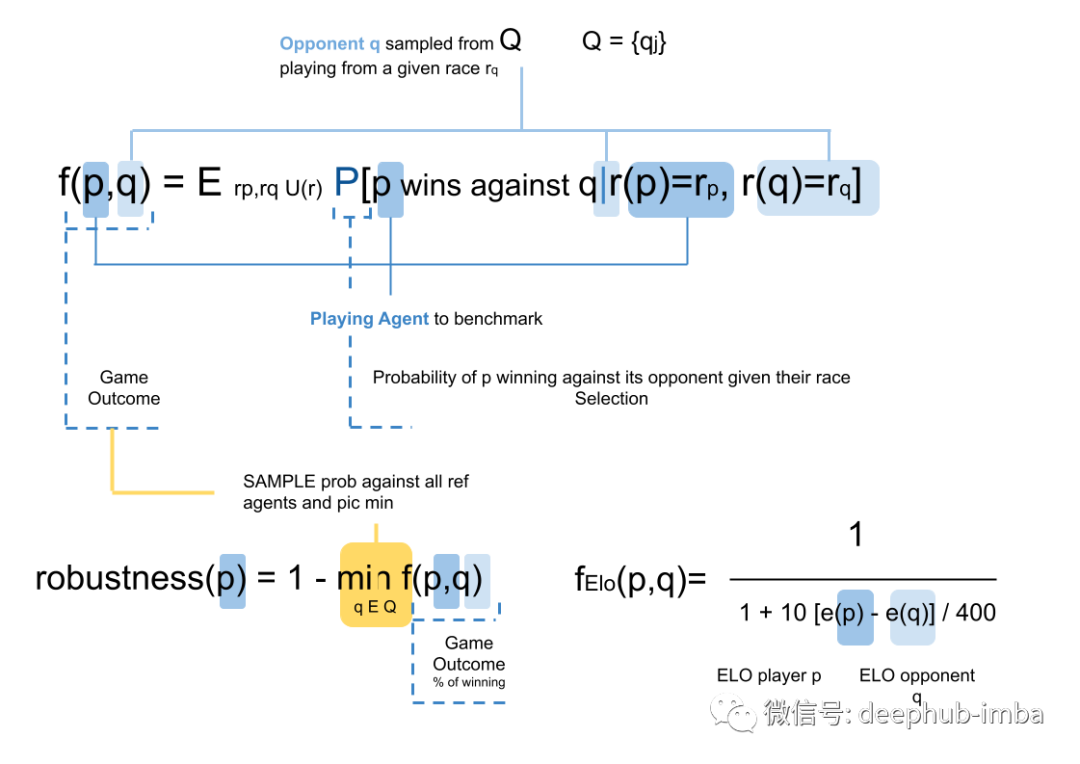
对于评估指标,首先计算代理 p 通过在均匀采样的地图和起始位置上进行匹配来战胜所有参考代理的概率。然后代理 p 与所有参考代理 q 对抗以计算鲁棒性。还有一种计算玩家ELO的系统。鲁棒性指标旨在以最佳对手为基准,遵循向量认为代理 p 更鲁棒,因为它有更高的概率战胜最强的对手。
最后总结
本文包含了太多的术语,可能翻译的不太好,我自己也认为本篇文章不会有太多的阅读。但是我还是非常兴奋的将它发出来,因为我觉得这篇文章介绍的理念才是真正的针对于我们世界或者是复现人类认知的强化学习,本论文可以将AlphaStar进行了扩展或者说更好的补充解释,绝对值得详细阅读。
对比以前被那些外行自媒体吹捧的 :几千APM微操训练甩飞龙的,这篇文章和AlphaStar就是对其智商的完全碾压,根本就不再一个认知的层级(在电脑本应该比人类强的领域训练了一个模型战胜了人类有什么意思,更何况电脑还作弊了)。如果玩过星际2可以想想下面情景,你还在家憋枪兵,对面的大和都飞过来了,这是一种什么体验。微操固然重要,但是星际2是一个大局观的游戏,这个例子可能不太恰当,但是想想二战的波兰骑兵砍坦克,骑兵的微操再强能够怎样,坦克需要微操吗,A过去就完了。
最后StarCraft II Unplugged已经发布在openreview,对星际和强化学习感兴趣的强烈推荐阅读: